前兩天跟各位介紹了DAE以及實作,而今天我們來分享最後一個Autoencoder的變體—Variational Autoencoder,那我們廢話不多說,正文開始!
變分自編碼器 (Variational Autoencoder,VAE)是Autoencoder的一個變體,它結合了自編碼器(Autoencoder)和變分推斷(Variational Inference)的概念,用於學習和生成複雜的圖形,特別是在無監督學習和生成模型的任務中。
雖然與Autoencoder的模型有關,但是在目標和數學計算有很大的差別,VAE屬於概率生成模型(Probabilistic Generative Model),具有編碼器跟解碼器。編碼器可將輸入變量映射到與變分分布的參數相對應的潛在空間(Latent Space),這樣便可以產生多個遵循同一分布的不同樣本。而解碼器的功能基本相反,是從潛在空間映射回輸入空間,以生成數據點。它們通常都是用重參數化技巧(Reparameterization Trick)來訓練的。
以下是VAE的構造:圖源
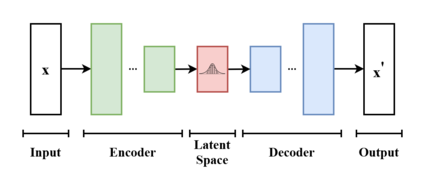
VAE的訓練目標是最大化生成數據的相似性,同時最小化後驗機率和先驗機率之間的差異。將目標轉化為一個特定的損失函數,包括兩部分:
VAE和傳統AE的主要不同之處在於建模方式。在Autoencoder中,潛在向量通常是固定的、無結構的數值,而在VAE中則是一個概率分佈,使VAE能夠生成多樣性的結果。
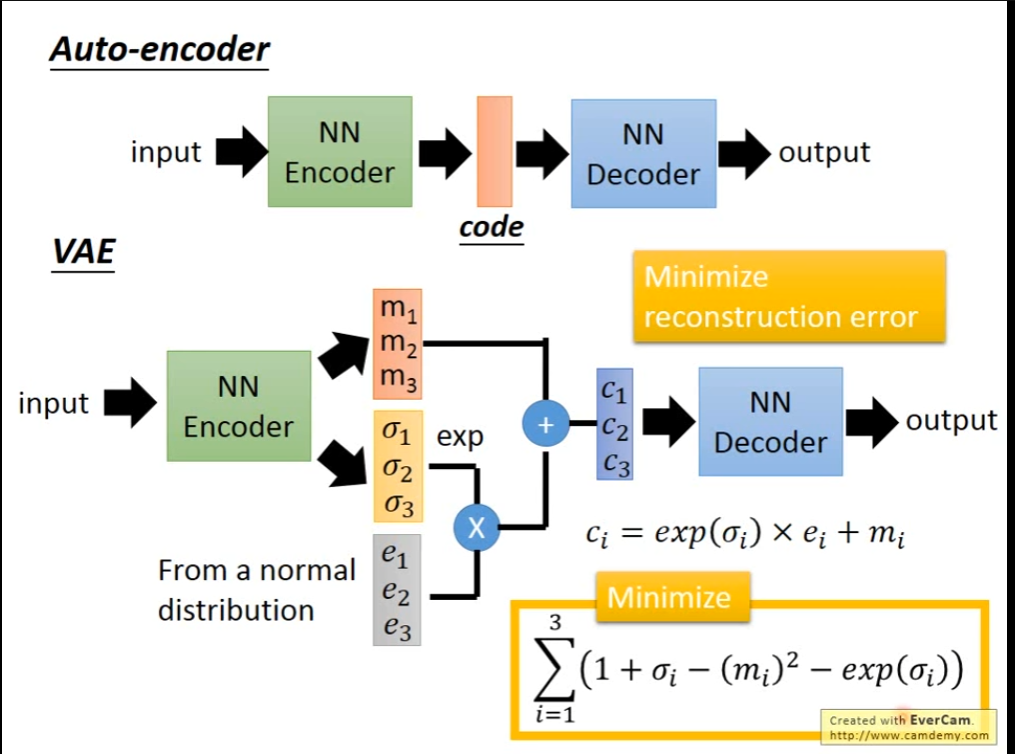
詳細的數學推導可參考李宏毅老師的影片:YT
以上就是小弟我今天分享有關於VAE的簡單小知識,明天將會進一步使用VAE進行實作,那我們明天見!


 iThome鐵人賽
iThome鐵人賽