昨天的教學中,已經學會設定基本的OpenAI-Compatible Server方法了。
簡單回顧一下,若是什麼也沒設定,預設會是使用一個GPU。 🎮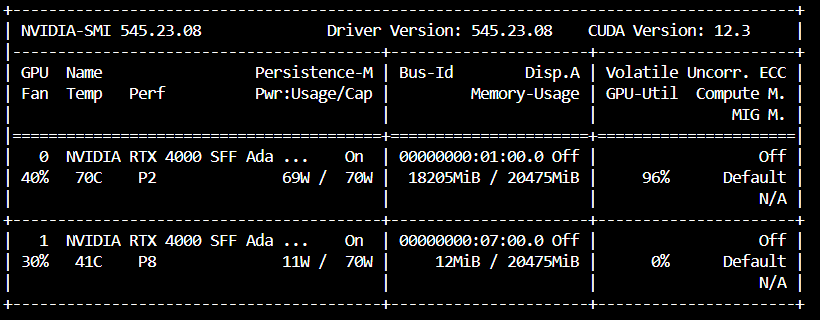
筆者拿了一個閱讀測驗QA問答集測試 📚,一筆一筆發,請vLLM生成回應,一共跑了16分鐘。 ⏱️
(時間僅供參考用,每個人的電腦設備和設定都不同)
- 但是......電腦有兩個GPU耶! 🖥️
- 說好的分散式計算在哪裡? 🔀
- 現在跑的速度,應該還可以再更快、更快對吧! 🚀
- 還想跑更長context length的模型欸! 📜
- 量化的模型怎麼跑? 🧮
這一章就要來看這些可以手動設定、調整的部分,也就是進階篇章。 ✨
回顧一下 Day11 提過的兩種模型平行化設定方式。而官方文件的解說在這裡。
The tensor parallel size is the number of GPUs you want to use in each node, and the pipeline parallel size is the number of nodes you want to use.
Tensor Parallel Size:每個node內的GPU數量。
Pipeline Parallel Size:node的數量。所以如果要使用多個GPU,簡單的數量設定公式是:
你有幾張GPU = tensor-parallel-size * pipeline-parallel-size
從官方文件可以看到,目前vLLM提供了2種管理分散式推理的方法:
首先,如果VRAM夠大,並且想要推理速度快一些的話,可以設定--tensor-parallel-size。
因為筆者的GPU只有2,所以一次只能開一個示範。
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--port 8503 \
--tensor-parallel-size 2
如果把GPU開好開滿,他也會用好用滿,速度上明顯有變快,筆者的QA資料集從16分鐘變成8分鐘,直接快兩倍!
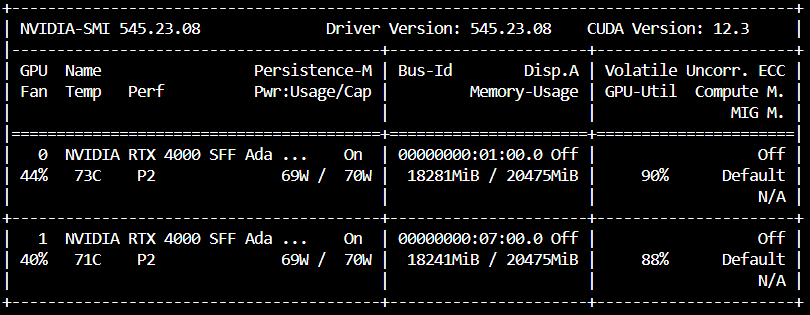
因為Tensor Parallelism是將模型的計算部分分散到多個GPU上,變快兩倍都是合理的,但是當模型大到一個VRAM不夠用的時候就需要用到Pipeline parallelism。
使用Pipeline Parallelism的話,可以設定--pipeline-parallel-size。
之前看的時候(2024/8之前XD?)因為Pipeline Parallelism不支援Multiprocessing,要特別將當時預設會是mp的distributed-executor-backend,改成是ray,不過現在不用了。因為現在預設的規則是,如果GPU不足或需要multi-node推理,則會自動切換到ray。
另外,如果沒有指定要用Ray,且單個node上有足夠的GPU VRAM(滿足tensor-parallel-size的需求),預設會使用multiprocessing。
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--port 8503 \
--pipeline-parallel-size 2
🔀 或是手動指定Ray(現在已經會自動切換,其實不用特別指定):
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--port 8503 \
--pipeline-parallel-size 2
--distributed-executor-backend ray
在推論中可以看到,這次兩張GPU不是都用好用滿了,其中一張維持在38-41,另一張則是在83-89左右,而速度上同樣跑筆者的QA資料集,執行時間是18分鐘,反而變慢了。
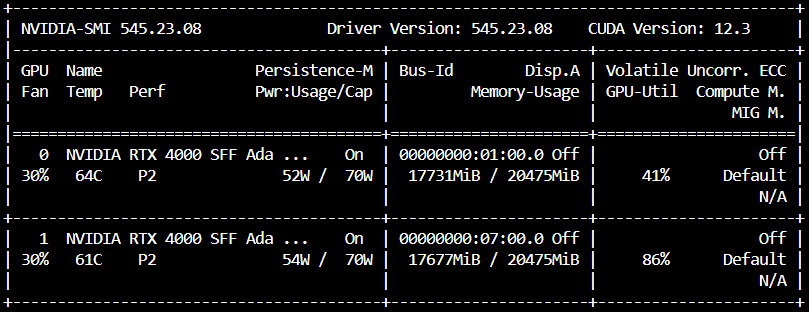
變慢的原因如下,也可以從 Day11 回顧 📅:
- 因為Pipeline Parallelism需要在所有的GPU之間傳輸資料 🔄,所以傳輸時間也變長了。 ⏳
- 如果模型每個階段的計算量不平衡 ⚖️,可能會導致有GPU閒置,在等其他GPU計算完畢,導致GPU使用率低下。 📉
現在vLLM有支援Speculative decoding,可以選擇兩種方法進行推理:一種是使用較小的draft model,另一種則是使用ngram進行推理,這兩種都必須要打開use-v2-block-manager。如果要精確一點的答案,num_speculative_token可以調小;如果速度比較重要,則是調大。
⚠️ Please note that speculative decoding in vLLM is not yet optimized and does not usually yield inter-token latency reductions for all prompt datasets or sampling parameters. The work to optimize it is ongoing and can be followed in this issue.
⚠️ Currently, speculative decoding in vLLM is not compatible with pipeline parallelism.雖然官方有警告說Speculative decoding還沒有到最佳化,不過看到今年8月的進度已經幾乎完成了,延遲甚至減少了45%。
🔬 秉持著實驗精神,如果使用相同的draft model的話,因為要同時跑兩個的模型,也不是用小的模型當draft model,這些額外的計算讓筆者的QA資料集跑了大約12分鐘,並沒有比較划算。
這邊官方的範例是 model="facebook/opt-6.7b" 和 speculative_model="facebook/opt-125m"。
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--port 8503 \
--tensor-parallel-size 2 \
--speculative-model meta-llama/Meta-Llama-3-8B-Instruct \
--num-speculative-tokens 5 \
--use-v2-block-manager
如果要使用不同的draft model,需要確認兩個模型的詞彙表大小(vocab size)一致,可以先檢查兩個model的tokenizer大小,BY GPT-4o:
from transformers import AutoTokenizer
final_model_tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
final_model_vocab_size = final_model_tokenizer.vocab_size
draft_model_tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
draft_model_vocab_size = draft_model_tokenizer.vocab_size
print(f"Final model vocab size: {final_model_vocab_size}")
print(f"Draft model vocab size: {draft_model_vocab_size}")
📊 如果是用ngram的話,速度上筆者的QA資料集變成只要5分鐘!是目前最快的速度!
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--port 8503 \
--tensor-parallel-size 2 \
--speculative-model [ngram] \
--num-speculative-tokens 5 \
--ngram-prompt-lookup-max 4 \
--use-v2-block-manager
注意這邊如果是用vLLM開API的方法,在不同版本中要注意 - 和 _ 的寫法,像是
use_v2_block_manager=True這一行會是 - 的寫法而不是 _ 的寫法。
因為在比較舊的版本中,有些沒有被統一到XD
請參考:https://docs.vllm.ai/en/latest/models/engine_args.html#engine-args
假設筆者想要跑yentinglin/Llama-3-Taiwan-8B-Instruct-128k,但設備用的是只有32GB的電腦,而昨天提到預設的--gpu-memory-utilization是0.9,正是在 Day12 中提到的VRAM預留的一個記憶體大小,如果記憶體不夠的話就會出現下方的警告。
ValueError: The model's max seq len (131072) is larger than the maximum number of tokens that can be stored in KV cache (88528). Try increasing `gpu_memory_utilization` or decreasing `max_model_len` when initializing the engine.
這時有兩個選擇,一個是增加--gpu-memory-utilization,調到0.95用好用滿看裝不裝得下 💪;又或是減少--max-model-len,從原本131072減少到88528以下 📉,至少就可以執行大context length模型囉。
筆者調整了之後,雖然像是23910 tokens這種長度是可以跑的,但還是沒辦法跑88528那麼長的context length,原因推測還是KV cache的記憶體占用問題 💾,不過至少比原本8000 tokens還要多很多了XD?
- 補充一下long context length model的使用心得:
一定要記得設定max_tokens=512,不然很容易鬼打牆就一直卡著直到最大context length,API都timeout了還生成不完QQ
詳細請見官方文件。
--host 0.0.0.0 如果可以將vLLM API對外被任何其他電腦訪問時可以設定。
--dtype auto 一般會是預設'auto',可以在API啟動後某一行看到他的選擇是什麼,也可自行設定 'float16'、'bfloat16'、'float32'。
--quantization awq 可以指定量化方法 🧮,目前支援'awq'、'gptq'、 'squeezellm'、'fp8' (experimental)。
--gpu-memory-utilization 0.75 可以設定一個0-1之間的浮點數,調整GPU的記憶體使用比例,增加的話可以預先提供更多的KV快取空間。
--max_seq_len 4096 可以控制模型的context length長度。
如果想指定GPU,可以在指令最前面加上: CUDA_VISIBLE_DEVICES=0
我們學會了如Tensor Parallelism與Pipeline Parallelism的差異,並且體驗了Speculative decoding更加速了local LLM的生成速度 📚。目前vLLM量化模型的使用沒有支援跑GGUF的量化模型,而同樣的官方文件表示目前AWQ支援還為最佳化,筆者跑起來AWQ跟vLLM (bfloat16) + Speculative decoding的速度差不多,因此可以看出vLLM真的很快!
明天來繼續在vLLM的文件中尋寶! 🧭🗺️✨

(圖源: codecademy)

