昨天 (Day 4) 我們比較了 向量資料庫,解決了「知識要存在哪裡,怎麼檢索」的問題。
但在 RAG (Retrieval-Augmented Generation) 裡,還有另一個同等重要的環節:
❓ 要怎麼把文字轉成向量 (Embedding)。
因為如果 Embedding 模型效果不好,「請假」可能會和「旅行」比對在一起,而不是和「休假」相近。這樣檢索到的文件就完全錯了,RAG pipeline 也就失敗。
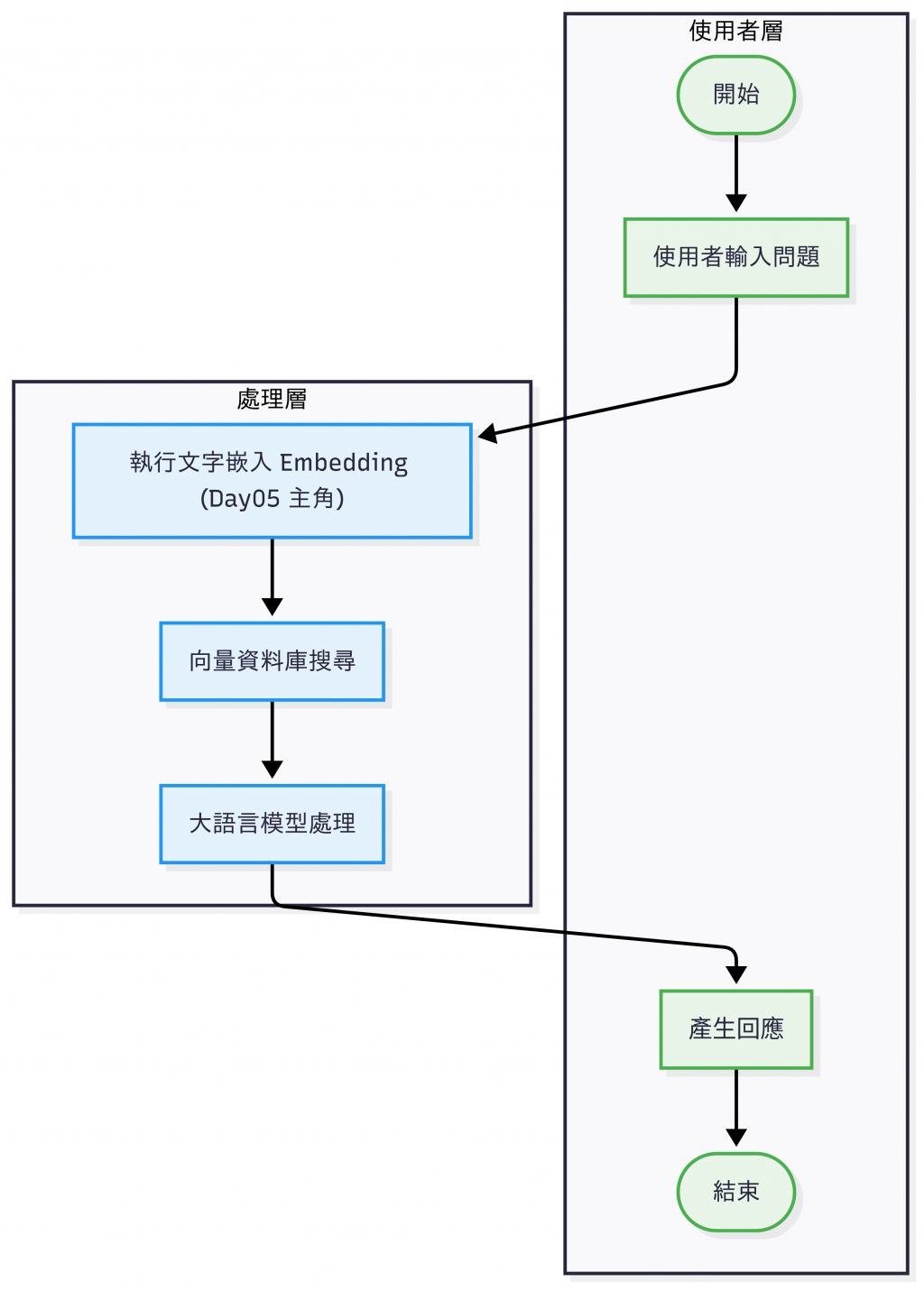
RAG 流程(此為缺少文檔預處理以及回覆後處理的簡化版)
所以今天,我們要比較幾種常見的 Embedding 模型(OpenAI、HuggingFace、BGE、Cohere),
看誰能在「語意檢索」這件事上表現最好。
Embedding 就像是「文字的座標化」。
例如下面三句話:
Embedding 模型是透過大量語料訓練,把語意相近的詞句投影到相近的向量位置。這樣系統才能用 數學運算 - 餘弦相似度(cosine similarity) 取代傳統的 字串比對。以上述舉的例子來說,理想的向量空間應該要讓「請假」和「休假」的距離很近,而「旅行」稍微遠一點,這樣檢索出來的結果才符合語意。
在實務場景裡,這種語意對齊格外重要。
例如一個 FAQ Bot,當使用者問「怎麼申請休假?」時,系統應該要能檢索到「請假流程」的文件;又或者在 客服知識庫 裡,不同人可能會使用「薪水」「薪資」「工資」等不同說法,Embedding 必須能理解這些詞語其實指向相同概念,才能確保檢索結果符合用戶需求。
這裡我們挑選了四種常見 Embedding 模型:OpenAI、HuggingFace、BGE、Cohere,並針對語言支援、效果 (相似度示例)、硬體需求、收費與適合場景進行比較。
| 模型 | 公司/國家 | 語言支援 | 硬體需求 | 收費 | 適合場景 |
|---|---|---|---|---|---|
| OpenAI (text-embedding-3-small/large) | OpenAI(美國) | 多語言(中/英/日等) | 雲端 API,無需本機硬體 | Token 計價,需付費 | 快速 MVP、多語言應用 |
| HuggingFace MiniLM (all-MiniLM-L6-v2) | Microsoft Research + HuggingFace(美國) | 英文最佳,中文一般 | CPU 可跑,GPU 更快 | 免費 (開源)[註3] | 個人專案、英文知識檢索 |
| BGE (BAAI/bge-small-zh-v1.5) | BAAI 北京智源人工智能研究院(中國) | 中文特化[註1] | 本機可跑:GPU 建議,本機可跑[註2] | 免費 (開源) | 中文 QA、企業知識庫 |
| Cohere (embed-english-v3.0) | Cohere (加拿大) | 英文最佳,支援跨語言 | 雲端 API,無需本機硬體 | Token 計價,需付費 | 英文知識庫、商用 SaaS |
[註1] 泛指簡體中文。
[註2] 需要依據最大輸入 tokens / context window / 向量維度 / 延遲吞吐等因素而定。
[註3] 延伸閱讀:這裡單指模型本身是不需要付費的,但實際上使用會需要考慮更多面向,比如轉換和儲存成本,Day 26 我們會提到這塊。
完整可執行專案 已經放在 GitHub。
一樣用 conda 啟動環境:
conda env create -f environment.yaml
conda activate day05_embedding
from openai import OpenAI
from dotenv import load_dotenv
import numpy as np
import os
# 載入 .env
load_dotenv()
# 讀取金鑰
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise RuntimeError("❌ 找不到 OPENAI_API_KEY,請確認 .env 或環境變數設定")
client = OpenAI()
texts = ["我今天請假", "我要休假", "我想去旅行"]
embs = [client.embeddings.create(model="text-embedding-3-small", input=t).data[0].embedding for t in texts]
sim = np.dot(embs[0], embs[1]) / (np.linalg.norm(embs[0]) * np.linalg.norm(embs[1]))
print("請假 vs 休假 相似度:", sim)
sim = np.dot(embs[1], embs[2]) / (np.linalg.norm(embs[1]) * np.linalg.norm(embs[2]))
print("休假 vs 旅行 相似度:", sim)
sim = np.dot(embs[0], embs[2]) / (np.linalg.norm(embs[0]) * np.linalg.norm(embs[2]))
print("請假 vs 旅行 相似度:", sim)
結果:
❯ python openai_embedding_demo.py
請假 vs 休假 相似度: 0.7618106440094277
休假 vs 旅行 相似度: 0.5885526266358054
請假 vs 旅行 相似度: 0.4865730089098357
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
texts = ["我今天請假", "我要休假", "我想去旅行"]
embs = model.encode(texts)
sim = np.dot(embs[0], embs[1]) / (np.linalg.norm(embs[0]) * np.linalg.norm(embs[1]))
print("請假 vs 休假 相似度:", sim)
sim = np.dot(embs[1], embs[2]) / (np.linalg.norm(embs[1]) * np.linalg.norm(embs[2]))
print("休假 vs 旅行 相似度:", sim)
sim = np.dot(embs[0], embs[2]) / (np.linalg.norm(embs[0]) * np.linalg.norm(embs[2]))
print("請假 vs 旅行 相似度:", sim)
結果:
❯ python huggingface_minilm_demo.py
請假 vs 休假 相似度: 0.8110042
休假 vs 旅行 相似度: 0.8215162
請假 vs 旅行 相似度: 0.73472106
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
texts = ["我今天請假", "我要休假", "我想去旅行"]
embs = model.encode(texts, normalize_embeddings=True)
sim = np.dot(embs[0], embs[1])
print("請假 vs 休假 相似度:", sim)
sim = np.dot(embs[1], embs[2])
print("休假 vs 旅行 相似度:", sim)
sim = np.dot(embs[0], embs[2])
print("請假 vs 旅行 相似度:", sim)
結果:
❯ python bge_demo.py
請假 vs 休假 相似度: 0.7691307
休假 vs 旅行 相似度: 0.57563287
請假 vs 旅行 相似度: 0.49289015
👉 BGE 系列(base、large)在簡體中文 QA、知識檢索的效果特別好。[註1]
import cohere
import numpy as np
import os
from dotenv import load_dotenv
# 載入 .env 檔案,讀取環境變數(例如 API Key)
load_dotenv()
# 從環境變數取得 Cohere API Key
api_key = os.getenv("COHERE_API_KEY")
if not api_key:
# 若沒有設定金鑰就直接中斷
raise RuntimeError("❌ 找不到 COHERE_API_KEY,請確認 .env 或環境變數設定")
# 初始化 Cohere Client
co = cohere.Client(api_key)
# 測試用的三個句子
texts = ["我今天請假", "我要休假", "我想去旅行"]
# 呼叫 Cohere 的 Embed API
# - model="embed-english-v3.0":使用 Cohere 最新的英文向量模型(多語言也有一定支援)
# - input_type:可設定 "search_document"(文件庫向量)或 "search_query"(查詢向量)
resp = co.embed(
texts=texts,
model="embed-english-v3.0",
input_type="search_document"
)
# 取得向量結果,轉成 numpy array
# shape: (3, 1024) → 三個句子,每個句子轉成 1024 維向量
embs = np.array(resp.embeddings)
print(f"Embeddings shape: {embs.shape[0]} x {embs.shape[1]}")
# 定義 cosine similarity 計算函式
def cos(a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
# 計算相似度
print("請假 vs 休假 相似度:", round(cos(embs[0], embs[1]), 3))
print("休假 vs 旅行 相似度:", round(cos(embs[1], embs[2]), 3))
print("請假 vs 旅行 相似度:", round(cos(embs[0], embs[2]), 3))
結果:
❯ python cohere_demo.py
Embeddings shape: 3 x 1024
請假 vs 休假 相似度: 0.802
休假 vs 旅行 相似度: 0.882
請假 vs 旅行 相似度: 0.731
| 模型 | 請假 vs 休假 | 請假 vs 旅行 | 休假 vs 旅行 | 分離度(↑佳)[註1] |
|---|---|---|---|---|
| OpenAI (text-embedding-3-small) | 0.762 | 0.487 | 0.589 | 0.275 |
| HuggingFace MiniLM (all-MiniLM-L6-v2) | 0.811 | 0.735 | 0.822 | 0.076 |
| BGE (bge-small-zh-v1.5) | 0.769 | 0.493 | 0.576 | 0.276 |
| Cohere (embed-english-v3.0) | 0.802 | 0.731 | 0.882 | 0.071 |
這組中文例句下,BGE ≈ OpenAI 的分離度表現最佳,能把「旅行」明顯拉遠。MiniLM、Cohere 對「旅行」距離偏近(特別是 Cohere 的「休假 vs 旅行」很高),顯示中文語意分離較弱。
🧐 為什麼看「分離度」?
不是只有「請假 vs 休假」要接近,更重要的是「請假/休假」要和「旅行」保持距離,才能避免檢索錯誤。分離度就反映了模型在「相似要近、不同要遠」的平衡能力。
這張比較表只是極小的樣本對比,實務建議要用更多的語料,並透過 RAG 檢索評測指標(例如 HitRate、MRR、nDCG)來做量化比較[註2],再決定要用哪個 embedding 模型。
[註1] 分離度(Separation) =(請假 vs 休假)− min(請假 vs 旅行, 休假 vs 旅行),越高代表越能把「旅行」和請/休假區分開)
[註2]📊 常見檢索評測指標:
HitRate@k:Top-k 命中率,查詢的正確答案是否出現在前 k 筆結果中。
MRR (Mean Reciprocal Rank):平均倒數排名,命中的越靠前分數越高。
nDCG (Normalized Discounted Cumulative Gain):考慮多個答案的排序合理性,越前面的正確答案分數越高。
今天我們比較了四種 Embedding 模型,並得到以下結論:
明天 (Day 6),我們會實作第一個 Minimal RAG QA Bot,到時候我們會用今天挑的 embedding 模型 + Day04 的向量資料庫,拼湊出第一個最小可行的 RAG Pipeline。

