前兩天我們分別搞定了 RAG 的兩個基礎拼圖:
今天,我們會把它們組合起來,跑出一個最小可行的 RAG Demo,就會是本系列文章的第一個完整成果。
大語言模型 (LLM) 的限制:
RAG (Retrieval-Augmented Generation) 的解法是:
👉 先檢索相關文件,再讓 LLM 生成答案。
也就是把「我們準備的知識庫」接進來,讓 LLM 能基於正確資訊回答問題,這也是本系列文章的主軸。
今天的文章會展示 RAG 最小可行的流程:
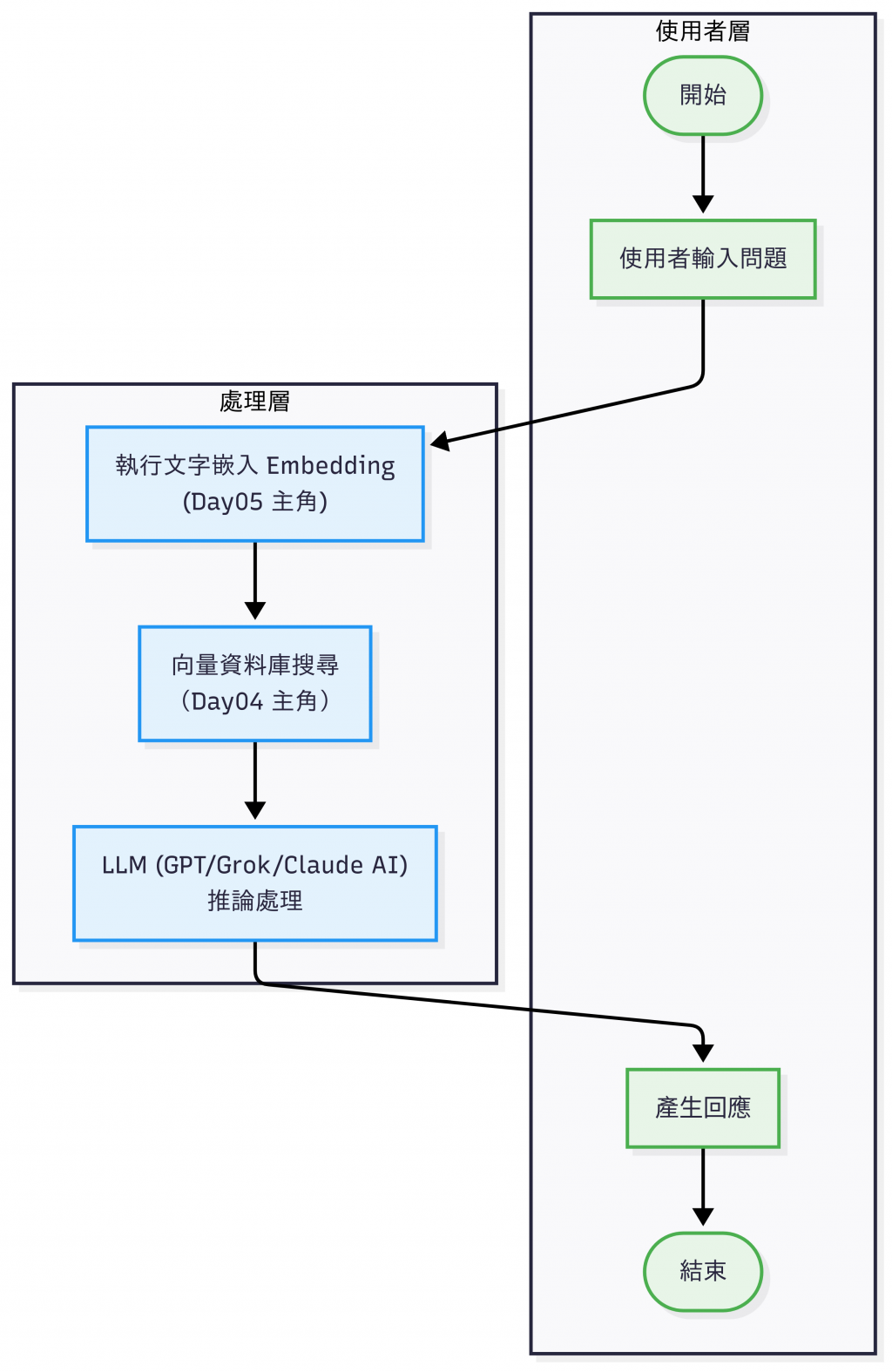
RAG 流程(此為缺少文檔預處理以及回覆後處理的簡化版)
📌
[註1] 在真實場景中,文件通常會先經過 清洗 (Cleaning) 和 切片 (Chunking) 等預處理流程以及後處理,但為了讓流程跑起來,我們會在 Day08 講到這塊。
[註2] 在 RAG 的脈絡裡,Augment 指的是「增補 / 擴充」──把檢索到的文件片段放進 Prompt,提供模型額外的上下文。今天的 Demo 採用最簡單的方式:直接把找到的原文丟進去 LLM。之後我們會再補上 Context 長度控制、Prompt 模板 等更進階的處理。
今天我們依照上面的流程圖用 OpenAI Embedding + FAISS 做一個最小範例。
完整可執行專案 已經放在 GitHub。
🤔 可能會有人好奇:既然 HuggingFace / BGE 模型都可以在本機執行,為什麼我要用 OpenAI API 來做 Embedding?
「本機 vs API」並沒有絕對的優劣,選擇要看情境:如果你有 GPU 環境、偏好中文或特定語言支援,且能自己維運,直接跑本機模型會比較划算;但若是需要多語言、快速開發、不想管硬體或維護,走 API(OpenAI、Cohere 這類雲端服務)通常更方便,尤其在小規模使用時成本也未必比較高。
很多專案會先用 API 快速起步,等規模變大、需求明確後,再考慮遷移到本機模型。
# utils_openai.py
# 小工具模組,把 OpenAI 的常用動作(產生 embedding、呼叫聊天模式)
# 讓 step2 和 step3 的程式可以呼叫
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
_client = None
def get_openai_client():
global _client
if _client is None:
_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
return _client
EMBED_MODEL = "text-embedding-3-small"
CHAT_MODEL = "gpt-4o-mini"
def embed(text: str):
client = get_openai_client()
resp = client.embeddings.create(model=EMBED_MODEL, input=text)
return resp.data[0].embedding
def chat_answer(system_prompt: str, user_prompt: str):
client = get_openai_client()
resp = client.chat.completions.create(
model=CHAT_MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
return resp.choices[0].message.content
整理一些規則和答案:
docs = [
"請假流程:需要先主管簽核,然後到 HR 系統提交。",
"加班申請:需事先提出,加班工時可折換補休。",
"報銷規則:需要提供發票,金額超過 1000 需經理簽核。"
]
寫入 data/docs.json :
# step1_prepare_docs.py
import json
from pathlib import Path
DOCS = [
"請假流程:需要先主管簽核,然後到 HR 系統提交。",
"加班申請:需事先提出,加班工時可折換補休。",
"報銷規則:需要提供發票,金額超過 1000 需經理簽核。"
]
def main():
out = Path("data")
out.mkdir(parents=True, exist_ok=True)
with open(out / "docs.json", "w", encoding="utf-8") as f:
json.dump(DOCS, f, ensure_ascii=False, indent=2)
print("✅ 已寫入 data/docs.json")
if __name__ == "__main__":
main()
執行:
❯ python3 day06_tag_mini_demo/step1_prepare_docs.py
✅ 已寫入 data/docs.json
# step2_build_index.py
import json
import numpy as np
import faiss
from pathlib import Path
from utils_openai import embed, EMBED_MODEL # 呼叫 OpenAI 的工具模組
DATA_PATH = Path("data/docs.json")
INDEX_DIR = Path("index")
def main():
# 1) 載入 step1 建立的文件
docs = json.loads(DATA_PATH.read_text(encoding="utf-8"))
# 2) 先算第一個 embedding 取得維度
first_vec = np.array(embed(docs[0]), dtype="float32")
d = first_vec.shape[0]
index = faiss.IndexFlatL2(d)
# 3) 全量轉 embedding 並加入索引
all_vecs = [first_vec] + [np.array(embed(t), dtype="float32") for t in docs[1:]]
mat = np.vstack(all_vecs) # (N, d)
index.add(mat)
# 4) 輸出索引與中繼資料
INDEX_DIR.mkdir(parents=True, exist_ok=True)
faiss.write_index(index, str(INDEX_DIR / "faiss.index"))
meta = {
"model": EMBED_MODEL,
"dim": int(d),
"docs": docs
}
(INDEX_DIR / "meta.json").write_text(json.dumps(meta, ensure_ascii=False, indent=2), encoding="utf-8")
print(f"✅ 建索引完成:{len(docs)} 篇,維度 {d}")
if __name__ == "__main__":
main()
執行:
❯ python3 day06_tag_mini_demo/step2_build_index.py
✅ 建索引完成:3 篇,維度 1536
# step3_query_answer.py
import json
import numpy as np
import faiss
from pathlib import Path
from utils_openai import embed, chat_answer
INDEX_DIR = Path("index")
def load_index_and_meta():
index = faiss.read_index(str(INDEX_DIR / "faiss.index"))
meta = json.loads((INDEX_DIR / "meta.json").read_text(encoding="utf-8"))
return index, meta
def retrieve_top_k(index, query_vec, k=1):
query_mat = np.array([query_vec], dtype="float32")
D, I = index.search(query_mat, k)
return D[0], I[0] # 距離、索引
def main():
query = "我要怎麼請假?"
# 1) 載入索引+文件
index, meta = load_index_and_meta()
docs = meta["docs"]
# 2) 查詢向量
q_vec = np.array(embed(query), dtype="float32")
# 3) 檢索
D, I = retrieve_top_k(index, q_vec, k=1)
context = docs[I[0]]
print("🔎 最相關文件:", context)
# 4) 讓 LLM 生成答案
system_prompt = "你是一個企業 FAQ 助理。請根據提供的知識庫內容回答使用者問題,若知識庫未涵蓋請說明不知道。"
user_prompt = f"根據以下知識庫內容回答:\n{context}\n\n問題:{query}"
# 5) 把兩個 prompt 印出來
print("\n===== System Prompt =====")
print(system_prompt)
print("\n===== User Prompt =====")
print(user_prompt)
answer = chat_answer(system_prompt, user_prompt)
print("\n🧠 答案:", answer)
if __name__ == "__main__":
main()
執行以及輸出結果:
❯ python3 day06_tag_mini_demo/step3_query_answer.py
🔎 最相關文件: 請假流程:需要先主管簽核,然後到 HR 系統提交。
===== System Prompt =====
你是一個企業 FAQ 助理。請根據提供的知識庫內容回答使用者問題,若知識庫未涵蓋請說明不知道。
===== User Prompt =====
模擬使用者提問:
請假流程:需要先主管簽核,然後到 HR 系統提交。
問題:我要怎麼請假?
🧠 答案: 請假流程是需要先獲得主管的簽核,然後再到 HR 系統提交請假申請。如果您有其他具體的問題或需要更多幫助,歡迎告訴我!
🎉 到這邊,第一個 RAG QA Demo 就成功了!
準確性
可控性
即時性
檢索品質
文件切片 (Chunking)
結果排序 (Reranking)


 iThome鐵人賽
iThome鐵人賽