YOLO(You Only Look Once)是一種知名的即時物件偵測模型,由 Joseph Redmon 和 Ali Farhadi 於 2015 年首次提出,技術核心在於能夠「一次」處理輸入影像,快速且準確地辨識出多個物體並標註其位置,因此廣泛運用於自動駕駛、安防監控、工業自動化等多項領域。
YOLO 屬於單階段物件偵測系統,將物件偵測問題轉化為一個回歸任務:輸入一張影像,模型會將其劃分成小的網格(如7x7、13x13),每個網格都預測是否有物體、物體的位置(中心座標與寬高)、以及物體的分類和置信度。骨幹網路(通常是卷積神經網路CNN)會先萃取影像深度特徵,接著由預測頭直接推斷出所有物件及座標,因此運算速度極快,能在毫秒等級完成檢測,適合高要求的即時應用。
YOLO自2015年問世以來,歷經多次改版,目前最新的版本是YOLOv11。
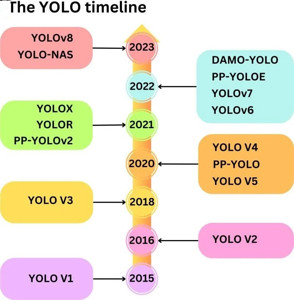
(示意圖由 Copilot 協助生成)
YOLO 以即時性和高效能見長,能同時檢測多種不同大小的物件,並且直接推論所有結果,省去複雜後處理流程,因此特別適合需要快速反應的場合。常見應用包括:
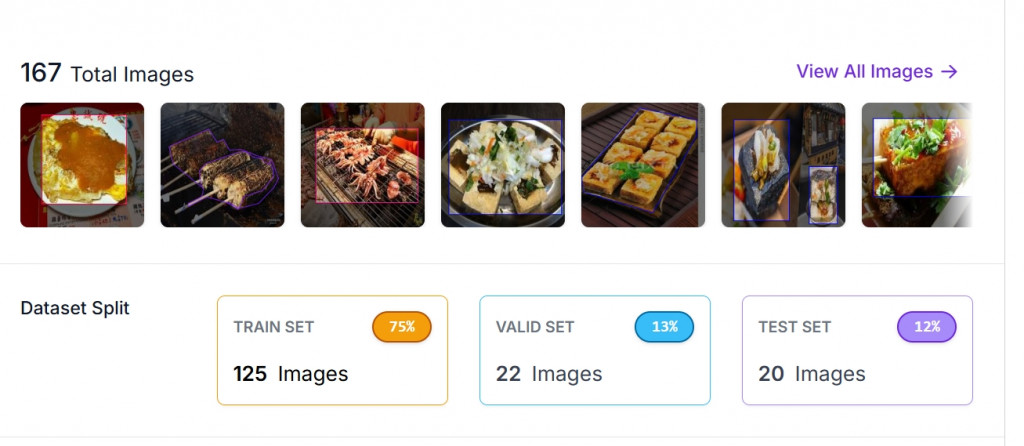
參考 Day5 的步驟,收集台灣夜市美食圖片,上傳到 Roboflow 後標註品項名稱,並將資料集分割成訓練/驗證/測試集
溫馨小提醒:
dataset split 的比例建議是 7:2:1,以這次的數量分配來說,理想狀態是 119 : 34 : 17(訓練/驗證/測試組),驗證組的數量有比較少了一點
如果有需要再做資料處理的,例如:資料增強 (Data Augmentation),可以在這個時候調整。接著就會進到 Select Model Architechure 的項目
Day3. 從零開始打造個人專屬 AI 營養顧問 Ep. 2:資料來源、收集與應用
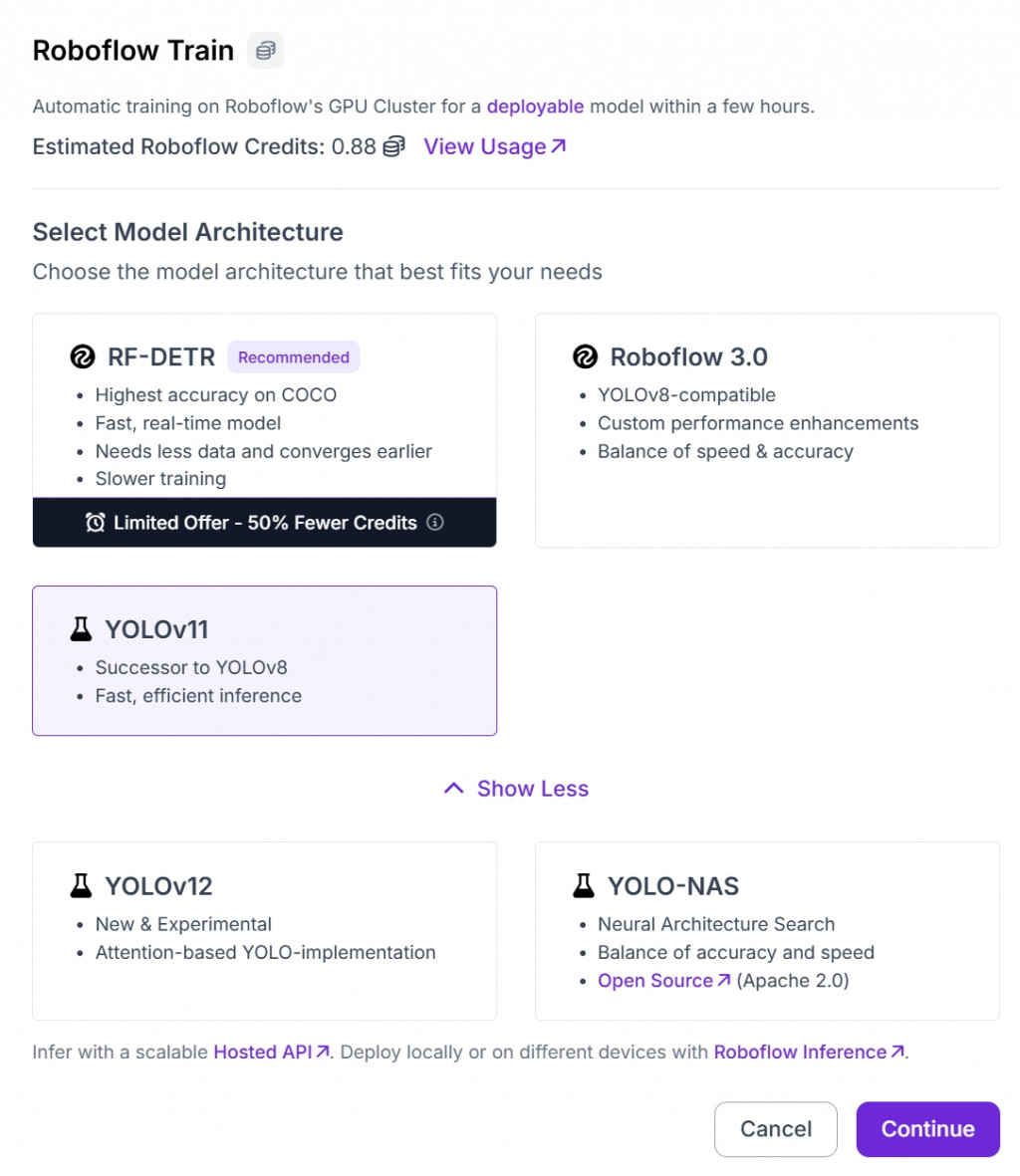
可以從 Roboflow 直接匯出 YOLOv11/YOLOv8/yolov5 (依照個人需求選擇)格式資料夾,包含 images、labels 子資料夾和 dataset.yaml 設定檔。
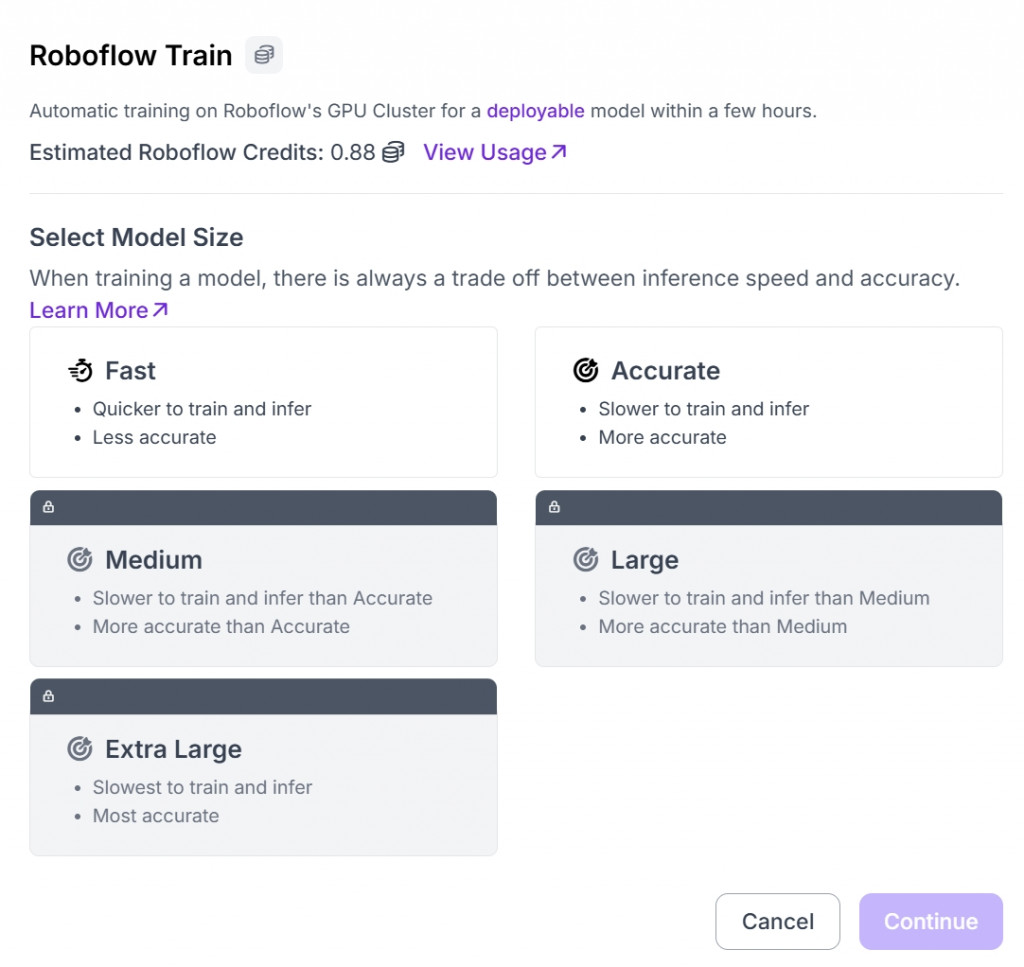
一切都順利的話,就開始「Start Training」
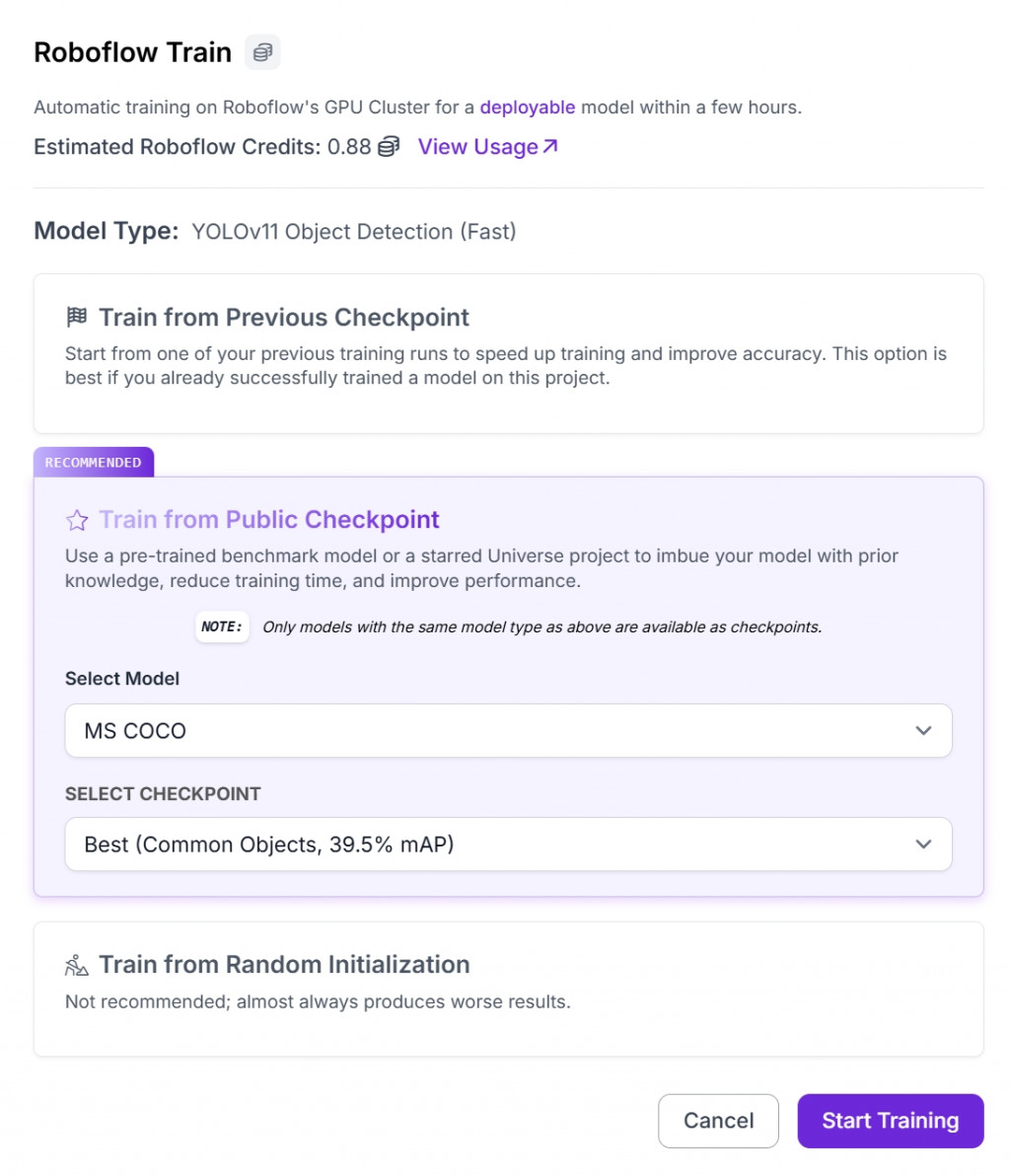
Training in progress. 大約需要26分鐘~
可用 YOLOv8 官方 repo 或 Ultralytics YOLO 套件進行訓練。這部分明天會透過 Google Colab 實作
| 指標名稱 | 中文名稱 | 定義公式 | 說明 | 常見用途 |
|---|---|---|---|---|
| Precision | 精確率 | $\displaystyle Precision = \frac{TP}{TP + FP}$ | 在所有被模型「預測為正確」的結果中,實際上有多少是真的正確。→ 強調「預測的準確度」。 | 適合錯誤代價高的場景(如:醫學影像辨識、食物分類誤標) |
| Recall | 召回率 | $\displaystyle Recall = \frac{TP}{TP + FN}$ | 在所有實際「應該被辨識出來」的項目中,模型成功辨識的比例。→ 強調「找出所有正確項目的能力」。 | 適合漏判代價高的場景(如:食安監測、異常偵測) |
| mAP | 平均精度(Mean Average Precision) | $\displaystyle mAP = \frac{1}{N} \sum_{i=1}^{N} AP_i$ | 綜合考慮 Precision 與 Recall 的整體表現,通常用於物件偵測任務。AP(Average Precision) 是各類別的 Precision-Recall 曲線下的面積,mAP 是所有類別 AP 的平均值。 | 常用於 YOLO、SSD、Faster R-CNN 等影像辨識模型評估 |
混淆矩陣分析 容易誤判的美食,人工補訓練。混淆矩陣是分類模型中最常用的評估工具之一,用來比較「模型預測結果」與「實際標籤」之間的差異。
| 實際值\預測值 | Positive(正類) | Negative(負類) |
|---|---|---|
| Positive(正類) | TP(True Positive)實際是正類,預測也正確 | FN(False Negative)實際是正類,但預測錯誤 |
| Negative(負類) | FP(False Positive)實際是負類,但誤判為正類 | TN(True Negative)實際是負類,預測也正確 |


 iThome鐵人賽
iThome鐵人賽