
在當今資訊爆炸的時代,很多複雜問題都需要我們花費大量時間在網路上搜尋、閱讀和整理資訊。如果能有一個 AI 代理幫我們自動完成這些深度研究任務,將大量資料彙總成有依據的報告,無疑能大幅提升效率。事實證明,「深度研究 (Deep Research)」已經成為當前最熱門的 Agent 應用場景之一:OpenAI、Anthropic、Perplexity、Google 等公司都相繼推出了深度研究功能,能夠利用多種資料源自動產生綜合報告。與此同時,也出現了許多相關的開源實現。
LangChain 團隊近日開源了一個 Open Deep Research 專案,提供了簡單可配置的實現,支援使用者接入自選的大模型、搜尋工具和自有工具服務等。簡單來說,這個深度研究 Agent 可以在使用者提出模糊或複雜的問題時,先與使用者互動澄清需求,然後自動搜尋資料,最終整理輸出詳細的研究報告(包括引用來源)。
本文將深入解析該 Agent 的架構設計,解釋各模組為何如此設計,與如何執行和自訂這個深度研究 Agent。
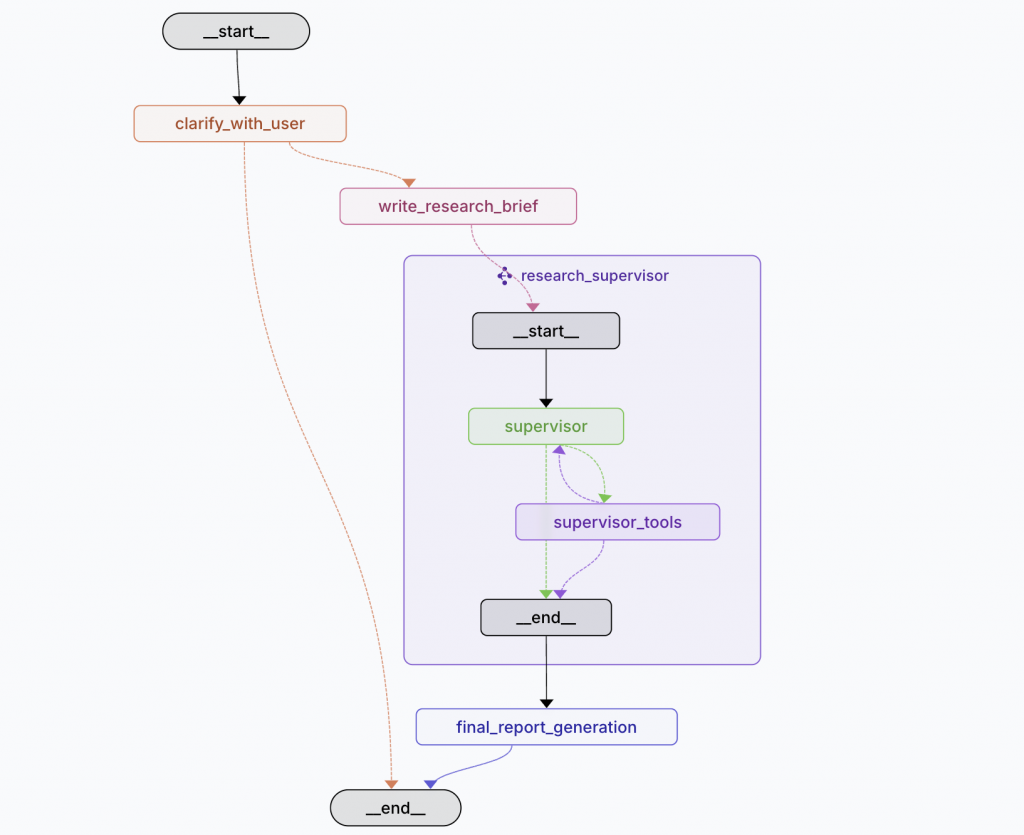
Deep Research Agent 的核心思想是將複雜的研究任務分解為三個清晰、有序的階段。這種模組化的設計使得整個流程更加穩定、可控且高效。
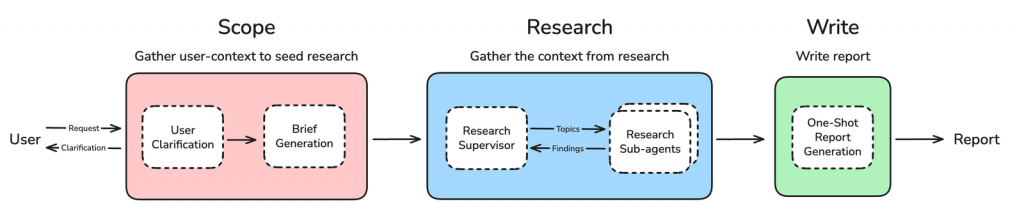
接下來,我們將逐一拆解每個階段的設計理念與運作方式。
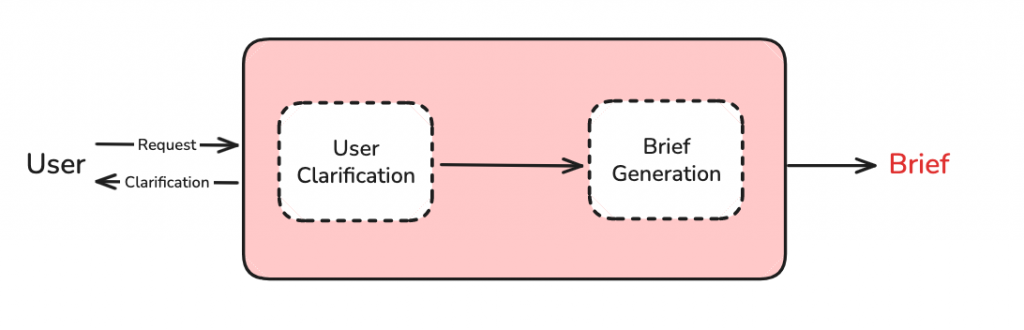
「垃圾進,垃圾出」 是所有 AI 應用的金科玉律。如果 Agent 從一開始就沒搞懂使用者的真正意圖,後續再強大的研究能力也只是徒勞。Scope 階段的核心目標,就是確保輸入給研究核心的任務是「乾淨」且「精準」的。
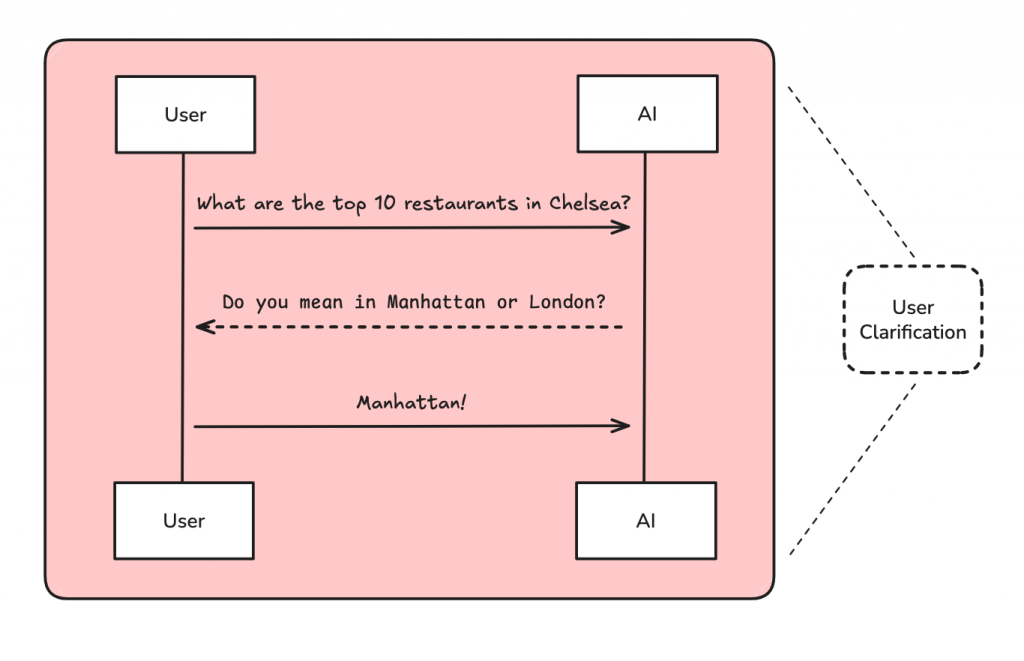
正如影片中的範例,當使用者提出「規劃一趟阿姆斯特丹和挪威的便宜旅行」時,這個請求其實充滿了模糊地帶:
Deep Research Agent 的第一步就是識別這些模糊點,並主動向使用者提問。這個澄清的過程確保了 Agent 在開始大規模研究前,掌握了所有必要的上下文資訊。
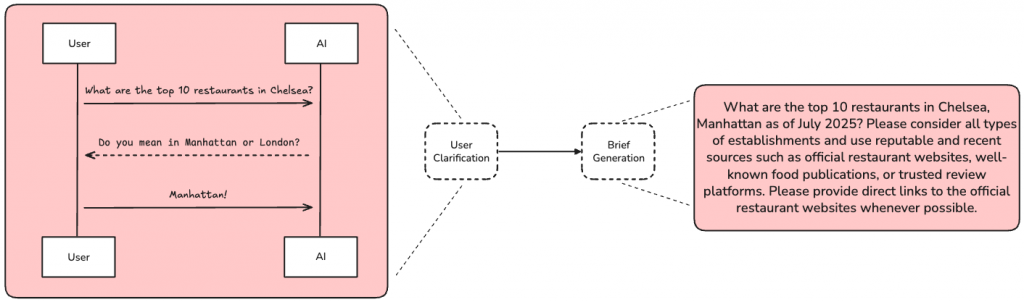
在完成問答澄清後,Agent 會執行一個非常關鍵的動作:將到目前為止的所有對話(原始問題 + 補充資訊)壓縮成一份獨立、完整的「研究簡報 (Research Brief)」。
為何要這麼做?
直接將冗長的對話歷史傳遞下去會帶來幾個問題:
通過生成一份精煉的研究簡報,例如:
"請為三位成人規劃一趟從紐約(任何機場)出發,前往阿姆斯特丹,然後依序遊玩奧斯陸、卑爾根、弗洛姆,最後從挪威返回紐約的最低成本行程。出發日期為 9/12,返回日期為 9/21..."
Agent 為後續的研究階段樹立了一個清晰的靶心。
有了清晰的研究簡報,真正的深度研究現在開始。面對如此複雜的任務,如果只用一個 Agent 來處理,它很容易在多個子任務之間迷失方向。因此,這裡採用了強大的「監督者-子代理 (Supervisor-Sub-agent)」架構。
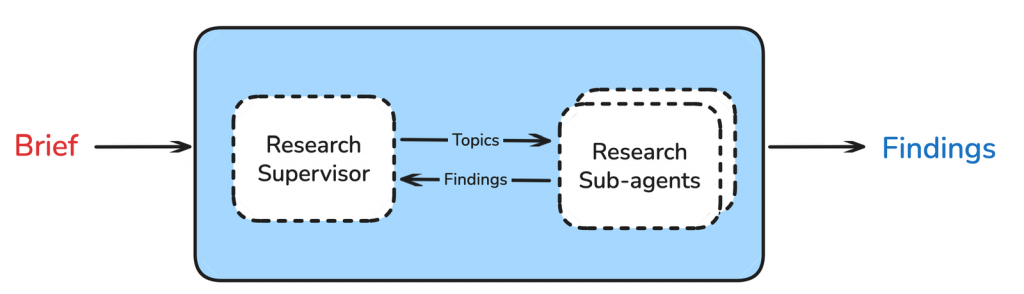
它的角色如同專案經理,負責讀取研究簡報,並將其拆解成多個可以並行處理的子主題。在我們的旅遊案例中,它將任務分解為:
每個子代理都是一個功能齊全但目標專一的 Tool-calling Agent。它們接收 Supervisor 分配的單一任務,在各自獨立的 Context 中進行研究。例如,負責機票的子代理會專心調用航班搜尋工具,而負責住宿的子代理則會專注於旅館和 Airbnb 的搜尋。
這種設計帶來了巨大的好處:
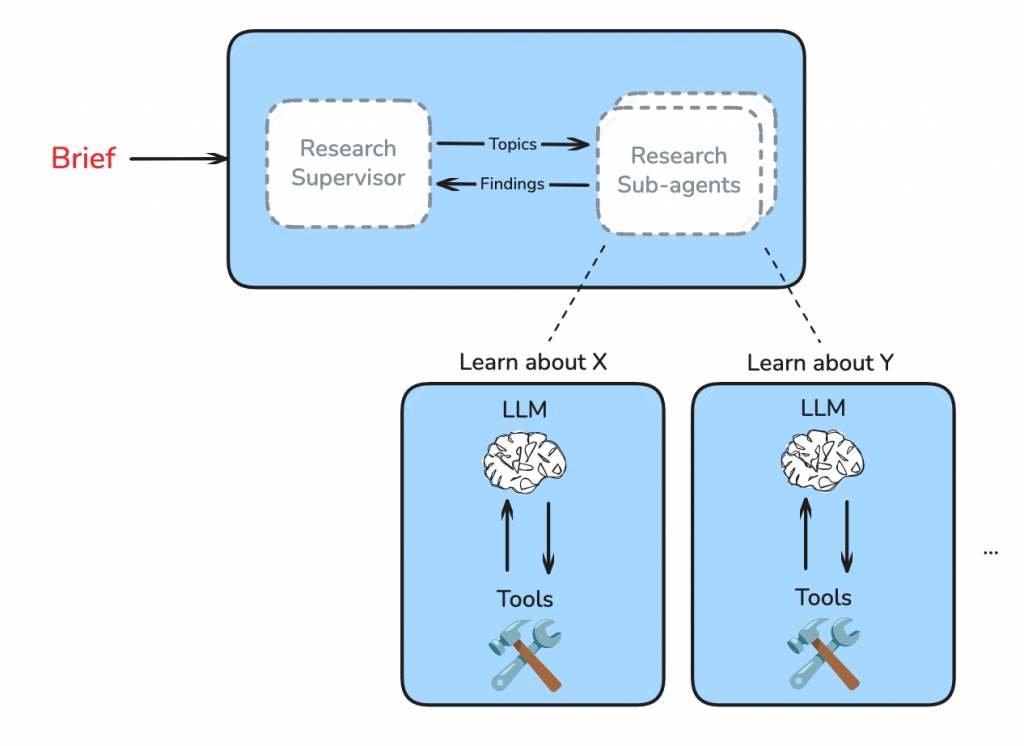
當子代理完成工具調用(例如,搜尋到一堆航班的 JSON 數據),它並不會直接將這些原始、雜亂的資料丟回給 Supervisor。相反,它會執行一個自我清理和壓縮的步驟。
這個步驟的 Prompt 會指示 Agent:「你已經完成研究,現在請清理你的發現,保留所有關鍵資訊和來源,但以更乾淨、更有條理的方式呈現。」
這一步將原始的工具輸出轉化為一份結構化的「迷你報告」,例如,只包含最便宜的三個航班選項、價格、時間和預訂連結。這確保了 Supervisor 最終收集到的所有資訊都是高品質且易於處理的。
當所有子代理都回報了它們的報告後,Supervisor 判斷所有研究都已完成。現在,進入最後的報告撰寫階段。
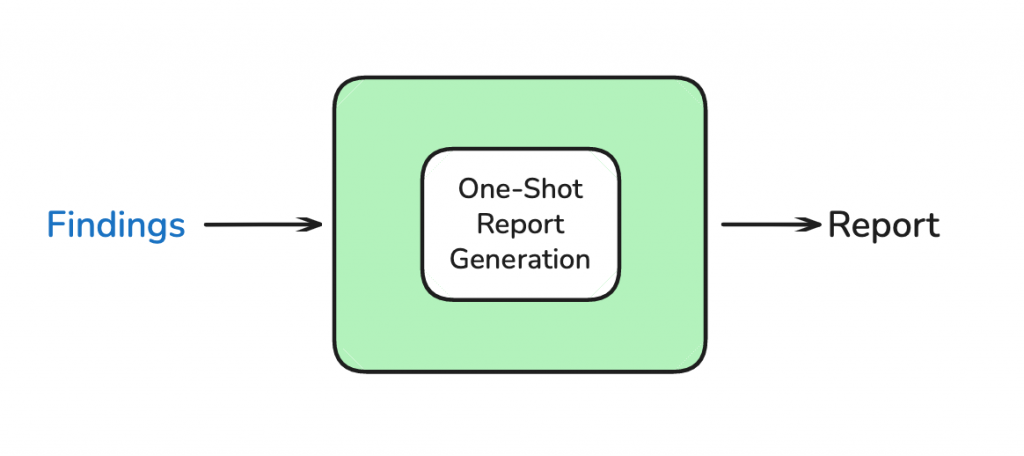
LangChain 團隊的經驗發現,試圖讓多個 Agent 並行撰寫報告的不同部分,結果往往不盡人意,報告會顯得支離破碎。
因此,最佳實踐是:
將最初的研究簡報,以及所有子代理提交的、經過清理的迷你報告,全部打包,一次性 (One-Shot) 地提交給一個專職的「報告寫作 LLM」。
這個寫作 LLM 的 System Prompt 會指示它扮演一個專業的報告撰寫者,根據提供的所有材料,生成一份結構完整、語氣連貫、包含所有細節和引用來源的最終報告。由於輸入的資訊已經是高品質的,寫作 LLM 可以心無旁鶩地專注於呈現和組織,最終產出我們在影片中看到的那份詳盡的旅遊計畫。
透過上述架構拆解,我們可以看出 Deep Research Agent 為勝任複雜的開放式查詢任務,採取了一系列精巧的設計策略。下面總結幾個關鍵的設計要點和背後的最佳實踐。
這個專案是完全開源的,你可以在自己的機器上輕鬆運行它。
環境準備
首先,從 GitHub 上 Clone 專案:
git clone git@github.com:langchain-ai/open-deep-research.git
cd open-deep-research
安裝依賴
建議使用虛擬環境,並安裝所有必要的套件。
python -m venv .venv
source .venv/bin/activate
# 安裝依賴
pip install -r requirements.txt
配置 API Keys
將 .env.example 檔案複製一份並改名為 .env。然後填入你的 API Keys。至少需要 OPENAI_API_KEY 和 TAVILY_API_KEY。
強烈建議也配置
LANGSMITH_API_KEY,以便在 LangSmith 上進行追蹤和除錯。
啟動 LangGraph Studio
LangGraph Studio 是一個內建的開發者 UI,可以讓你視覺化地看到 Agent 的運行流程。
langgraph dev
啟動後,你就可以在瀏覽器中打開 Studio 介面,與你的 Deep Research Agent 進行互動了。
你可以在 src/open_deep_research/deep_researcher.py 找到 Agent 的主要 LangGraph 實作,並自由地修改 Prompt 或 Agent 架構來滿足你的特定需求。
我認為 LangChain 的 Open Deep Research Agent 專案不僅僅是一個工具,它更像是一份由頂尖團隊親手撰寫的、關於如何打造複雜 Agent 的設計藍圖與實戰手冊。
最難能可貴的是,LangChain 不僅開源了程式碼,還非常慷慨地透過 YouTube 影片、部落格文章等形式,將其背後的設計哲學那些「為什麼」,毫無保留地分享出來。這讓這個專案的價值遠超過「複製貼上」。它為所有希望從簡單下 prompt 邁向真正 multi-agent 系統的開發者,提供了一條清晰的學習路徑,幫助我們真正踏入這個充滿挑戰與機遇的領域。
References:

