
一個響亮的聲音正在科技圈迴盪:「LLM Agent 時代來臨,人類不再需要學習軟體工程了!」這個論點極具誘惑力:當一個全能的 AI 助理可以根據你的自然語言需求,自動規劃、編寫、甚至執行程式碼時,我們何必還要去鑽研那些複雜的系統設計、演算法與資料結構呢?
然而,一個有趣且反直覺的現實正在浮現:當這些聰明的 Agent 真正進入大規模、生產級別的應用場景時,它們不僅沒有讓軟體工程變得多餘,反而讓那些最經典、最核心的工程原則變得前所未有的重要。
事實證明,AI Agent 並沒有消除複雜性,它只是將複雜性從「編寫確定性程式碼」轉移到了「管理和編排大量、具備自主性的非確定性組件」。而要駕馭這場由數百、數千個 AI Agent 共同上演的「混沌交響樂」,我們需要的恰恰是那些身經百戰的軟體架構師與工程師,以及他們工具箱裡那些永恆的設計原則:分散式系統、事件驅動架構、資料一致性、高內聚低耦合,以及對 CAP 定理的深刻理解。
這篇文章將帶你走過一段從單一 Agent 到大規模 Multi-Agent 系統的演進之旅,揭示為何那些看似「傳統」的軟體工程智慧,正是支撐起未來 AI 應用的基石。
想像一個獨立的 Agent,它就像一個全能的個人助理。你可以給它一個目標,比如「幫我規劃一趟為期五天的東京旅遊」,它會自主上網搜尋資料、比較價格、安排行程,最後給你一份完整的計畫。
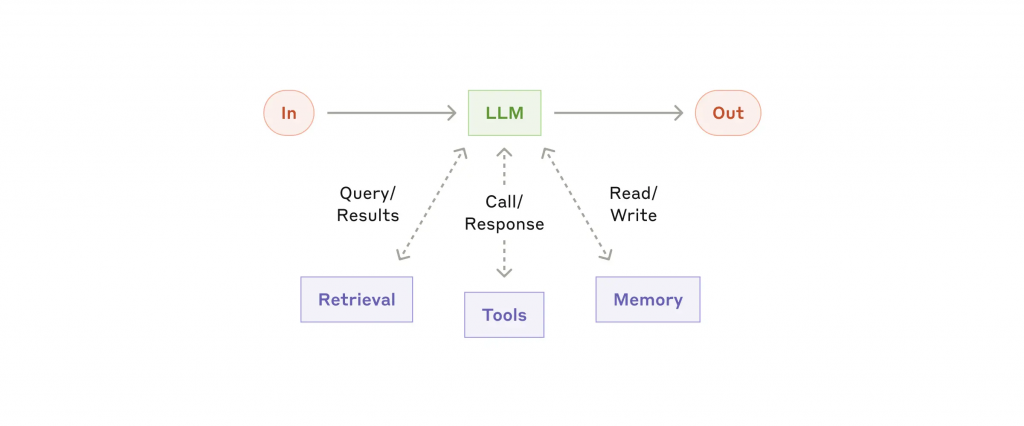
在單體(Monolithic)模式下,這個 Agent 的運作相對簡單:
這就像一個傳統的單體應用程式。它在初期功能強大、易於開發和理解。但當需求增加時,問題很快就暴露出來:
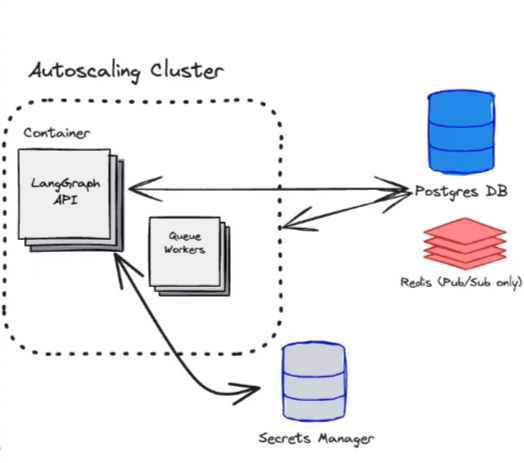
以上是 Langgraph 的架構設計,也可以看出他們一開始的目標從不只滿足於僅僅一個 Agent。
為了解決負載問題,最直觀的方案就是「水平擴展」,運行數百個一模一樣的旅遊規劃 Agent。這立刻引入了分散式系統的第一個經典挑戰:狀態管理。
每個 Agent 都需要存取對話歷史和用戶偏好。如果狀態儲存在各自的記憶體中,那麼用戶的下一個請求可能會被分配到一個完全「失憶」的 Agent 實例上。因此,我們必須將狀態外部化,使用像 Redis 或 Postgres 這樣的共享儲存。這正是傳統無狀態(Stateless)服務設計的核心思想。
此外,還需要一個負載均衡器(Load Balancer) 來有效地將請求分發到不同的 Agent 實例。看,才走了第二步,我們就已經踏入了傳統軟體架構的領域。
當任務變得極其複雜,例如「分析 IT S&P 500 成分股公司的所有董事會成員,並總結他們的背景與關聯」,僅僅增加 Agent 的數量是不夠的。這時,我們需要的是一支由不同專家組成的 Multi-Agent 團隊,這在概念上與微服務架構如出一轍。
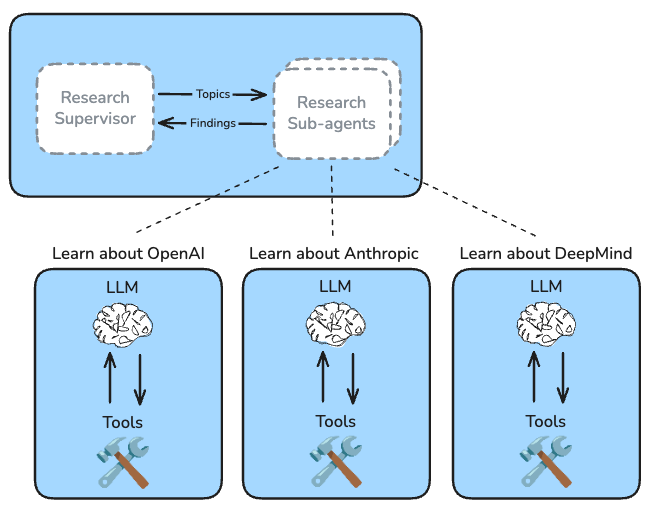
在這個新架構下,我們可能會有:
這種架構的優勢是巨大的:透過並行化,研究時間可以從數小時縮短到幾分鐘。然而,我們也親手打開了分散式系統的「潘朵拉的盒子」。
如果總指揮 Agent 直接透過 Reustful API 呼叫每一個研究員 Agent,並同步等待結果,系統將會變得極其脆弱和低效。這種緊耦合(Tight Coupling) 設計會導致任何一個研究員的延遲或失敗,都會阻塞整個流程,引發級聯故障。
| 協議 | 主要特點 | 優點 | 缺點 | 理想使用場景 |
|---|---|---|---|---|
| RESTful APIs | 基於 HTTP,文本格式 (JSON),無狀態,同步。 | 簡單,廣泛採用,人類可讀,與語言無關,適合公開的 API。 | 在高吞吐量下會有效能瓶頸,同步的特性不適合需要解耦的工作流程。 | Web 應用程式,外部 API,簡單的請求回應互動。 |
| gRPC | RPC 框架,二進位格式 (Protocol Buffers),HTTP/2,強型別,雙向串流。 | 高效能,高效率的序列化,強大的 API 契約,低延遲。 | 更複雜,人類可讀性較差,瀏覽器支援有限,學習曲線更陡峭。 | 內部服務之間的通訊,即時服務,行動應用程式。 |
| Message Queues | 非同步,訊息代理 (例如 AMQP),解耦的通訊。 | 卓越的解耦能力,更好的故障隔離,內建重試邏輯,高擴充性。 | 增加了事件模型的複雜性,需要額外的管理工具。 | 事件驅動架構,長時間執行的程序,背景任務,高彈性需求的關鍵系統。 |
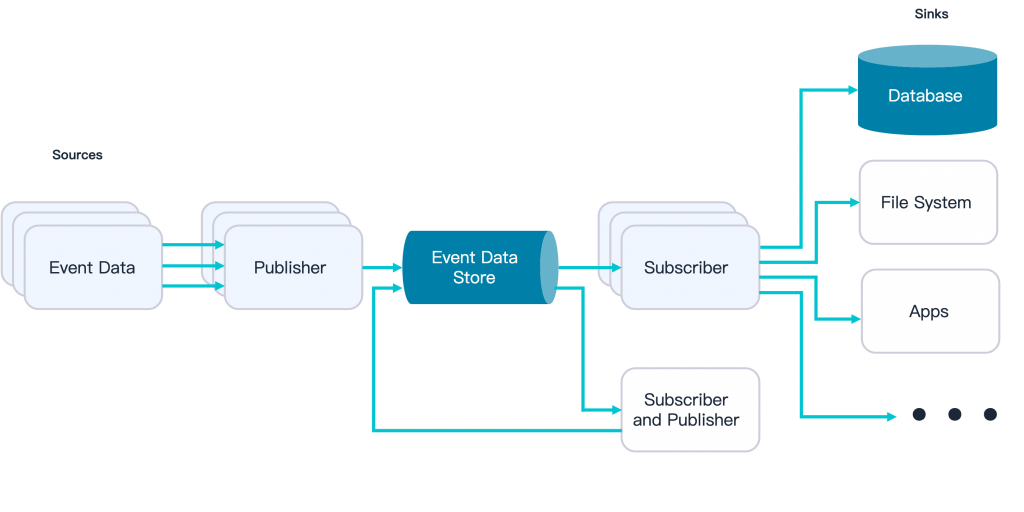
一個更優雅的設計是讓 Agent 之間透過非同步訊息進行溝通。
這種設計實現了完美的關注點分離。總指揮無需關心任務由誰執行、有多少執行者,它只負責發布任務。研究員也無需知道是誰發布的任務,它只專注於完成工作。這不僅提升了系統的彈性與韌性,也讓獨立擴展不同類型的 Agent 成為可能。
現在,想像一個電商場景的 Multi-Agent 系統:訂單 Agent、庫存 Agent、支付 Agent 和物流 Agent 協同工作。如果庫存 Agent 成功鎖定了庫存,但支付 Agent 卻失敗了,我們該怎麼辦?這就是經典的分散式事務問題。
傳統的解決方案如 二階段提交(Two-Phase Commit)因其同步阻塞特性,在這種大規模、高延遲的系統中難以適用。另一種常見的方式為 Saga 模式 將一個長流程分解為一系列由不同 Agent 完成的本地事務,並在失敗時執行對應的補償事務(Compensating Transaction) 來撤銷影響。
與傳統 Saga 模式依賴於複雜的事件監聽不同,LangGraph 透過其有狀態圖 (Stateful Graph) 的架構,將這個複雜的補償流程變得極為直觀和可靠:
透過這種方式,LangGraph 將 Saga 模式的複雜協調邏輯轉化為一個易於理解和維護的視覺化流程圖,同時提供了內建的容錯能力,確保了系統的最終一致性。這是對 CAP 定理(在網路分區的場景下,一致性、可用性、分區容忍性三者最多只能滿足其二)在現實業務中的深刻應用。
在我們讚嘆 Multi-Agent 架構的彈性與強大能力時,一個冰冷而現實的挑戰浮上水面:總營運成本 (TCO)。如果設計不當,一個看似高效的系統,其運營成本可能會失控,使其在商業上變得不可行。要理解這一點,我們必須先剖析成本的構成。
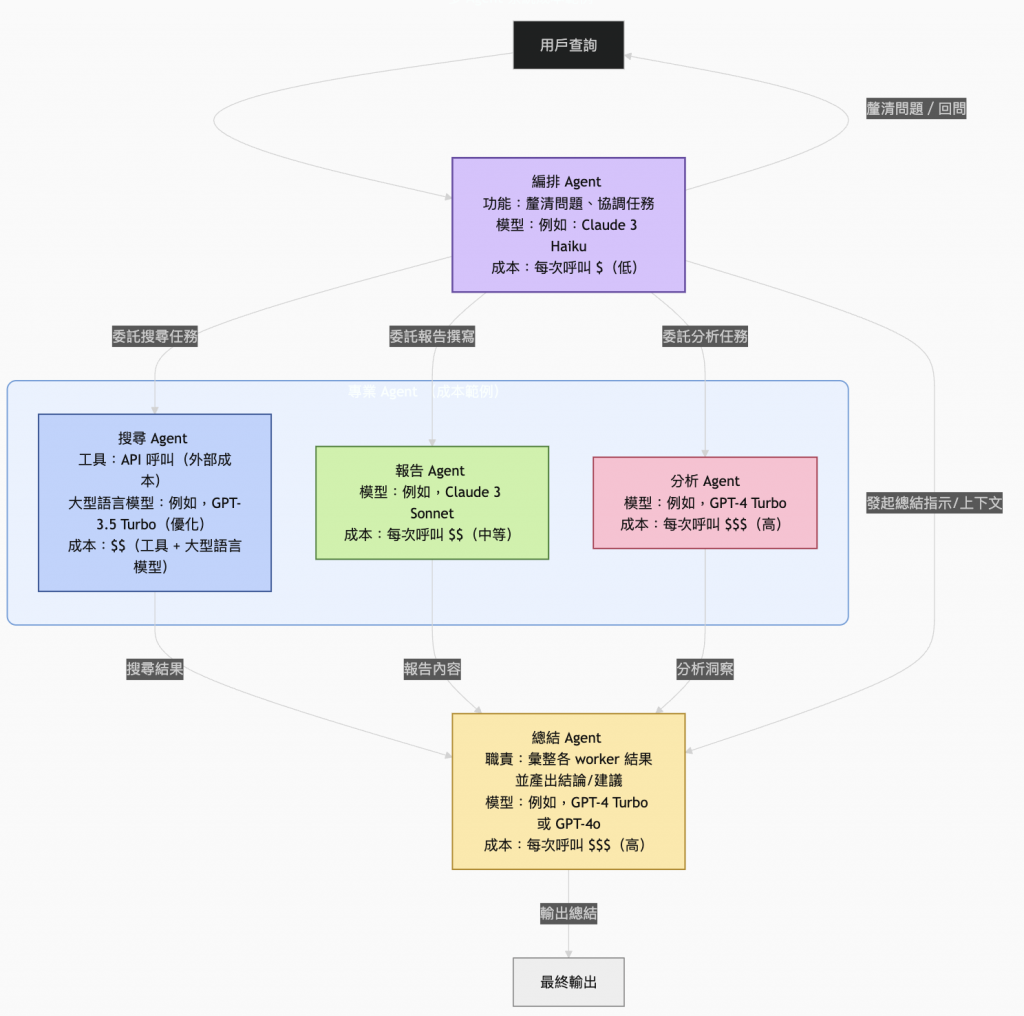
Multi-Agent 系統的總營運成本是多個組成部分的總和,並因智能體互動的分散特性而被放大:
在 Multi-Agent 系統中,這些因素會疊加放大。一個來自用戶的簡單請求,可能會觸發多個 Agent 之間的一連串 LLM 調用。每個 Agent 都在處理資訊、做出決策或為鏈中的下一個 Agent 重新組織資料。如果設計不夠仔細,一個中等複雜度的工作流程就可能因這种級聯效應而變得極其昂貴。
因此,設計一個具備成本效益的 Multi-Agent 系統,其核心不在於無限制地堆疊 Agent,而在於智能調度與分級處理。以下是一些關鍵的最佳實踐:
並非所有用戶請求都需要動用昂貴的專家 Agent 團隊。在系統入口處簡單的用 if-else 實作一個輕量級的規則引擎(Rule-Based Engine) 或引入一個小模型(例如 Claude Haiku、Llama 3 8B)作為「守門員 Agent」 是至關重要的第一道防線。
守門員 Agent 的另一個關鍵職責是選擇最經濟的執行路徑。一個重要的最佳實踐是:提早判斷任務複雜度,並動態匹配對應的執行器。
這種動態調度策略,避免了用「牛刀殺雞」,確保了計算資源的精準投放。
在多 Agent 團隊內部,也應貫徹成本效益原則。並非所有 Agent 都需要使用最強大、最昂貴的模型(如 GPT-5 或 Claude 4 sonnet)。
到目前為止,我們討論的挑戰在傳統微服務中也存在。但 LLM Agent 帶來了一個獨有的、更棘手的問題:非確定性(Non-determinism)。
傳統軟體是確定性的:給定相同的輸入,總是產生相同的輸出。而 LLM Agent 的核心是概率性的。同樣的任務,它這次可能完美完成,下次可能產生幻覺或陷入無限循環。這對系統的穩定性和可靠性提出了前所未有的挑戰。
經典解法在新時代的演化:
LLM Agent 的崛起,並不是軟體工程師的末日,反而可能是我們這些通靈師的光榮進化!
寫個簡單功能的程式碼,未來可能真的會被 AI 大量取代。但設計、構建和維運一個由成千上萬個非確定性 Agent 組成的、穩定、可靠且高效的龐大系統,這項任務的複雜性遠超以往。
未來的頂尖工程師,將不再是埋頭於實現細節的碼農,而是AI 系統的架構師。他們需要深刻理解分散式系統的陷阱、事件驅動架構的優雅、以及在 CAP 定理的約束下為複雜的 Agent 協作做出艱難的權衡。
AI 賦予了我們前所未有的強大「組件」,但將這些組件搭建成宏偉而穩固的大廈,依然需要人類工程師的智慧、經驗和遠見。那個「AI 會取代我們」的聲音或許會繼續,但現實是,這場革命比以往任何時候都更需要那些懂得如何為混沌建立秩序的架構師。
References:


 iThome鐵人賽
iThome鐵人賽