在 Day 14,我們學會了如何將 Notion 筆記切分 (Chunking),並且估算了 Embedding 成本。
接下來,要讓我們的筆記進入「語意檢索」的世界,就必須具備兩大基礎設施:
今天我們會一步步完成這兩件事,讓專案準備好進入「語意向量」的下一步。
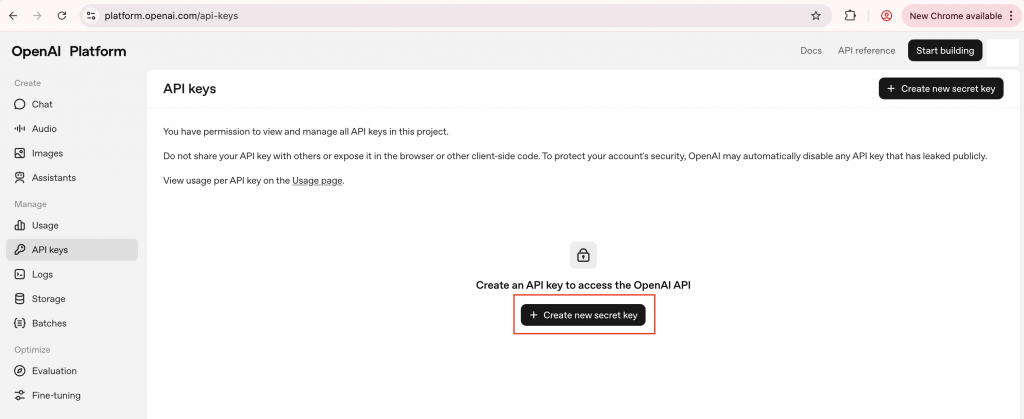
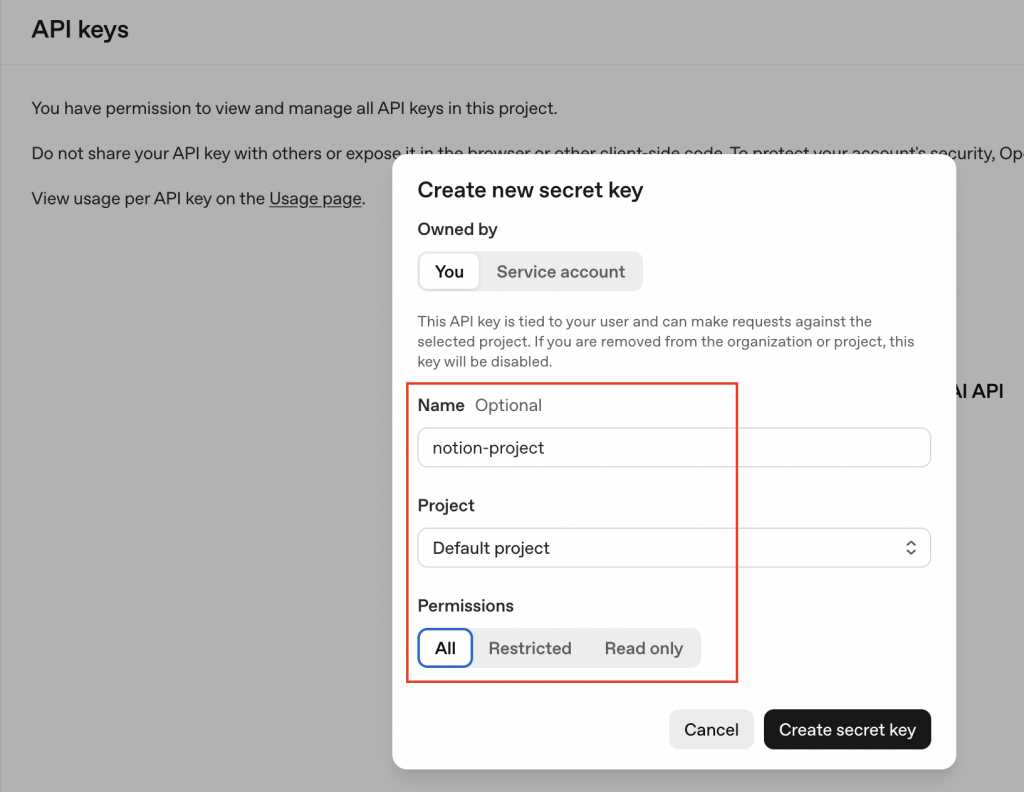
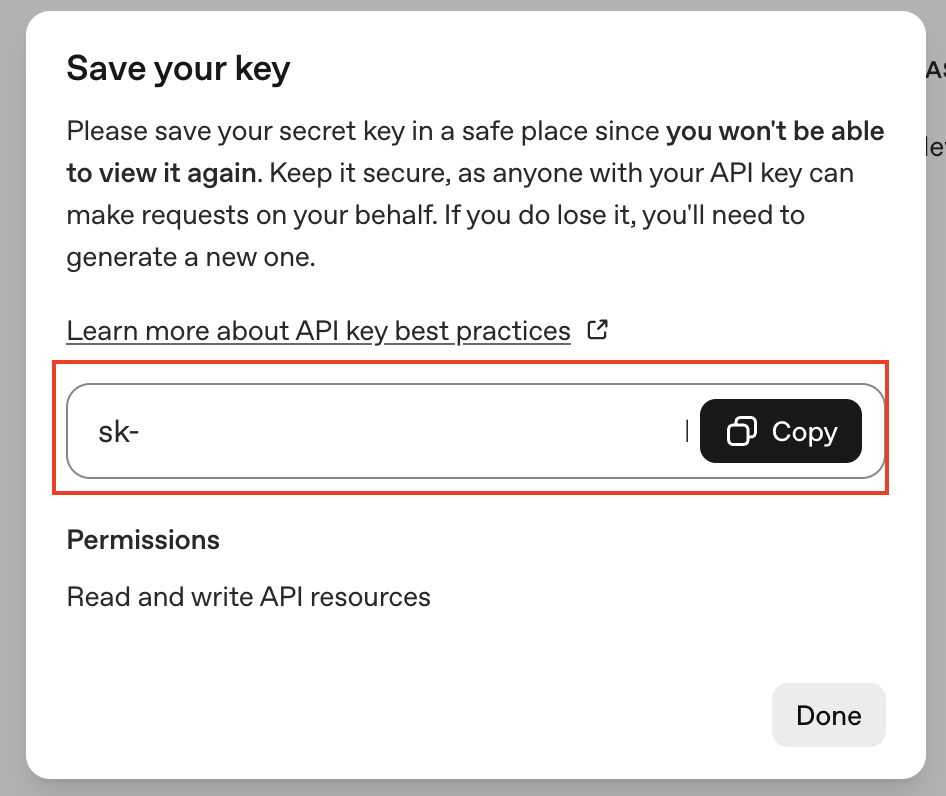
.env 檔案加上OPENAI_API_KEY:
OPENAI_API_KEY=sk-xxxxxxx
openai 套件,test_openai_key.py
import os
from openai import OpenAI
from dotenv import load_dotenv
# 載入 .env 檔案中的環境變數
load_dotenv()
try:
print("正在連線至 OpenAI API 並取得模型列表...")
# 初始化 OpenAI client,它會自動讀取環境變數
client = OpenAI(api_key=os.getenv("OPENAI_API"))
# 取得模型列表
models = client.models.list()
print("--- ✅ 連線成功!帳號可用的模型列表如下 ---")
# 逐一印出模型
for model in models:
print(f" • ID: {model.id:<30} | Created by: {model.owned_by}")
print("--------------------------------------------------")
except Exception as e:
print(f"❌ 發生錯誤:{e}")
print("請檢查 API Key 是否正確,以及帳戶是否有足夠的額度。")
正在連線至 OpenAI API 並取得模型列表...
--- ✅ 連線成功!帳號可用的模型列表如下 ---
• ID: gpt-3.5-turbo | Created by: openai
• ID: gpt-5-codex | Created by: system
• ID: gpt-5-nano-2025-08-07 | Created by: system
• ID: gpt-5-nano | Created by: system
• ID: gpt-audio-2025-08-28 | Created by: system
• ID: gpt-audio | Created by: system
• ID: davinci-002 | Created by: system
• ID: babbage-002 | Created by: system
• ID: gpt-3.5-turbo-instruct | Created by: system
• ID: gpt-3.5-turbo-instruct-0914 | Created by: system
• ID: dall-e-3 | Created by: system
...
在 【Day 12】向量化的準備:Embedding 與向量資料庫 中,我們介紹過 Chroma DB -- 一個開源、專為 AI 應用打造的向量資料庫:
pip install chromadb
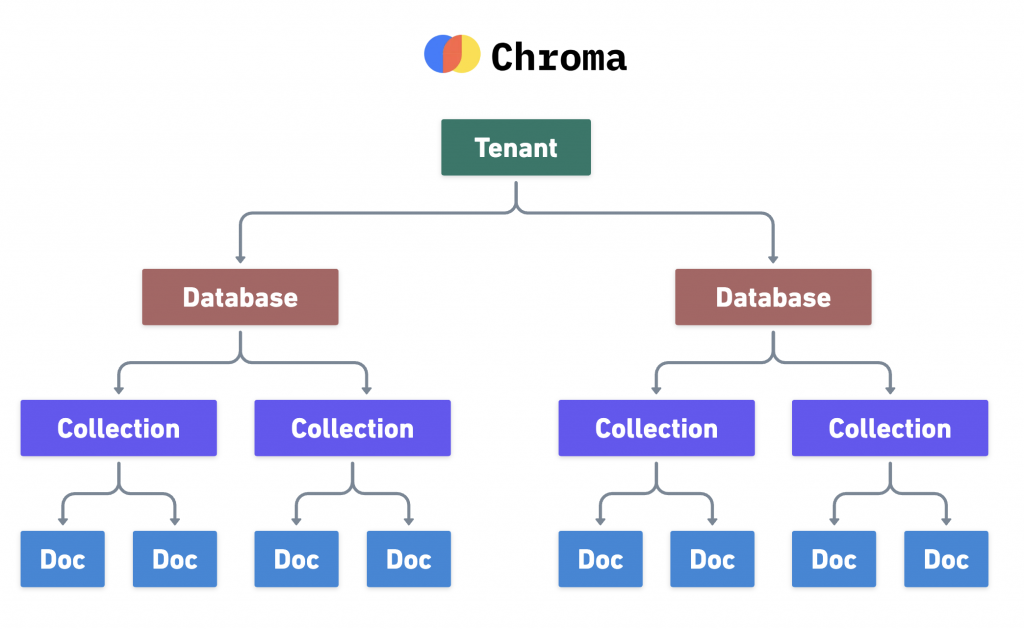
ChromaDB 以一個清晰、四層的階層架構來組織資料。在預設的單機模式下,所有這些資訊都被儲存在一個 SQLite 資料庫檔案中。
這個結構能有效地隔離與管理向量數據,從單一使用者到多租戶的應用都能應對。
import chromadb
# --- 1. 初始化 Chroma DB Client ---
# 我們使用 PersistentClient 來將資料儲存到硬碟上的指定路徑
# 這可以確保我們的向量資料庫在程式重啟後依然存在
db_path = "db/chroma_db"
client = chromadb.PersistentClient(path=db_path)
# --- 2. 建立或載入一個 Collection ---
# get_or_create_collection 會嘗試取得同名的 collection,
# 如果不存在,它會自動建立一個新的。避免重複建立。
collection_name = "my_notes_collection"
collection = client.get_or_create_collection(name=collection_name)
print(f"✅ Collection '{collection_name}' 準備就緒。")
print(f"目前 Collection 中有 {collection.count()} 筆資料。")
# --- 3. 新增資料到 Collection ---
# documents: 原始的文字內容
# metadatas: 與每段文字相關的「元數據」,例如來源、頁面ID等,這在RAG中極其重要!
# ids: 每段文字的唯一標識符
collection.add(
documents=[
"物件導向是一種程式設計方法,它將資料與行為包裝在一起。",
"類別就像是物件的設計藍圖,定義了物件的屬性與方法。",
"SQL 是一種用於管理關聯式資料庫的標準化查詢語言。",
"NoSQL 資料庫提供了比 SQL 資料庫更靈活的資料模型。"
],
metadatas=[
{"source": "cs101_notes", "page_id": "page_001"},
{"source": "cs101_notes", "page_id": "page_001"},
{"source": "db_notes", "page_id": "page_002"},
{"source": "db_notes", "page_id": "page_002"}
],
ids=["doc_001", "doc_002", "doc_003", "doc_004"]
)
print(f"✅ 新增了 4 筆資料。")
print(f"現在 Collection 中有 {collection.count()} 筆資料。")
# --- 4. 查詢 (Query) 資料 ---
# 這是 RAG 流程的核心,我們用自然語言來「查詢」最相關的筆記
results = collection.query(
query_texts=["什麼是物件導向?"],
n_results=2 # 指定回傳最相關的 2 筆結果
)
print("\n--- 查詢結果 ---")
print("問題:什麼是物件導向?")
# --- 5. 解析並印出結果 ---
for i, doc in enumerate(results['documents'][0]):
distance = results['distances'][0][i]
metadata = results['metadatas'][0][i]
print(f"\n結果 {i+1}:")
print(f" - 相似度 (距離): {distance:.4f}")
print(f" - 內容: {doc}")
print(f" - 元數據: {metadata}")
執行後,會看到類似以下的輸出:
✅ Collection 'my_notes_collection' 準備就緒。
目前 Collection 中有 0 筆資料。
✅ 新增了 4 筆資料。
現在 Collection 中有 4 筆資料。
--- 查詢結果 ---
問題:什麼是物件導向?
結果 1:
- 相似度 (距離): 0.3512
- 內容: 物件導向是一種程式設計方法,它將資料與行為包裝在一起。
- 元數據: {'source': 'cs101_notes', 'page_id': 'page_001'}
結果 2:
- 相似度 (距離): 0.4890
- 內容: 類別就像是物件的設計藍圖,定義了物件的屬性與方法。
- 元數據: {'source': 'cs101_notes', 'page_id': 'page_001'}
今天我們完成了兩個重要基礎建設:
在 Day 16,我們就可以把「Notion 筆記 → Embedding → 向量資料庫」的流程串接起來,將 Notion 筆記 chunks 送進 text-embedding-3-small 轉換成向量,並寫入 Chroma DB。

