
經過前 26 天對於 RAG 以及對於 LLMOps 的各面向的學習,終於來到實作以及驗收這個 RAG FAQ Chatbot 的階段。今天的目標就是在本機環境先驗收 FAQ Chatbot 的功能與效能,確保系統達到「可用」水準。
⚠️ 注意:今天的功能驗收是在 開發/本地環境 完成,真正的 產線環境配置將在 Day28 展示。
今天的專案一樣會放在 GitHub 上面,歡迎有興趣的人開 Issues、Fork ,或是直接在文章友善提問。
在 Day21–26,我們已經逐步完成了快取、Registry、安全檢查、Routing、觀測等模組。
今天(Day27) 的「開發」不是從零開始,而是把這些模組整合進同一個 API 服務,並驗證它們能共同運作
| 功能模組 | 實作方式 | 驗收對應 |
|---|---|---|
| API 層 | FastAPI Router (/ask, /healthz, /metrics) |
基本可用性、健康檢查 |
| 安全防護 | 輸入驗證、Rate Limiter | 錯誤阻擋、壓測時限流 |
| 檢索與重排序 | FAISS + CrossEncoder Reranker | 查詢正確性 |
| LLM 回答 | GPT-4o-mini | 答案合理性 |
| 結果快取 | In-memory / Redis | 快取命中率 |
| 觀測性 | Prometheus 指標 | 延遲、QPS、Token 成本 |
下圖展示了整個系統的架構:
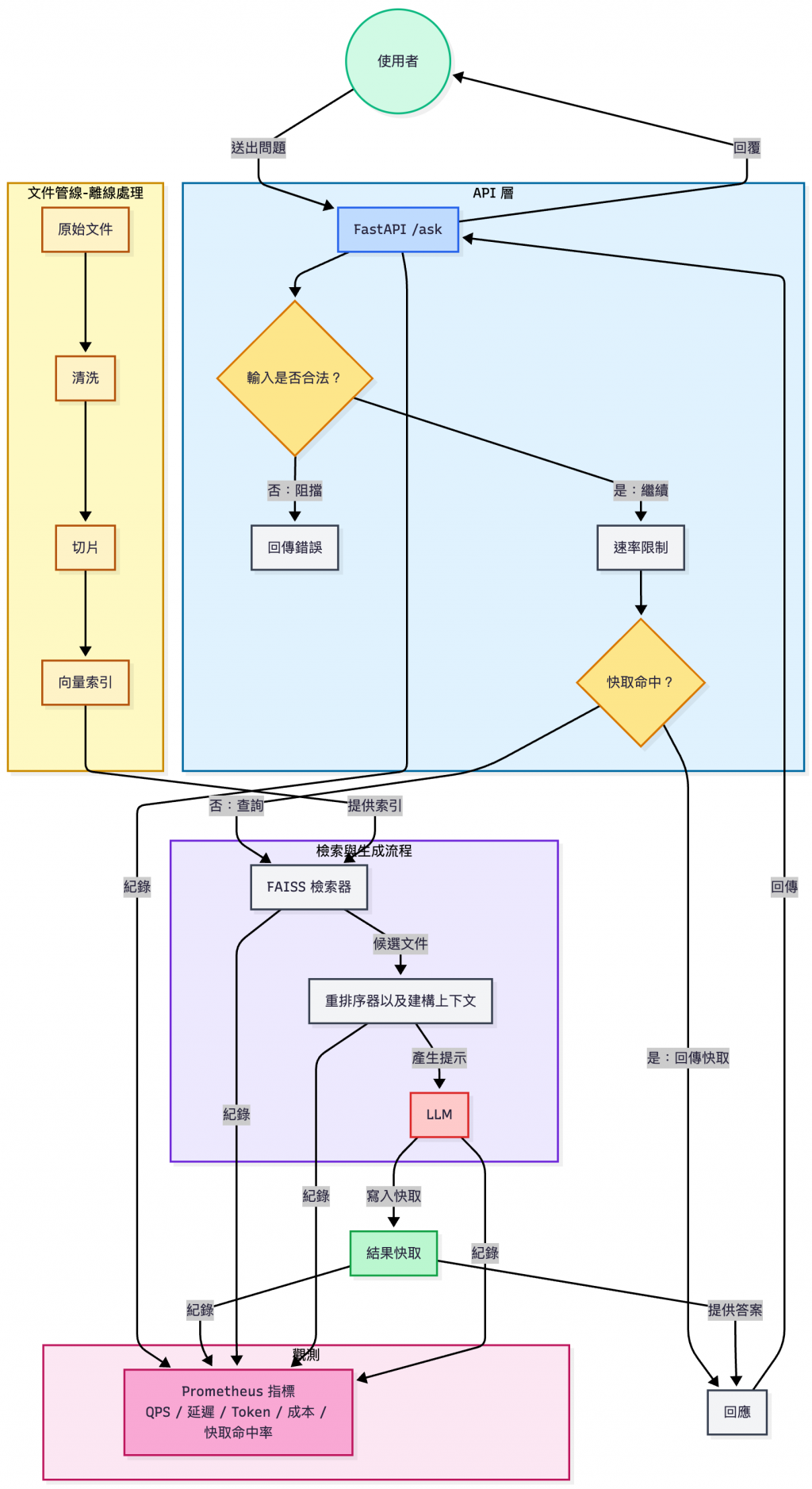
Day27 RAG FAQ Bot 系統架構圖
有了上面的整合清單與架構圖,我們可以確認:
Day27 的開發已經把前面所有模組(快取、安全、檢索、觀測…)都串接到一個完整的 FAQ Chatbot 中。
接下來的重點,就是要透過一系列 功能驗收與效能測試,確保這個系統不只是「寫出來」,而是真的能達到 可用水準。
text-embedding-3-small(OpenAI,低成本向量化)BAAI/bge-reranker-v2-m3(可切換其他的線上模型,此驗收使用前者),取前 Top-3 片段gpt-4o-mini(回答生成)| 項目 | 方法 / 工具 | 驗收標準 |
|---|---|---|
| 延遲測試 | ApacheBench / Locust;隨機選取 50 筆查詢,記錄 p50/p95 延遲 | API + Rerank:p95 ≤ 3s本機 Rerank:p95 ≤ 5s |
| 吞吐量測試 | Locust;模擬 10 位使用者並發查詢,持續 1 分鐘 | 平均 QPS ≥ 3,且 HTTP 5xx < 1% |
| 正確性測試 | pytest + 人工 spot check;FAQ 測資(三類問題:流程 / 客服 / 技術) | Top-1 準確率 ≥ 70% |
| 安全測試 | 測資:空查詢、SQL injection、SSRF / 內網 URL;檢查 metadata | 所有攻擊必須被阻擋,並在 metadata 記錄 |
| 成本測試 | 送出 100 筆 ≤300 tokens 查詢,統計 token 使用與成本 | 平均成本 < NT$0.2 / 次 |
| 可用性測試 | 本機模擬 crash(kill API process);觀察 systemd/docker-compose | 冷啟動恢復服務 < 30s |
| 觀測驗證 | Prometheus + Grafana 或瀏覽器 /metrics |
能看到延遲、QPS、快取命中率、Token/Cost、錯誤率 |
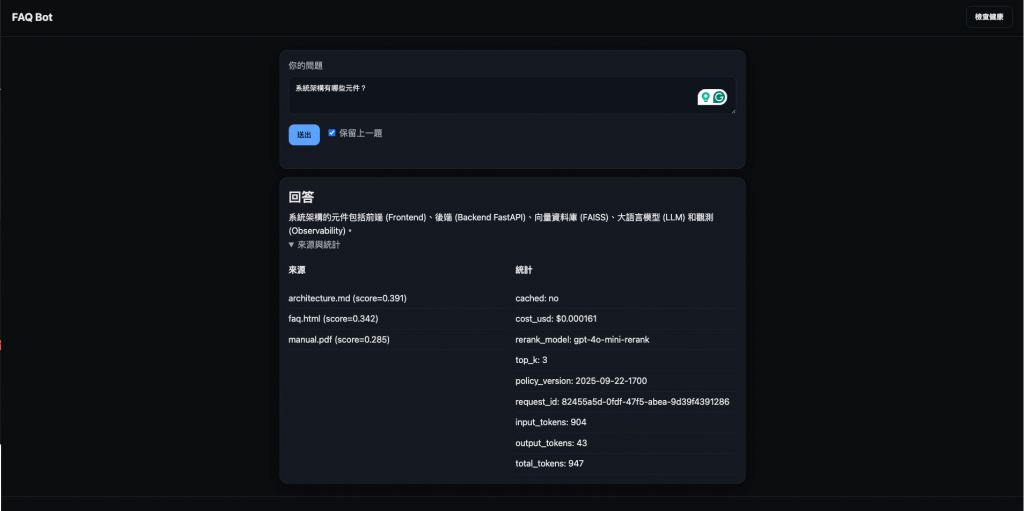
先打開前端介面,確認人類使用友善 👍
/data/raw/,舉例來說,manual.pdf 裡面大概長這樣: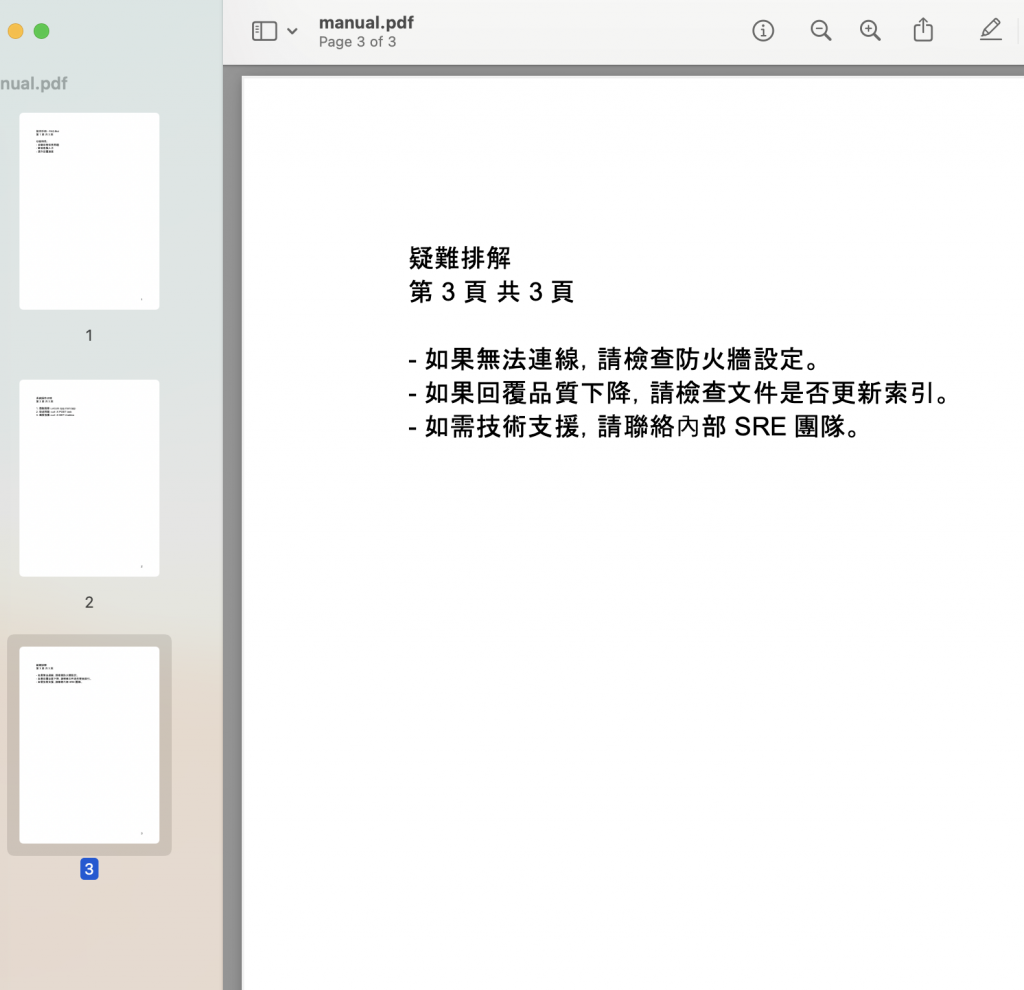
❯ tree ./
./
├── architecture.md
├── deploy.docx
├── faq.html
├── intro.txt
└── manual.pdf
python -m app.ingest.cli_ingest --input tests/data/docs --output tests/output
❯ python -m app.ingest.cli_ingest \
--input ./data/raw \
--out ./data/clean/chunks.jsonl
[ingest] CWD=/Users/hazel/Documents/github/rag-qa-bot/backend
[ingest] input_dir=/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw (exists=True)
[ingest] output=/Users/hazel/Documents/github/rag-qa-bot/backend/data/clean/chunks.jsonl (mode=file)
[ingest] loader found 5 docs by ext: {'.md': 1, '.txt': 1, '.docx': 1, '.pdf': 1, '.html': 1}
Ingest: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 3569.01it/s]
✅ Ingest 完成:檔案模式(直寫 .jsonl),共 5 個 chunks → /Users/hazel/Documents/github/rag-qa-bot/backend/data/clean/chunks.jsonl
index.faiss 和 docstore.jsonl
❯ python -m app.build_index \
--chunks ./data/clean/chunks.jsonl \
--docstore ./data/docs/docstore.jsonl \
--index ./data/docs/index.faiss
✅ build_index: docstore=data/docs/docstore.jsonl index=data/docs/index.faiss chunks=5 openai=yes faiss=yes
❯ ls -al ./data/docs
total 80
drwxr-xr-x@ 4 hazel staff 128 Sep 24 17:31 .
drwxr-xr-x@ 6 hazel staff 192 Sep 24 17:32 ..
-rw-r--r--@ 1 hazel staff 4553 Sep 25 14:50 docstore.jsonl
-rw-r--r--@ 1 hazel staff 30765 Sep 25 14:50 index.faiss
docstore.jsonl,確認內容有被清洗 & 切片❯ cat ./data/docs/docstore.jsonl | jq .
{
"id": "/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md::chunk-0",
"title": "architecture.md",
"text": "# FAQ Bot 系統架構設計 ## 整體流程 1. 使用者透過前端輸入問題 2. 問題經過向量化(Embedding) 3. 系統到向量資料庫檢索相似片段 4. 檢索到的內容會被拼接進 Prompt 5. 大語言模型 (LLM) 生成回答 6. 回答回傳給使用者 ## 元件細節 ### 前端 (Frontend) - 提供使用者輸入框與回覆區域 - 可內嵌在內部 Portal - 與 Backend API 溝通 ### 後端 (Backend FastAPI) - 提供 `/ask` API - 健康檢查端點 `/healthz` - 指標端點 `/metrics` - 整合快取、檢索與 LLM ### 向量資料庫 (FAISS) - 採用 L2 正規化後的內積檢索 - 儲存文件清洗與切片後的片段 - 提供 Top-k 查詢 ### 大語言模型 (LLM) - 使用 OpenAI GPT-4o-mini - 控制回答長度與溫度參數 - 回答中可引述來源 ### 觀測 (Observability) - 使用 Prometheus - 指標包含: - llm_requests_total - llm_request_latency_seconds - llm_tokens_total - llm_cost_total_usd",
"source": "/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md"
}
...
...
...
呼叫 /ask API,輸入典型問題(流程 / 客服 / 技術)
流程類(操作步驟 / 使用流程)提問:
❯ curl -s -X POST http://127.0.0.1:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "如何啟動 FAQ Bot 服務?"}' | jq .
{
"answer": "啟動 FAQ Bot 服務的方法是執行指令「uvicorn app.main:app」。",
"meta": {
客服類(常見 FAQ / 使用者疑問)提問:
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "這個系統能回答什麼?"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1712 100 1669 100 43 760 19 0:00:02 0:00:02 --:--:-- 779
{
"answer": "系統可以回答與公司內部知識庫相關的問題,例如系統架構、部署方式、操作手冊。",
"meta": {
"cached": false,
"context_preview":
...
技術類(部署、環境、開發相關)提問:
❯ curl -s -X POST http://127.0.0.1:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "建置 FAQ Bot 需要什麼環境?"}' | jq .
{
"answer": "建置 FAQ Bot 需要的環境包括能夠運行 uvicorn 的伺服器、能夠處理 HTTP 請求的 API 介面、以及用於監控的 Prometheus 和 Grafana。",
"meta": {
重複相同問題,觀察快取是否命中。可以看到如果問了重複的問題的話,cached 會變成 true:
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "這個系統能回答什麼?"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1711 100 1668 100 43 800k 21140 --:--:-- --:--:-- --:--:-- 835k
{
"answer": "系統可以回答與公司內部知識庫相關的問題,例如系統架構、部署方式、操作手冊。",
"meta": {
"cached": true,
"context_preview": "[faq.html] FAQ Bot 常見問題 常見問題集 Q1: 這個系統能回答什麼? A1: 系統可以回答與公司內部知識庫相關的問題,例如系統架構、部署方式、操作手冊。 Q2: 資料來源是什麼? A2: 所有答案都基於公司內部文件,例如 PDF 手冊、Word 檔案、HTML 文件。 Q3: 模型會記錄我的提問嗎? A3: 不會,系統只會暫存快取 300 秒,並不會長期保存提問。 Q4: 支援多語言嗎? A4: 是的,FAQ Bot 能同時
scores,應該是由大到小排序,並且取前 3 個 chunks 丟進 LLM。❯ curl -s -X POST http://127.0.0.1:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "LLM 相關指標包含哪些?"}' | jq .
{
"answer": "LLM 相關指標包含:llm_requests_total、llm_request_latency_seconds、llm_tokens_total、llm_cost_total_usd。",
"meta": {
"cached": true,
"context_preview":
....
,
"sources": [
{
"id": "/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md::chunk-0",
"title": "architecture.md",
"source": "/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md",
"score": 0.2665708065032959,
"reranker_score": 6.509603977203369. // <---- reranker_score
},
...,
...
],
"usage": {
"input_tokens": 970,
"output_tokens": 31,
"total_tokens": 1001
},
"cost_usd": 0.0001641,
"rerank_status": "ok",
"rerank_model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"top_k": 3,
"policy_version": "2025-09-22-1700",
"request_id": "ca4c173e-0749-4afe-90a7-5ec138394944"
}
}
如果檢索不到內容,會 fallback 並且回答「找不到相關資料」:
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "公司的客服聯絡方式是什麼?"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1515 100 1463 100 52 559k 20368 --:--:-- --:--:-- --:--:-- 739k
{
"answer": "資訊不足。",
"meta": {
"cached": true,
"context_preview": "[manual.pdf] 使用手冊 - FAQ Bot 第 1 頁 共 3 頁 功能特色: - 自動回答常見問題 - 節省客服人力 - 提升回覆速度 1 系統操作說明 第 2 頁 共 3 頁 1. 啟動服務:uvicorn app.main:app 2. 發送問題:curl -X POST /ask 3. 查詢指標:curl -X GET /metrics 2 疑難排解 第 3 頁 共 3 頁 - 如果無法連線,請檢查防火牆設定。 - 如果回覆品質下降,請檢查文件是否更新索引",
"sources": [
❯ tree ./app/tests -L 1
./app/tests
├── __pycache__
├── conftest.py
├── data
├── test_cache.py
├── test_e2e.py
├── test_eval_small.py
├── test_health.py
├── test_ingest.py
├── test_input_limits.py
├── test_loaders.py
├── test_perf_mocked.py
├── test_rate_limit.py
├── test_reranker.py
├── test_retrieval.py
└── test_routes.py
OpenAI )❯ pytest -m "not e2e and not perf and not eval"
============================================================== test session starts ===============================================================
platform darwin -- Python 3.11.13, pytest-8.4.2, pluggy-1.6.0
rootdir: /Users/hazel/Documents/github/rag-qa-bot/backend
configfile: pytest.ini
testpaths: app/tests
plugins: mock-3.15.1, anyio-4.10.0
collected 37 items / 5 deselected / 32 selected
app/tests/test_cache.py ... [ 9%]
app/tests/test_health.py ... [ 18%]
app/tests/test_ingest.py . [ 21%]
app/tests/test_input_limits.py ..... [ 37%]
app/tests/test_loaders.py .ssss [ 53%]
app/tests/test_rate_limit.py .. [ 59%]
app/tests/test_reranker.py ..... [ 75%]
app/tests/test_retrieval.py .. [ 81%]
app/tests/test_routes.py ...... [100%]
================================================================ warnings summary ================================================================
app/tests/test_ingest.py:7
/Users/hazel/Documents/github/rag-qa-bot/backend/app/tests/test_ingest.py:7: PytestUnknownMarkWarning: Unknown pytest.mark.ingest - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html
@pytest.mark.ingest
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
============================================= 28 passed, 4 skipped, 5 deselected, 1 warning in 4.25s =============================================
所有攻擊必須被阻擋,並在 metadata 記錄。
{ "query": "" }
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": ""}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 204 100 191 100 13 65143 4433 --:--:-- --:--:-- --:--:-- 99k
{
"error": "invalid_input",
"message": "Input rejected by policy.",
"meta": {
"type": "length",
"redacted": true,
"policy_version": "2025-09-22-1700",
"request_id": "cd044400-3b73-4c2d-8e76-950dc42078d3"
}
}
{ "query": "1 OR 1=1" }
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "1 OR 1=1"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 213 100 192 100 21 59590 6517 --:--:-- --:--:-- --:--:-- 71000
{
"error": "invalid_input",
"message": "Input rejected by policy.",
"meta": {
"type": "keyword",
"redacted": true,
"policy_version": "2025-09-22-1700",
"request_id": "0e3b8b4c-8387-4fad-a28c-1534d345b5c0"
}
}
{ "query": "http://127.0.0.1:8000/secret" }
❯ curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"query": "http://127.0.0.1:8000/secret"}' | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 229 100 188 100 41 82203 17927 --:--:-- --:--:-- --:--:-- 111k
{
"error": "invalid_input",
"message": "Input rejected by policy.",
"meta": {
"type": "url",
"redacted": true,
"policy_version": "2025-09-22-1700",
"request_id": "c08e1d3a-d871-4251-a6dd-791d216f2450"
}
}
meta 記錄(含 policy type / policy_version / request_id 等)✅人工評估 Top-1 準確率 ≥ 70%。
設定16個測試資料集(標準應該是要 50 條以上,但我們的原始資料不夠多):
{"question":"這個專案的願景是什麼?","answer":"協助企業將知識數位化,並透過 AI 技術提升內部資訊檢索的效率。","keywords":["知識數位化","AI","檢索效率"],"gold_source_id":"/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/intro.txt::chunk-0"}
{"question":"系統整體流程的前兩步是什麼?","answer":"1. 使用者透過前端輸入問題 2. 問題經過向量化(Embedding)","keywords":["輸入問題","向量化","Embedding"],"gold_source_id":"/Users/hazel/Documents/github/rag-qa-bot/backend/data/raw/architecture.md::chunk-0"}
...
...
總共十六條測試資料,涵蓋不同問題。
執行 AutoEval 回答品質測試(Day30 會詳細說明):
❯ pytest -m eval -s -vv
[cache] Using in-memory TTLCache (ttl=3600s)
============================================================== test session starts ===============================================================
platform darwin -- Python 3.11.13, pytest-8.4.2, pluggy-1.6.0 -- /opt/homebrew/Caskroom/miniforge/base/envs/rag_qa_bot/bin/python
cachedir: .pytest_cache
rootdir: /Users/hazel/Documents/github/rag-qa-bot/backend
configfile: pytest.ini
testpaths: app/tests
plugins: mock-3.15.1, anyio-4.10.0
collected 38 items / 37 deselected / 1 selected
app/tests/test_eval_small.py::test_eval_on_small_dataset
[eval] Top-1 source accuracy = 1.00 (16/16) | compare_level=doc
[eval] Text pass rate (Jaccard>=0.60) = 0.62 (10/16)
PASSED
================================================= 1 passed, 37 deselected, 2 warnings in 47.00s ==================================================
Top-1 來源回答正確性=100%(16/16)、文字相似度通過率=62%。✅
用現有的 eval_small 問題隨機抽 50 筆問題,並且允許重複:
❯ # 在 backend/
jq -r '.question' app/tests/data/eval_small.jsonl | shuf -r -n 50 > bench_queries.txt
❯ cat bench_queries.txt
向量資料庫採用什麼檢索方式並儲存什麼內容?
這個系統可以回答哪類問題?
...
寫一隻腳本逐筆做延遲測試,每一筆都不會用到快取,這個驗證主要是要看看加入 rerank 會不會讓延遲增加:
❯ sh ./benchmark/bench_latency.sh
== [Local Rerank] warm-up x3 ==
== [Local Rerank] sequential 50 requests ==
[01/50] sending...
progress: 1/50 (last=2.004729s code=200)
[02/50] sending...
progress: 2/50 (last=2.343764s code=200)
...
...
[49/50] sending...
progress: 49/50 (last=2.566958s code=200)
[50/50] sending...
progress: 50/50 (last=2.228147s code=200)
== [Local Rerank] stats (n=50) ==
n=50 ok=50 bad=0
p50=2.1235s p95=2.8477s
API+本機 Rerank(BAAI/bge-reranker-v2-m3)p95 ≈ 2.8477s,達標(≤ 3s)。✅
平均成本 < NT$0.2 / 次
用現有的 eval_small 問題隨機抽 100 筆問題,允許重複測試且不吃快取。
目的是為了驗證 最壞狀況 下沒有吃到快取的成本仍然在可以接受的範圍(NTD$ 0.2 / 一次查詢)內:
❯ ./benchmark/cost_bench.sh
[gen] wrote 100 queries to benchmark/cost_queries.txt
== [Cost Bench] sequential 100 requests (nocache) ==
[001/100] sending...
progress: 1/100 (code=200)
[002/100] sending...
...
...
progress: 98/100 (code=200)
[099/100] sending...
progress: 99/100 (code=200)
[100/100] sending...
progress: 100/100 (code=200)
[done] ok=100 bad=0 -> benchmark/cost_result.jsonl
==== Cost Summary ====
queries_file : benchmark/cost_queries.txt
results_file : benchmark/cost_result.jsonl
n/ok/bad : 100/100/0
fx (NTD/USD) : 32.0
total_usd : 0.015570
avg_usd : 0.000156
avg_ntd : 0.005
avg_tokens : 966.8
ACCEPT(avg_ntd<0.2): PASS
pct(total_tokens ≤ 300): 0.0%
這隻腳本的匯率會用 NTD:USD = 32:1 的匯率去換算。
成本:avg_ntd = NT$0.005/次(fx=32),✅ 小於 0.2。
token:目前 avg_tokens ≈ 967(❌ 未達 ≤300),不過這算是設計假設,所以以成本的角度而言仍然是通過驗證條件的。
後續可以採取的行動:採用「token 預算式 Context 組裝」+「RERANK_TOP_K=2」+「System Prompt精簡」,預期把 avg_tokens 拉到 ≤ 300,成本將進一步降到 ≈ NT$0.002–0.003/次。
/healthz 200)必須 < 30 秒# 啟動 app
❯ uvicorn app.main:app --host 127.0.0.1 --port 8000 --workers 1
# 在另外一個終端機 Shell 確認健康檢查通過
❯ curl -sf http://127.0.0.1:8000/healthz && echo READY
{"status":"ok"}READY
# 開一個新的 shell,找到 uvicorn process PID:
❯ ps aux | grep "uvicorn app.main:app" | grep -v grep
hazel 12158 13.0 1.2 416578112 309328 s014 U+ 6:45PM 0:02.93 /opt/homebrew/Caskroom/miniforge/base/envs/rag_qa_bot/bin/python /opt/homebrew/Caskroom/miniforge/base/envs/rag_qa_bot/bin/uvicorn app.main:app --host 127.0.0.1 --port 8000 --workers 1
# 記錄下上面的 PID - 12158,執行另一支腳本紀錄從 kill process 到回復的時間
❯ sh ./benchmark/crash_bench.sh
[cache] Using in-memory TTLCache (ttl=3600s)
INFO: Started server process [12253]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:59625 - "GET /healthz HTTP/1.1" 200 OK
cold start = 6s
/healthz 回 200
平均 QPS ≥ 3,且 HTTP 5xx < 1%
工具:Locust
模擬條件:
-u 10,每秒啟動 1 位 -r 1)指令:
❯ locust -f benchmark/locustfile_cache.py \
--headless -u 10 -r 1 --run-time 1m \
--host http://127.0.0.1:8000 \
--csv benchmark/locust_cache --only-summary
[2025-09-25 19:24:58,768] hazel/INFO/locust.main: Starting Locust 2.40.5
[2025-09-25 19:24:58,769] hazel/INFO/locust.main: Run time limit set to 60 seconds
[2025-09-25 19:24:58,770] hazel/INFO/locust.runners: Ramping to 10 users at a rate of 1.00 per second
[2025-09-25 19:25:07,797] hazel/INFO/locust.runners: All users spawned: {"RAGUser": 10} (10 total users)
[2025-09-25 19:25:58,622] hazel/INFO/locust.main: --run-time limit reached, shutting down
[2025-09-25 19:25:58,671] hazel/INFO/locust.main: Shutting down (exit code 0)
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /ask (cached) 1868 0(0.00%) | 171 0 14761 3 | 31.21 0.00
--------|--------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 1868 0(0.00%) | 171 0 14761 3 | 31.21 0.00
Response time percentiles (approximated)
Type Name 50% 66% 75% 80% 90% 95% 98% 99% 99.9% 99.99% 100% # reqs
--------|------------------------------------------------------------------|--------|------|------|------|------|------|------|------|------|------|------|------
POST /ask (cached) 3 4 5 5 6 8 3300 5400 14000 15000 15000 1868
--------|------------------------------------------------------------------|--------|------|------|------|------|------|------|------|------|------|------|------
Aggregated 3 4 5 5 6 8 3300 5400 14000 15000 15000 1868
| 指標 | 數值 | 驗收標準 | 結論 |
|---|---|---|---|
| 總請求數 | 1868 | - | - |
| 測試時間 (s) | 60 | - | - |
| 平均 QPS | 31.2 | ≥ 3 | ✅ |
| 失敗率 (5xx / 429) | 0.00% | < 1% | ✅ |
| p50 延遲 | 3 ms | - | - |
| p95 延遲 | 8 ms | - | - |
| 最長延遲 (max) | 15,000 ms | -(僅極少數 outlier) | ⚠️ 少數長尾 |
吞吐量驗收 ✅
指標來源:
/metrics 端點,Prometheus pull。app/observability.py。工具:
observability/dashboards/faq-bot-overview_v2.json
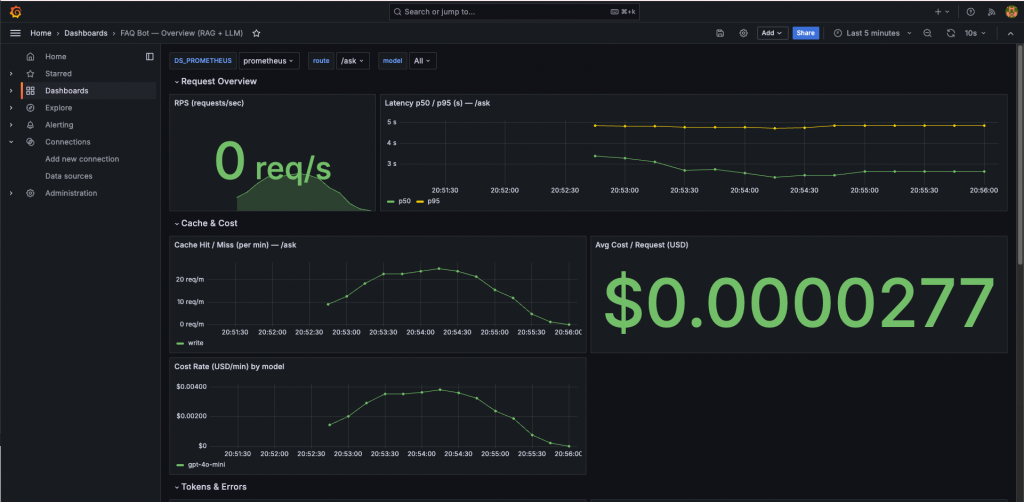
Metrics:
llm_request_latency_seconds(Histogram, label=route)rag_embedding_latency_seconds(Histogram, label=stage)rag_retrieval_latency_seconds(Histogram)rag_rerank_latency_seconds(Histogram)rag_llm_latency_seconds(Histogram, label=model)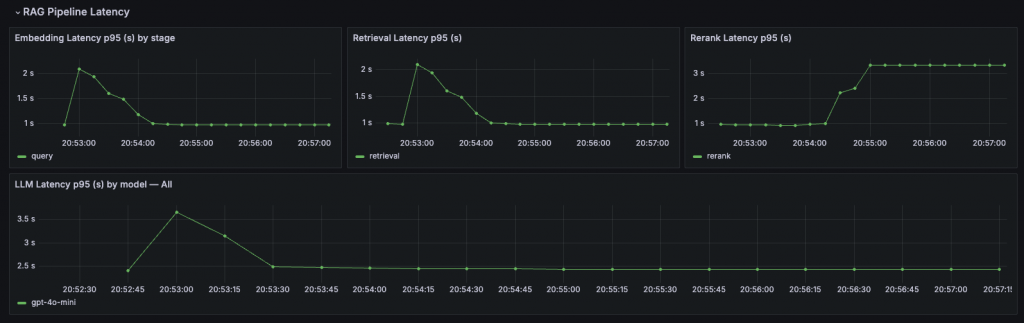
llm_requests_total(Counter, labels=route,status)
rag_cache_requests_total(Counter, label=route)rag_cache_results_total(Counter, labels=route,result)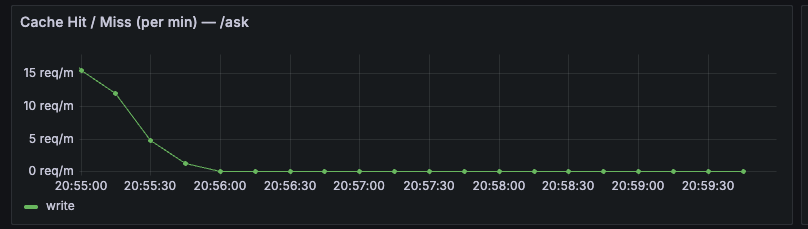
llm_tokens_total(Counter, labels=kind,model)llm_cost_total_usd(Counter, label=model)
rag_errors_total(Counter, label=stage)llm_requests_total{status="error"}(Counter)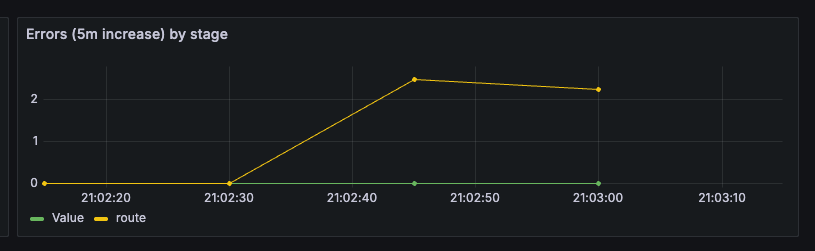
後續可以做的加強:
- 可補上 p99 延遲 與 每請求成本直方圖(Histogram bucket 1e-5~1e-2)。
- 對「錯誤率」再分
5xx / 4xx,方便區分限流 vs 系統異常。- 為
REQUEST_COUNT細分success / client_4xx / server_5xx,並在面板新增「Error Rate by class」對比圖
| 項目 | 方法 / 依據 | 驗收標準 | 結果 |
|---|---|---|---|
| 延遲(序列 50 筆、不中快取) | bench_latency.sh |
p95 ≤ 3s(API+Rerank)/ ≤ 5s(本機 Rerank) | p95≈2.85s(本機 BAAI/bge-reranker-v2-m3)PASS |
| 吞吐量(1 分鐘、10 並發) | Locust(命中快取場景;rate limit 關閉) | 平均 QPS ≥ 3 且 5xx < 1% | QPS≈31.2、失敗率 0.00% PASS |
| 成本(100 筆、≤300 tokens 目標) | cost_bench.sh |
avg_ntd < 0.2/次 | avg_ntd≈0.005(fx=32)PASS;avg_tokens≈967(>300,僅成本達標) |
| 安全性(空查詢/SQLi/SSRF) | 直接打 /ask |
全擋、含 metadata | 全擋,400/metadata 完整 PASS |
| 可用性(crash→恢復) | crash_bench.sh(uvicorn) |
冷啟動 < 30s | cold start=6s PASS |
| 觀測(Grafana/PromQL) | 匯入儀表板 + Explore | 可見 延遲/QPS/快取/Token/Cost/錯誤 | 面板完整可視化 PASS |
| 正確性(子集評估) | pytest -m eval |
Top-1 ≥ 70% | Top-1=100%(16/16);文字相似度通過率 62% |
| 類別 | 工作項目 | 動作 | 實作要點 | 驗收方式 |
|---|---|---|---|---|
| Tokens/成本 | Prompt 精簡 | 移除冗語、限制輸出長度 | 系統提示改條列,回答 ≤300 tokens | 100 筆 eval 平均 tokens ≤300 |
| Tokens/成本 | Context 預算器 | 動態計算 query+prompt token,依 budget 截斷 context | 保留高分片段,優先含標題 | eval 不超過 budget,正確率不降 |
| 吞吐量/效能 | 關閉快取壓測 | Locust 測試非快取情境 | 10 並發 1 分鐘,報告 QPS、p95 | QPS ≥3(無快取基準) |
| 吞吐量/效能 | Rate limit On/Off 壓測 | 開關限流各跑一輪 | 產出兩組報告(標註 On/Off) | 區分 429 與真實效能 |
| 可靠性/錯誤率 | REQUEST_COUNT 細分 | status 拆成 success / 4xx / 5xx | Counter 新增三類標籤 | /metrics 有效區分 |
| 可靠性/錯誤率 | rag_errors_total 全覆蓋 | cache/embedding/retrieval/rerank/llm/route 全部分支 inc | 模擬錯誤驗證每個 stage | 觀測到不同標籤錯誤 |
| 觀測告警 | p95 延遲告警 | 加入規則:/ask p95>3s(5m) |
Grafana Alert 規則 | 模擬高延遲能觸發 |
| 觀測告警 | 快取命中率告警 | hit ratio<80%(5m) |
人工製造 miss 驗證 | 觸發告警 |
| 觀測告警 | 5xx 告警 | 5xx>0(1m) |
模擬 LLM API 失敗 | 觸發告警 |
| 可用性 | 自動重啟 | systemd/docker-compose restart: always | kill 進程後自動拉起 | 服務恢復 ≤30s |
| 可用性 | /healthz 細化 | 回報 cache/index/LLM/rerank 狀態 | 探針失敗時 503 + 詳細 meta | K8s/ALB 能正確摘除 |
Day27 完成驗收後,FAQ Bot 已具備「功能可用性」。延遲、吞吐量、快取命中率、成本與可用性均達標,最小可行系統(MVP)已建立。
整體來說,FAQ Bot 能在本地環境穩定運作並通過驗收。
接下來的挑戰,不只是「能不能用」,而是「如何在更真實的環境中維持穩定與安全」。
這就是我們在 Day28 要面對的課題。
