在過去幾天的章節中,我們逐步建立起一套可觀測、安全可靠、有效率的 LLM 應用基礎:
在這些基礎之上,今天我們要進一步思考如何系統性地把 推理成本[註1] 壓下來。
[註1] 推理成本 = 讓大語言模型(LLM)執行一次推理(inference),從輸入到產生輸出的過程中,所需要消耗的各種資源與金錢 = 每次「問模型 → 得到答案」所花的錢 + 資源。
雖然單就 LLM 的觀點,我們可以知道:
每次推論請求(Inference Request)的成本 ~= PromptTokens * 單價_in + CompletionTokens * 單價_out
但實際上:
總成本 = 所有推論請求成本之和 +(檢索、工具、資料搬運、資料庫等基礎架構等間接成本)
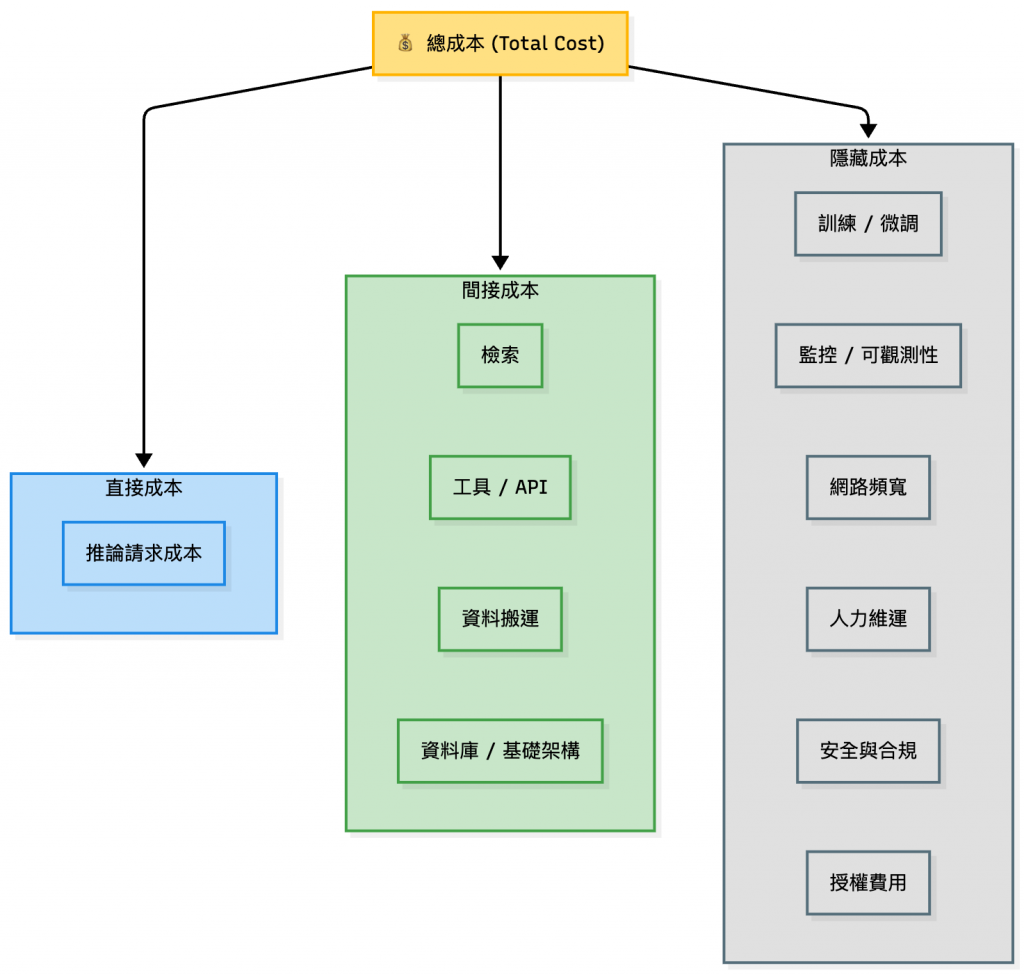
以上面這張圖來說,可以舉例幾個常見成本變多的情境:
這其實和 SRE 工作上常見到的費用浪費情境很像:
Images 或是 artifacts 沒用 build cache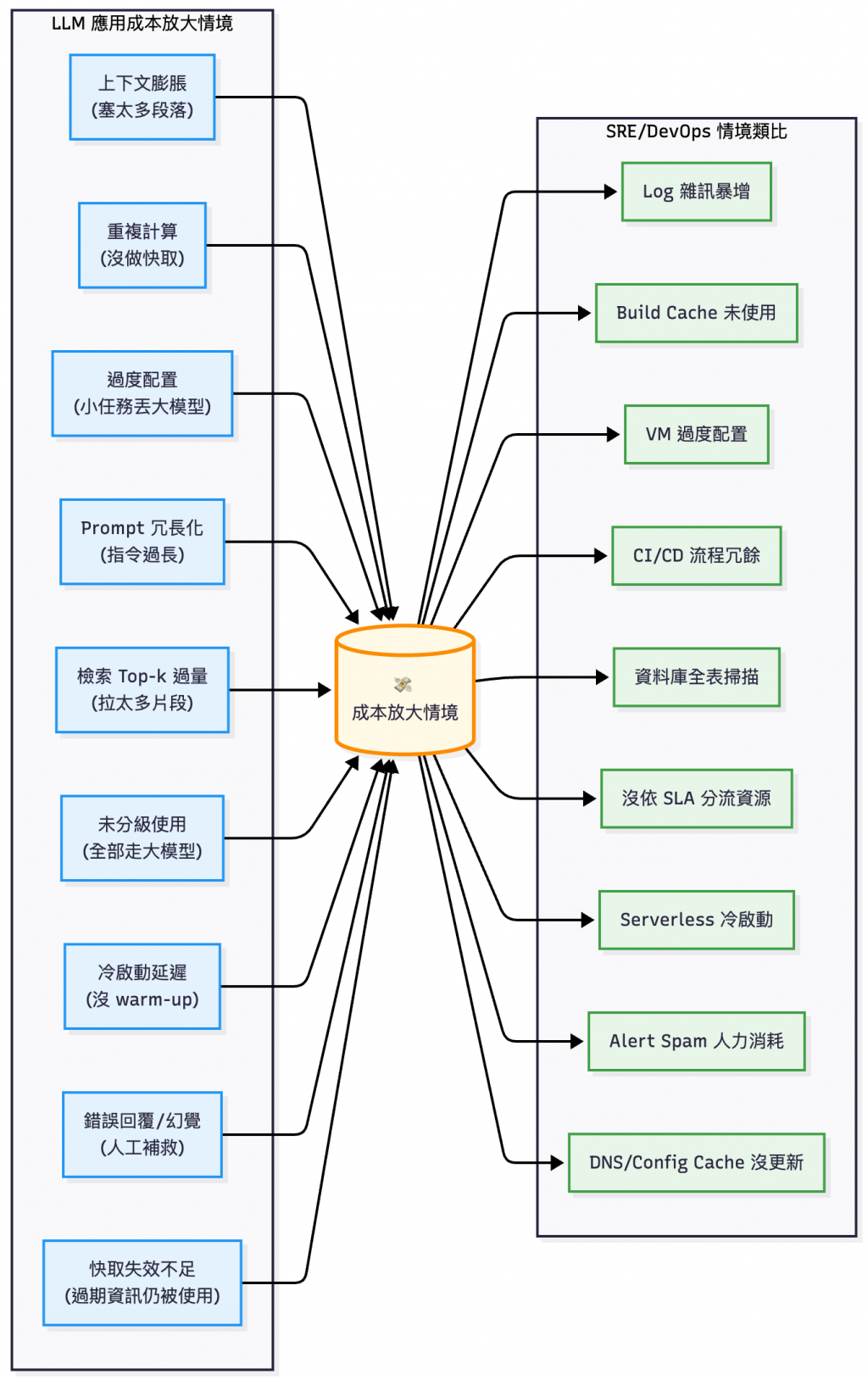
所以在評估成本時,需要以系統設計的想法去檢視各個層面的費用。
在討論具體改善手段之前,我們需要先釐清「成本」的全貌。這裡可以借用 Economic Evaluation of LLMs (2025) [註1]的觀點,把 LLM 應用成本 拆成三個層級:
商業層(Business Impact)
系統層(System Cost)
請求層(Request Cost)
PromptTokens * 單價_in + CompletionTokens * 單價_out)根據上面小節提到的成本評估框架來分析本次鐵人賽最常提到的情境 - FAQ,可以看到能夠採取的行動有離線生成(Offline Precompute)、快取以及路由。
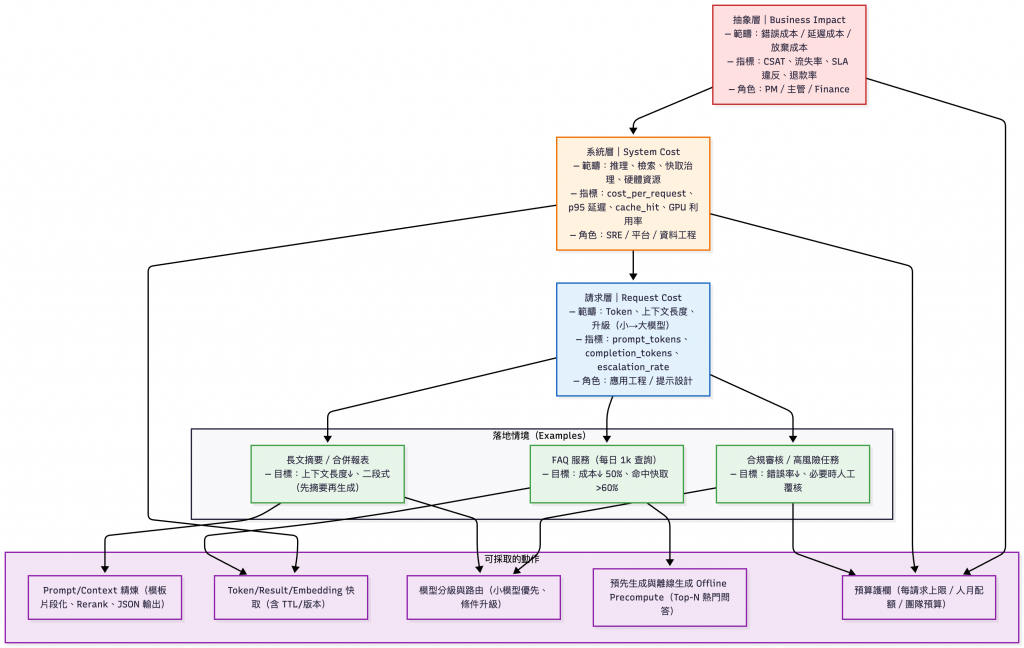
在深入節省步驟介紹之前,如果團隊時間有限,可以先專注在這三個「高 CP 值」改善項目:
| 優先級 | 改善項目 | 實施難度 | 預期效果 | 如何驗證 | 對應本系列鐵人賽文章 |
|---|---|---|---|---|---|
| P0 | Result Cache對重複查詢做指紋快取 | ⭐⭐(Redis + hash 即可) | • FAQ 場景命中率 60-80%• 成本降低 30-50%• 延遲從 2-3s → 50-200ms | 追蹤 result_cache_hit_rate |
- Day21 - LLM 應用快取實戰:成本改善 × 加速回應 |
| P1 | RAG 精簡輸入Top-k 從 10 降至 2-3 + Reranker | ⭐⭐⭐(需調整檢索邏輯) | • Prompt tokens 降低 40-60%• 每次查詢省 NT$0.03-0.05 | 追蹤 avg_prompt_tokens |
- Day10 - RAG 查詢實作:Retriever+Reranker 與模型評測- Day11 - 上下文組裝(Context Assembly):實測四種策略,讓 LLM「讀得懂又省錢」 |
| P2 | Small-First 路由簡單問題丟小模型 | ⭐⭐⭐⭐(需建分類器) | • 50% 查詢走小模型• 整體成本降低 20-35% | 追蹤 escalation_rate 保持在 10-30% |
- Day24 - LLM 應用分流:用任務分類做到省錢可靠 |
實施順序建議:
為什麼是先做這三項?
LLM 的計價方式幾乎都與 Token 數量 直接掛鉤,因此「上下文精煉」往往是最能立刻見效的降本手段。
chunk_size 與 top_k,先用 reranker 排序,再只餵給模型最相關的 2–3 段,而不是整包丟進去。 (Day10 的文章有提到)[註2]💡 在進 LLM 之前本機估算 token 數量,超過閾值就走降階方案(改用較小模型 / 縮短上下文 / 轉人工處理)。
[註1] A Practical Guide to Reducing Latency and Costs in Agentic AI Applications
[註2] Chunking for RAG: best practices
[註3] Learning to Generate Structured Output with Schema Reinforcement Learning
[註4] LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
許多 LLM 應用的高額成本來自「重複計算」。快取策略的核心概念是:對重複的上下文片段或查詢做指紋 (hash),命中後直接重用,不必再重新推理或計算。
hash(full_prompt) 為 Key,命中後直接回傳答案,特別適合 FAQ 或重複查詢。hash(text),避免重複生成向量嵌入,對文件更新率低的情境尤其有效。[註3]💡 實務上可以追蹤 token_cache_hit_ratio、result_cache_hit_ratio 等指標。快取命中率越高,延遲與成本都會同步下降。
部分可以參考
Day21 - 快取機制(Caching)— 回應加速與重複檢索成本改善的實作
[註1] PROMPT CACHE: MODULAR ATTENTION REUSE FOR LOW-LATENCY INFERENCE
[註2] GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching
[註3] Advancing Semantic Caching for LLMs with Domain-Specific Embeddings and Synthetic Data
不同任務對延遲、品質、成本的需求不同,一律丟大模型(LLM)會造成浪費。Hybrid 路由就是讓「簡單任務交小模型(Lightweight Model)、複雜任務交大模型」,同時保證品質與效率。
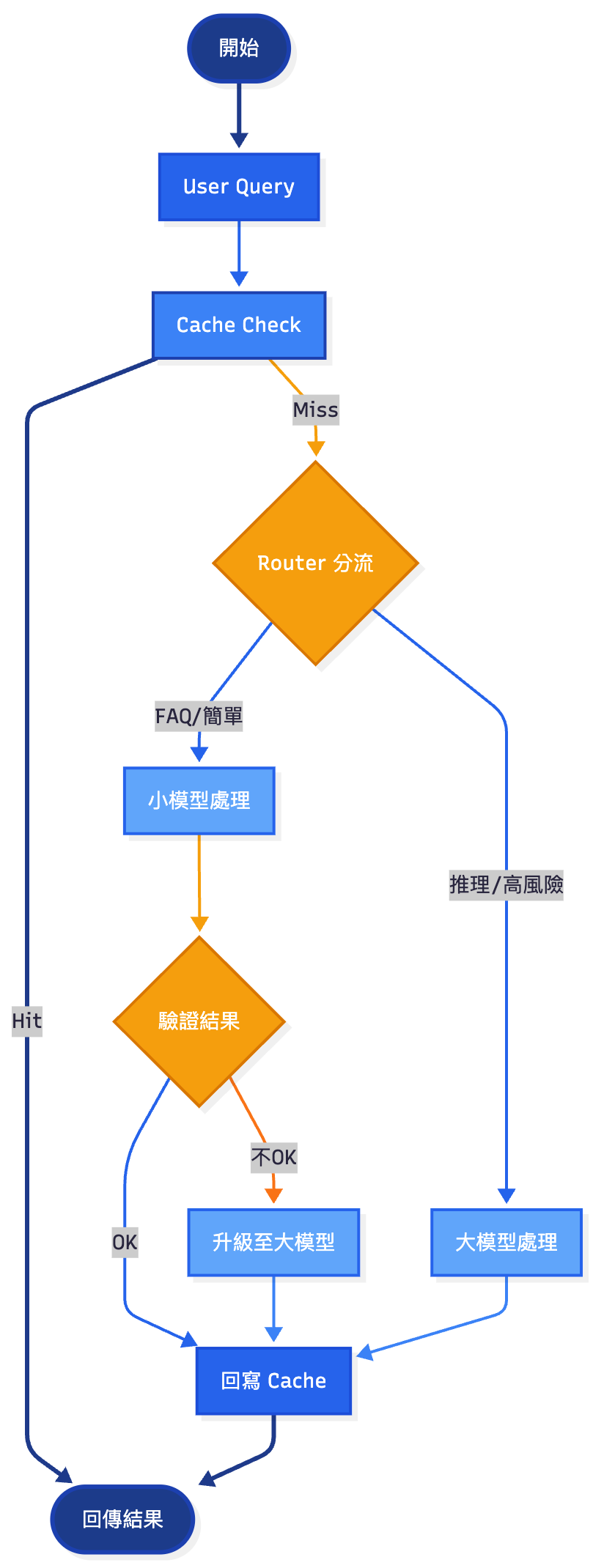
路由系統流程圖
💡 觀測上可追蹤 escalation_rate(升級比例)、route_success_rate(正確路由率),來評估成本與品質平衡。
[註1] Deploying LLMs Across Hybrid Cloud-Fog Topologies Using Progressive Model Pruning
[註2] LLM Semantic Router: Intelligent request routing for large language models
[註3] Cascadia: A Cascade Serving System for Large Language Models
在許多應用場景中,不必所有內容都即時生成。把「重複、常見、可預測」的部分先處理好,就能省下大量 Token 成本並加快回應。
Top-N 常見問題,離線生成標準答案並存到 KV Store / Redis。命中時直接回傳。這個方法成本趨近於零,回應速度也快一個數量級,重點是這個方法也是最快見效的。[註1]Token 消耗。這類工作離線處理一次,線上就能反覆受益。(Day08 的文章有提到)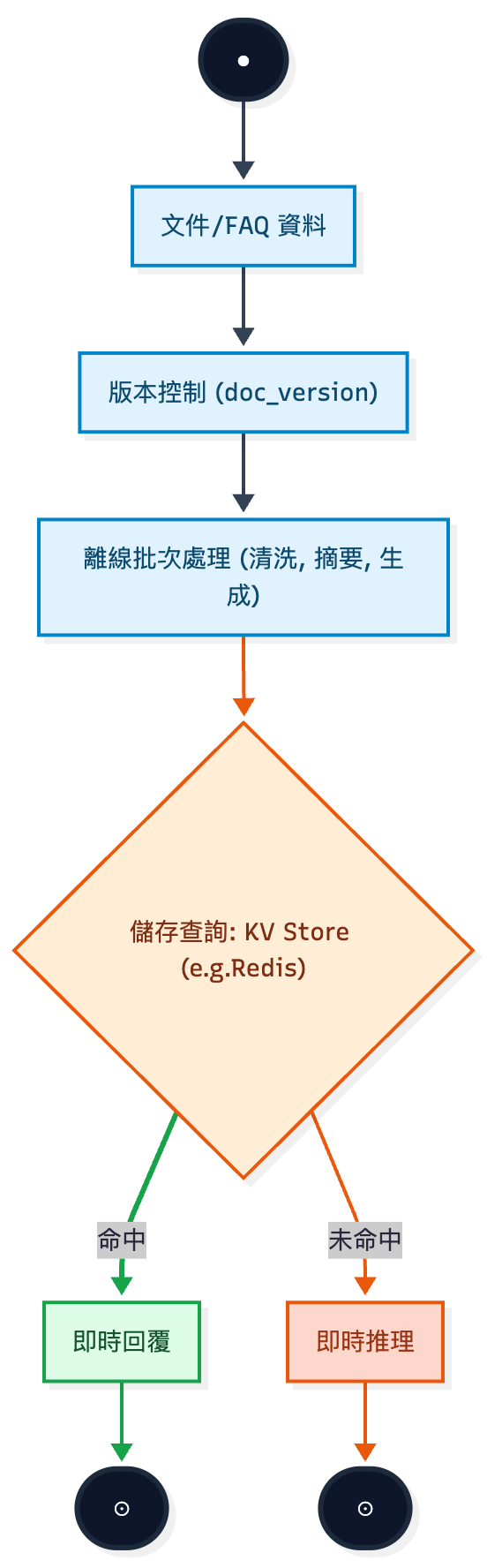
離線生成流程決策圖
💡 建議:實務上搭配 版本號 (doc_version),當文件或 FAQ 更新時才重算,避免不必要的重複生成。
[註1] A Practical Guide to Reducing Latency and Costs in Agentic AI Applications
光靠最佳化還不夠,還需要事前設定邊界,避免因錯誤或濫用導致成本暴衝。預算護欄的目的就是在「錢被花掉之前」就阻止異常情境發生。
💡 預算護欄和 SRE 的「熔斷機制(Circuit breaker)」很像:與其事後救火,不如事前把耗費控制在安全範圍。
表格中的金額僅為範例,請讀者自行參考實際情形訂立標準。
| 類別 | 指標 | 範例目標值與說明 |
|---|---|---|
| Token | 平均 prompt_tokens |
< 800;避免一次塞太多段落,先經過 RAG 重排只留最相關 2–3 段 |
| Token | 平均 completion_tokens |
< 300;透過結構化輸出(JSON/表格)和停止詞控制,避免冗長回答 |
| Token | context_length_distribution |
p90 < 1,200;長尾請求過長時,建議改用摘要或分段處理 |
| 快取 | result_cache_hit_rate |
FAQ 場景 > 60%;相同問題不該每次都重跑 LLM |
| 快取 | embedding_cache_hit_rate |
> 90%;同一份文件只應嵌入一次,避免重算浪費 |
| 架構 | escalation_rate |
10–30%;過高表示小模型不合適,過低可能浪費在大模型上 |
| 架構 | retry_rate |
< 3%;避免反覆重試造成延遲與成本暴增 |
| 架構 | latency_p95 |
< 2–3 秒;超過代表 pipeline 太複雜或模型選擇不當 |
| 成本 | cost_per_request |
每次 < NT$0.2;追蹤週/月趨勢,確保成本逐步下降 |
| 成本 | cost_per_user / per_team |
每人/月 < NT$100(示例);搭配配額與預算告警 |
| 品質 | hallucination_rate |
< 5%;超過需調整檢索/Prompt 或加上驗證機制 |
| 品質 | user_feedback_score |
≥ 4/5;確保省錢同時維持使用者體驗 |
[註1] LLM Cost Tracking Solution: Observability, Governance & Optimization
[註2] How Unbounded Consumption Attacks on LLMs Cost Companies Millions
在 Day 21 - 快取實戰 中,我們用表格呈現了快取機制的成本改善:
| 情境 | 月請求數 | 基準成本 | 快取後成本 | 節省比例 |
|---|---|---|---|---|
| FAQ(命中 60%) | 100,000 | $250 | $100 | 60% |
| 一般 QA(命中 30%) | 100,000 | $250 | $175 | 30% |
| QA + Token Cache | 100,000 | $250 | $150 | 40% |
完整計算過程請參考 Day21 - LLM 應用快取實戰:成本改善 × 加速回應
Day 21 專注在「快取效果」,這裡補充「一次查詢的成本組成」。
假設:
典型企業知識庫問答(1,000 次/日):
| 成本項目 | 費用 | 佔比 | 改善方向 |
|---|---|---|---|
| LLM 推理 | NT$0.78 | 81% | 精煉 Prompt、模型分級、快取 |
| Reranker | NT$0.13 | 13% | 降低候選段落數 |
| 向量檢索 | NT$0.03 | 3% | 改善基礎設施 |
| 基礎設施 | NT$0.02 | 2% | - |
| 總計 | NT$0.96/次 | 100% | - |
每月成本基準:1,000 × 30 × NT$0.96 = NT$28,800
計價單位為美金(USD)
結合多個策略後的成本模擬:
| 改善組合 | 改善效果(概念) | 新的每月成本 | 節省比例 | 追蹤指標 |
|---|---|---|---|---|
| 基準(無改善) | – | NT$28,800 | – | cost_per_request = NT$0.96 |
| + Prompt 精煉 | LLM Token ↓25% | NT$22,950 | 20.3% | avg_prompt_tokens ↓ 25% |
| + Cache(60%) | 命中成本 ≈ NT$0.06 | NT$10,260 | 64.4% | result_cache_hit_rate = 60% |
| + Hybrid 路由 | 70% 走小模型 | NT$7,803 | 72.9% | escalation_rate = 30% |
| + 離線生成(75%) | 命中成本 ≈ NT$0.03 | NT$4,877 | 83.1% | offline_hit_rate = 75% |
| + 預算護欄 | 重試抑制 −10% | NT$4,389 | 84.8% | retry_rate < 3% |
- 以上為同一情境的「逐步疊加」效果;基準假設 1,000 次/日 × 30 天、
cost_per_request = NT$0.96。- 結算數字為「可審核的估算模型」,用於示範套用本文節省成本路徑的量級效果;可依照實際價表替換單價與命中率,實際結果請依自己環境為準。
成本試算後,我們就要來看如何 實際落地。這邊提供一個參考藍圖,實際時程請依團隊資源與現有基礎調整:
| 階段 | 核心任務 | 平均耗時 | 快速改善耗時 |
|---|---|---|---|
| Phase 1 | 建立基線與觀測 | 1-2 週 | 3-5 天(若已有觀測系統) |
| Phase 2 | Prompt 精煉 | 3-5 天 | 1-2 天(若已知瓶頸) |
| Phase 3 | Cache 機制 | 5-7 天 | 2-3 天 |
| Phase 4 | Hybrid 路由 | 1-2 週 | 3-5 天(若已有分類器) |
| Phase 5 | 離線生成 | 1 週 | 2-3 天(FAQ 量少時) |
| Phase 6 | 預算護欄 | 3-5 天 | 1-2 天(若只做基礎限流) |
| Phase 7 | 回顧改善成果 | 2-3 天 | 1 天(產出結論簡報即可) |
理想情境(4-6 週):基礎架構與功能已建置完成、新功能與改善可平行開發
現實情境(10-12 週): 從零開始、單人或三人內小團隊
最快路徑(2 週見效 - 依照專案的規模) :文章前面提到的 MVP 三步驟(Cache → Prompt → Routing)先做
💡 若團隊人力有限,可將 Phase 1+2 合併同步進行(2-3 週完成)

目標:確立現況,建立可量測的指標系統
關鍵任務:部署觀測工具、記錄基準指標、建立儀表板
驗收標準:能即時查看 cost_per_request、avg_tokens、p95_latency、query_count
系列文參考:
目標:減少 20-30% Token 成本
關鍵任務:分析 Prompt 結構、刪除冗詞、調整 RAG top-k、結構化輸出
驗收標準:avg_prompt_tokens ↓ ≥ 20%,品質不降
系列文參考:
目標:FAQ 場景命中率達 60%+
關鍵任務:部署 Redis、實作 Result/Embedding Cache、設定 TTL
驗收標準:result_cache_hit_rate ≥ 60%,延遲 < 200ms(命中時)
系列文參考:
目標:50-70% 查詢走小模型
關鍵任務:建立分類器、定義路由規則、實作升級機制
驗收標準:escalation_rate 10-30%,小模型準確率 ≥ 90%
系列文參考:
目標:Top 50-100 FAQ 預先生成
關鍵任務:分析熱門查詢、批次生成答案、建立版本管理
驗收標準:offline_hit_rate ≥ 75%,熱門問題延遲 < 50ms
系列文參考:
目標:避免成本暴衝
關鍵任務:設定請求/用戶/團隊層級配額、建立警報與熔斷
驗收標準:異常流量被攔截,成本控制在預算內
系列文參考:
目標:驗收整體成效,規劃下階段
關鍵任務:產出前後對比報告、檢視指標達成率、調整策略
驗收標準:確認成本降幅 ≥ 70%,品質維持 ≥ 4.0/5,完成書面報告
在 LLMOps 觀念系列的最後一天,我們理解到了:
cost_per_request、cache_hit_rate、escalation_rate)持續迭代,才能把降本內化成日常工程實踐。👉 明天(Day 27)我們將進入 RAG FAQ Chatbot 實戰案例 I:功能開發與驗收,把快取、觀測、RAG、路由、安全與降本全部串起來,驗證完整上線藍圖。


 iThome鐵人賽
iThome鐵人賽