Reccurent Neural Network 簡稱 RNN.跟之前提到的 CNN (找出特徵),Autoencoder (降維 重建) 不同.它關注的是 時間序列 有關的問題,舉個例子,一篇文章中的文字會是跟前後文有前因後果的,而如果想要製作一個文章產生器,就會需要用到 RNN.
那 RNN 是如何解決這個問題呢?.觀察下面這個 RNN 基本的結構圖.其中 Xt 以及 Ht 分別是 t 時刻的輸入以及輸出,可以看到 Ht 會跟 Ht-1 以及 Xt 有關,可以簡單地把它想像成多一個輸入的神經網路.

那如果我們依照時間序列展開 RNN 就會變成以下的樣子:

每一個時間點的輸出,除了跟當前的輸入有關,也會跟前一刻,前前一刻...等時間點的輸出有關係.如此就相當於把各個時間序列點的輸出連結了起來.
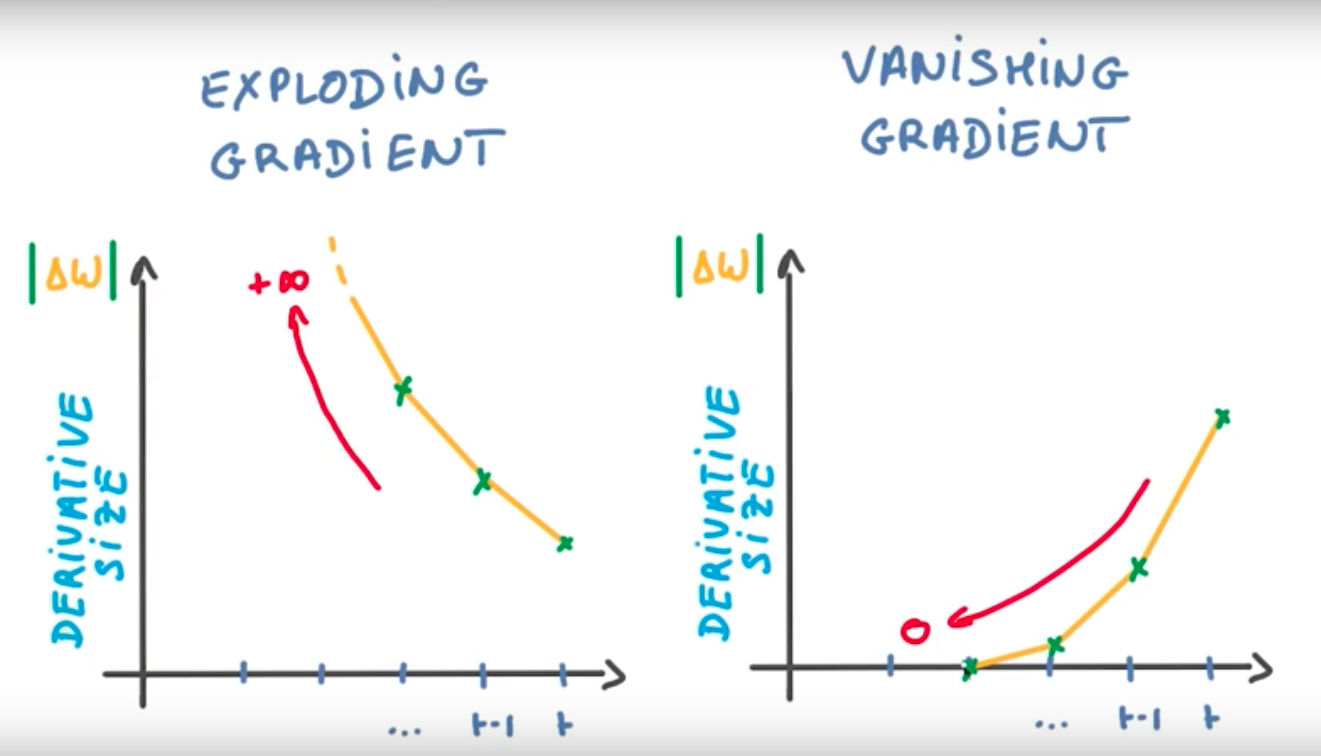
理論上來說這是一個很完美結構,可以處理許多跟時間序列有關的問題,但是實際上會遇到許多的問題,什麼問題呢?想像一下在訓練模型的時候會利用 Backpropagation 來更新權重,而 RNN 的輸出會跟前一刻有關,所以也會傳遞到前一刻的模型更新權重,依此類推.當這些更新同時發生的時候就可能會產生兩個結果,一個是梯度爆炸 (Gradient Exploding)另一個是梯度消失 (Gradient Vanishing).
梯度爆炸,也就是說隨著序列增加,後續權重的更新大到無法處理的地步,如下圖.而解決這個問題的方式比較簡單的方法就硬性規定一個更新上限,更新值大於上限就用上限值取代.
梯度消失,也就是說隨著序列增加,後續權重的更新小到趨近於 0.使得 RNN 只記得最近發生的事情,而沒有辦法記起時間較久前的結果.而解決這個問題的方式就是 LSTMs,在不可思議的 RNN這篇文章中,提到了許多 RNN 非常有效的使用場景,就是因為使用了 LSTMs.
使用 LSTM 的方法非常簡單就是把 RNN cell 替換成 LSTM cell,關於 LSTM 的內容這裡不會細講,可以看這一篇非常棒的文章,目前請先想像成它可以有效的解決梯度消失的問題.
圖片來自 Udacity course
接下來我們會用 Tensorflow 中的 RNN 來處理 MNIST 手寫數字辨識的問題.但是一個圖片要怎麼跟時間序列扯上關係呢?簡單的想法就是我們把 MNIST 中 28 x 28 維的資料,想像成 28 個時間點,而每一時間點就給 RNN 28 維的向量.換句話說就是讓 RNN **'一列一列地看'**手寫數字,當看完整個圖片的以後,把他的輸出 H28 先丟給一個全連結層之後再丟給分類器來決定說這個看到的數字屬於哪一類.
設定相關的參數,其中要讓 RNN 看 MNIST 圖片的話就是,一次給它看一列 (n_input = 28維),由上看到下看 28 個輸入 (n_steps = 28 steps).
n_input = 28 # MNIST data input (image shape: 28*28)
n_steps = 28 # steps
n_hidden = 128 # number of neurons in fully connected layer
n_classes = 10 # (0-9 digits)
x = tf.placeholder("float", [None, n_steps, n_input])
y = tf.placeholder("float", [None, n_classes])
weights = {
"w_fc" : weight_variable([n_hidden, n_classes], "w_fc")
}
biases = {
"b_fc" : bias_variable([n_classes], "b_fc")
}
因應 tensorflow 中 RNN 輸入的要求,現在要來變化輸入向量的形式
n_step, None, n_input
x_transpose = tf.transpose(x, [1, 0, 2])
print("x_transpose shape: %s" % x_transpose.get_shape())
x_transpose shape: (28, ?, 28)
n_step * None, n_input
x_reshape = tf.reshape(x_transpose, [-1, n_input])
print("x_reshape shape: %s" % x_reshape.get_shape())
x_reshape shape: (?, 28)
x_split = tf.split(0, n_steps, x_reshape)
print("type of x_split: %s" % type(x_split))
print("length of x_split: %d" % len(x_split))
print("shape of x_split[0]: %s" % x_split[0].get_shape())
type of x_split: <type 'list'>
length of x_split: 28
shape of x_split[0]: (?, 28)
接下來就是要建立模型,這裡直接使用 RNN cell,其中 n_hidden 是輸出的維度為 128.
觀察它輸出的 h 是一個長度 28 的 list,第 i 個元素代表著第 i 個 step 的輸出,每個元素會有 None x n_hidden
basic_rnn_cell = rnn_cell.BasicRNNCell(n_hidden)
h, states = rnn.rnn(basic_rnn_cell, x_split, dtype=tf.float32)
print("type of outputs: %s" % type(h))
print("length of outputs: %d" % len(h))
print("shape of h[0]: %s" % h[0].get_shape())
print("type of states: %s" % type(states))
type of outputs: <type 'list'>
length of outputs: 28
shape of h[0]: (?, 128)
type of states: <class 'tensorflow.python.framework.ops.Tensor'>
接一個 128 -> 10 的全連結層
h_fc = tf.matmul(h[-1], weights['w_fc']) + biases['b_fc']
y_ = h_fc
用 softmax 作分類
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(h_fc, y))
optimizer = tf.train.AdamOptimizer(0.01).minimize(cost)
correct_prediction = tf.equal(tf.argmax(y_, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
batch_size = 100
init_op = tf.global_variables_initializer()
sess = tf.InteractiveSession()
sess.run(init_op)
variables_names =[v.name for v in tf.trainable_variables()]
for step in range(5000):
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = np.reshape(batch_x, (batch_size, n_steps, n_input))
cost_train, accuracy_train, states_train, rnn_out = sess.run([cost, accuracy, states, h[-1]], feed_dict = {x: batch_x, y: batch_y})
values = sess.run(variables_names)
rnn_out_mean = np.mean(rnn_out)
for k,v in zip(variables_names, values):
if k == 'RNN/BasicRNNCell/Linear/Matrix:0':
w_rnn_mean = np.mean(v)
if step < 1500:
if step % 100 == 0:
print("step %d, loss %.5f, accuracy %.3f, mean of rnn weight %.5f, mean of rnn out %.5f" % (step, cost_train, accuracy_train, w_rnn_mean, rnn_out_mean))
else:
if step%1000 == 0:
print("step %d, loss %.5f, accuracy %.3f, mean of rnn weight %.5f, mean of rnn out %.5f" % (step, cost_train, accuracy_train, w_rnn_mean, rnn_out_mean))
optimizer.run(feed_dict={x: batch_x, y: batch_y})
step 0, loss 2.32416, accuracy 0.090, mean of rnn weight -0.00024, mean of rnn out -0.00735
step 100, loss 1.64264, accuracy 0.380, mean of rnn weight -0.00052, mean of rnn out -0.09297
step 200, loss 1.13360, accuracy 0.600, mean of rnn weight 0.00075, mean of rnn out 0.00324
step 300, loss 1.03078, accuracy 0.670, mean of rnn weight 0.00082, mean of rnn out -0.00883
step 400, loss 1.29169, accuracy 0.510, mean of rnn weight 0.00108, mean of rnn out 0.00112
step 500, loss 1.48408, accuracy 0.420, mean of rnn weight 0.00160, mean of rnn out -0.01736
step 600, loss 1.43396, accuracy 0.570, mean of rnn weight 0.00256, mean of rnn out -0.05415
step 700, loss 2.06715, accuracy 0.350, mean of rnn weight 0.00297, mean of rnn out -0.04546
step 800, loss 1.53593, accuracy 0.390, mean of rnn weight 0.00282, mean of rnn out 0.00934
step 900, loss 1.58583, accuracy 0.370, mean of rnn weight 0.00266, mean of rnn out 0.01959
step 1000, loss 1.36978, accuracy 0.470, mean of rnn weight 0.00299, mean of rnn out 0.04775
step 1100, loss 2.12206, accuracy 0.360, mean of rnn weight 0.00161, mean of rnn out -0.00393
step 1200, loss 1.50930, accuracy 0.470, mean of rnn weight 0.00138, mean of rnn out -0.01369
step 1300, loss 1.39899, accuracy 0.520, mean of rnn weight 0.00152, mean of rnn out 0.00569
step 1400, loss 1.44504, accuracy 0.430, mean of rnn weight 0.00158, mean of rnn out -0.00496
step 2000, loss 2.32795, accuracy 0.170, mean of rnn weight 0.00122, mean of rnn out 0.09313
step 3000, loss 2.43317, accuracy 0.100, mean of rnn weight 0.00119, mean of rnn out 0.07819
step 4000, loss 2.42197, accuracy 0.110, mean of rnn weight 0.00111, mean of rnn out 0.07806
cost_test, accuracy_test = sess.run([cost, accuracy], feed_dict={x: np.reshape(mnist.test.images, [-1, 28, 28]), y: mnist.test.labels})
print("final loss %.5f, accuracy %.5f" % (cost_test, accuracy_test) )
final loss 2.41618, accuracy 0.10320
可以看到預測結果非常不好,測試的準確率只有 10%,rnn 的權重平均值滿低的.下面印出最後輸出 128 維的矩陣,可以看到每個值都接近 1 或是 -1,然後搜尋一下以後知道 RNN 裡面輸出之前會經過一個 tanh,而當 tanh 在 1 或 -1 的時候做微分是 0.我想這樣的情形就是Gradient Vanishing了.
print h[-1].eval(feed_dict={x: np.reshape(mnist.test.images, [-1, 28, 28]), y: mnist.test.labels})[0,:]
[ 0.99999559 1. 1. -1. -0.99998862 1. 1.
-1. 1. 1. -0.99999774 1. -0.99999982
1. 1. 1. 1. 0.9999997 0.99999994
0.9999994 -0.99999225 -1. -1. 1. -1. 1.
-0.99999952 1. 0.99999928 -1. 0.99674076 1. -1.
-0.99999458 -0.99956894 1. 0.99983639 0.99999982 0.99956954
-0.99999893 1. -0.99999994 1. -0.99997771 1. 1.
1. -1.00000012 -1. 1. -0.99970055 0.99998623
-0.99999619 -1. -0.99960238 0.99785262 -1. 0.99962986
-1. 1. -1. -1. 1. -1. 1.
0.99979544 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 0.99939382 -1. -1.
-0.99976331 -0.99999881 -1. -0.99999976 -1. -0.99999964
1. -1. -0.99999934 0.99999392 0.99910891 -0.99995011
-1. -1. -1. -0.99998069 0.99999958 -0.99999964
1. -1. 0.99999958 1. -1. 1.
-0.99998337 0.99999732 1. 1. 1. -0.99997371
-1. -0.999376 0.99992633 0.9999997 1. -1.
0.99999499 1. -1. -1. 1. -1.
-0.99995339 0.99957949 -1. -0.999933 -0.99999905 -0.99999183
1. ]
因為上面 RNN 的表現非常不好,讓我們來用一下 tensorflow 中的 LSTMs cell 看看成果如何.而更改 cell 的設定非常簡單,只要把 BasicRNNCell 改成 BasicLSTMCell 就可以了.
lstm_cell = rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0)
h, states = rnn.rnn(lstm_cell, x_split, dtype=tf.float32)
step 0, loss 2.30415, accuracy 0.110, mean of lstm weight 0.00013, mean of lstm out 0.01331
step 100, loss 0.31279, accuracy 0.880, mean of lstm weight -0.00529, mean of lstm out -0.00088
step 200, loss 0.17318, accuracy 0.940, mean of lstm weight -0.00648, mean of lstm out 0.00784
step 300, loss 0.15617, accuracy 0.950, mean of lstm weight -0.00778, mean of lstm out -0.00153
step 400, loss 0.08717, accuracy 0.980, mean of lstm weight -0.00872, mean of lstm out 0.00838
step 500, loss 0.13275, accuracy 0.960, mean of lstm weight -0.00991, mean of lstm out 0.00275
step 600, loss 0.11011, accuracy 0.970, mean of lstm weight -0.01076, mean of lstm out 0.00076
step 700, loss 0.12507, accuracy 0.960, mean of lstm weight -0.01037, mean of lstm out 0.00274
step 800, loss 0.09086, accuracy 0.970, mean of lstm weight -0.01050, mean of lstm out 0.00409
step 900, loss 0.05551, accuracy 0.990, mean of lstm weight -0.01066, mean of lstm out -0.00078
step 1000, loss 0.03132, accuracy 0.990, mean of lstm weight -0.01064, mean of lstm out -0.00035
step 1100, loss 0.06873, accuracy 0.980, mean of lstm weight -0.01098, mean of lstm out -0.00248
step 1200, loss 0.08930, accuracy 0.980, mean of lstm weight -0.01073, mean of lstm out -0.00918
step 1300, loss 0.10252, accuracy 0.980, mean of lstm weight -0.01027, mean of lstm out -0.00038
step 1400, loss 0.00594, accuracy 1.000, mean of lstm weight -0.01041, mean of lstm out 0.00762
step 2000, loss 0.04595, accuracy 0.990, mean of lstm weight -0.01243, mean of lstm out 0.00263
step 3000, loss 0.12044, accuracy 0.960, mean of lstm weight -0.01405, mean of lstm out -0.00691
step 4000, loss 0.03068, accuracy 0.990, mean of lstm weight -0.01488, mean of lstm out -0.00371
final loss 0.06450, accuracy 0.98390
Bingo!可以看到準確率提升到非常高,看來 LSTMs 真的解決了 RNN 的缺點.
了解了 RNN 的架構,以及會遇到的問題 Gradient Exploding 以及 Gradient Vanishing,並且使用 MNIST 手寫數字資料集來練習 RNN.
在 MNIST 中純粹的 RNN 會遇到梯度消失問題,而改用 LSTMs 之後就成功了提高極多的準確度.


