繼續介紹資料預處理上遇到的一些問題,確保資料的正確性。我們想知道是站碼還是站名有被更動過,如果有被更動過,那是哪個站備更過動呢?
length(data1$TKT_BEG) == length(unique(data1$TKT_BEG))
結果顯示為為TRUE 由此可知,站碼沒有重複值
length(data1$STOP_NAME) == length(unique(data1$STOP_NAME))
結果顯示為為FALSE ,表示說站名有重複值,要想辦法去抓是240站當中哪個站的站碼曾經換過
table(data1$STOP_NAME)
table(data1$STOP_NAME) == 1
w = table(data1$STOP_NAME) == 1
w[w == F]
這幾行的結果如下
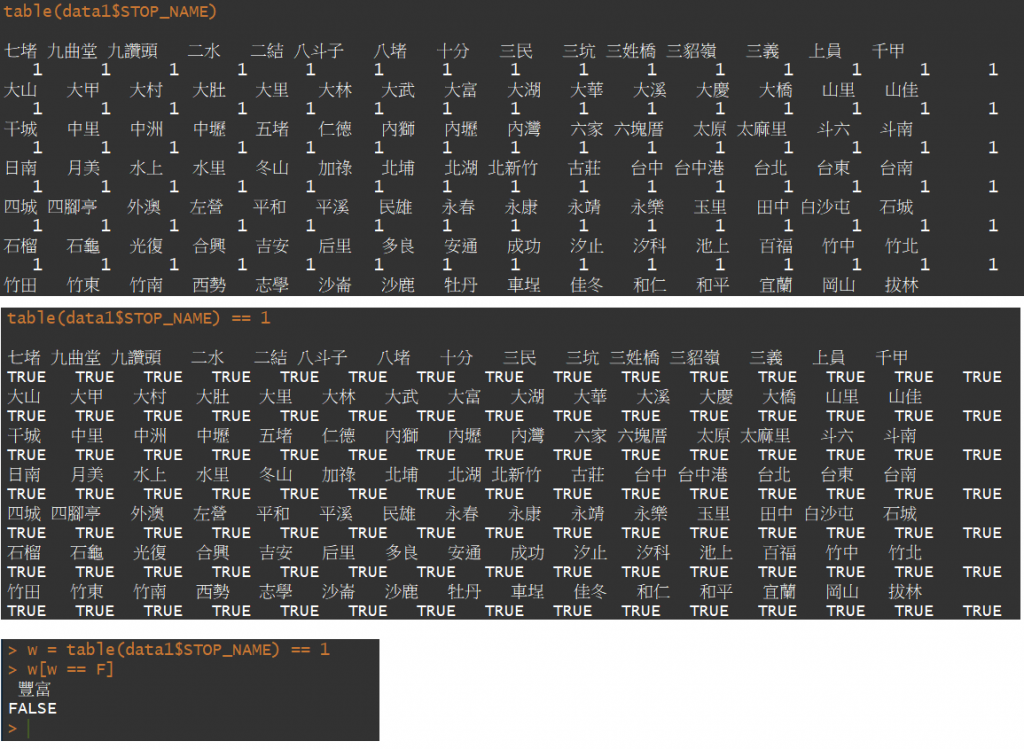
我們用table(data1$STOP_NAME)可以顯示出每一個站名出現過的次數,table(data1$STOP_NAME) == 1表示說出現次數為1的我們讓他顯示為TRUE,若不是1則為FLASE,將結果紀錄下來設為w,找 w 等於 FLASE 的那個選項即為我要找的目標。
抓到,更動過的站碼的是 豐富站 ,現在我們要把"豐富新舊站"合併,其實方法很簡單,既然"站名"都一樣,那我們僅用"站名"進行group_by就可以得到我想要的結果啦
data2 = data %>% group_by (STOP_NAME) %>% summarise(總進站 = sum(進站),總出站 = sum(出站))
#再檢查一次
length(data2$STOP_NAME) == length(unique(data2$STOP_NAME))
#果然是顯示TRUE啦
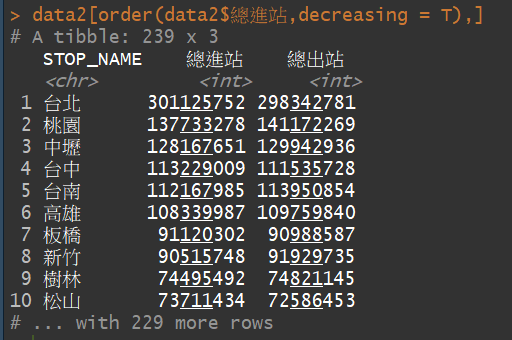
對data2進行排列
data2[order(data2$總進站,decreasing = T),]
不過其實這樣還有一個小問題總天數 x 站名 != 所有資料,意思是說,有些站並不是每一天都有資料(也許有些遺失的部分,因此要進行比較的話必須再除上一個基數便是出現次數了,讓資料變成平均一天的進、出站人數)
nrow(data)
[1] 1061714
day * length(data2$STOP_NAME)
[1] 1178031
因此要計算每日的平均進出人口
data2 = data %>% group_by (STOP_NAME) %>% summarise(每日進站 = sum(進站)/length(進站),每日出站 = sum(出站)/length(出站))
data2[order(data2$每日進站,decreasing = T),]
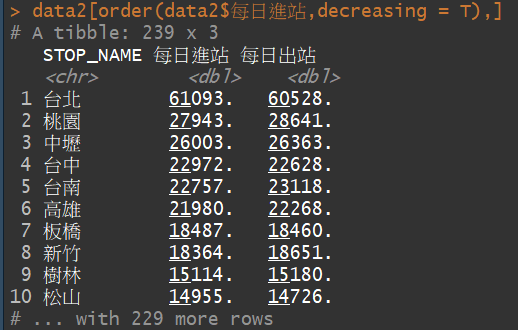
用order進行排序, 資料[order(資料排序依據),] ,這是order的用法,不過這樣會是由小排到大,加上decreasing = T就是由大排到小了。
其實我前面就很隨意地使用了R的vlookup了,這邊重點多解釋下那時候使用的原理是什麼。
我們先把台北車站一天的資料拉出來看,
Taipei = data[which(data$STOP_NAME == "台北"),]
Taipei_in = Taipei$進站
plot(Taipei_in)
plot.ts(Taipei_in)
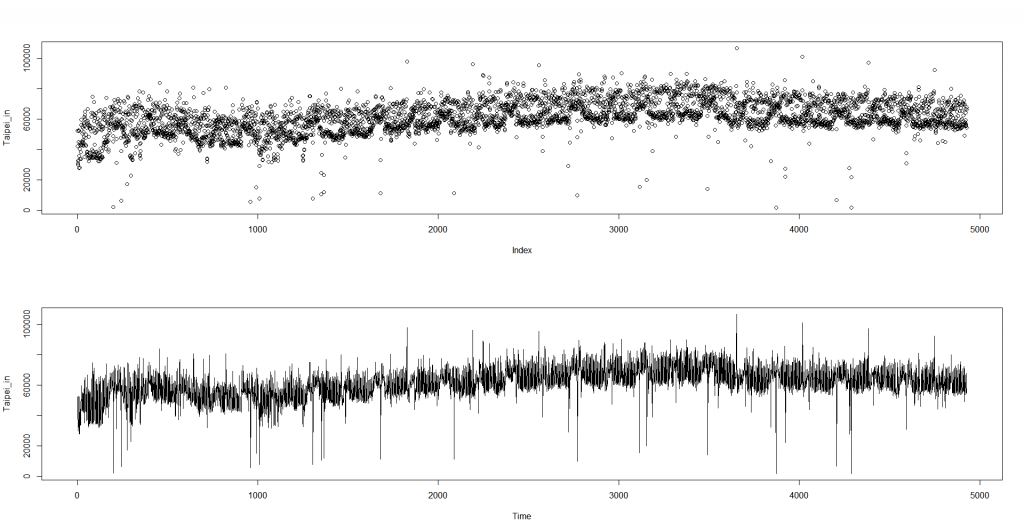
看起來還是挺平均的。

