
編寫程式碼時,載入已經存在的套件能幫我們節省下許多時間,又載入套件時,常有許多約定成俗的縮寫方式,需要稍微注意一下。不僅是為了簡短程式碼,也為了日後能順利閱讀討論串鋪墊。舉例來說,今天介紹的Pandas套件(取名自套件主要提供的三種資料結構:Panel、DataFrame 與 Series),通常會載入後縮寫成pd方便使用。(初次使用記得先到命令提示字元輸入pip install pandas進行安裝。)接著使用套件中DataFrame()功能將字典的資料結構轉換為資料框架(對於Dictionary的資料結構補充傳送門。)
When coding, we import packages to save our time. At the same time we import them, we normally abbreviate the name so we can use it easier. For example, the package we are going to import is Pandas, and is often abbreviated as pd.(Make sure you type 'pip install pandas’ in cmd to install the package on the first time.)Then, we use the function DataFrame() to construct a dictionary into DataFrame. Check out this link to learn what dictionaries are.
import pandas as pd # 載入套件並縮寫 import package and abbreviate the name
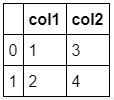
d = {'col1': [1, 2], 'col2': [3, 4]} # 先建立一個字典 create a dictionary
df = pd.DataFrame(data=d) # 運用函數將字典轉換為資料框架 constructing a dictionary into data frame
df # 呼叫轉換完成的資料框架 call the transformed dataframe
在Pandas DataFrame中,常見的欄位變數資料類型有三種:
There are three main data types of data:
Different types of Variables:
資料是字串或類別型要做進一步的分析時(如訓練模型),一般需要先轉換為數值資料類型,較常見的轉換方式有兩種:
If the original data contains string or object, we will need to convert them into numerical data type. There are two main way to achieve it:
Numpy contains many mathematical functions for matrix operations.
# 載入套件 import packages
import numpy as np
import pandas as pd
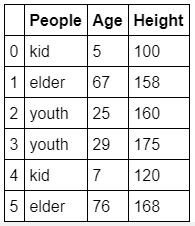
ppl = ['kid', 'elder', 'youth', 'youth', 'kid', 'elder']
age = [5, 67, 25, 29, 7, 76]
height = [100, 158, 160, 175, 120, 168]
dic = {'People':ppl, 'Age':age, 'Height':height}
# 建立一個字典把剛剛的資料存進去 save the data into a dictionary
data = pd.DataFrame(dic) # 把剛剛建立的字典轉換為資料框架 change the dictionary into DataFrame
data
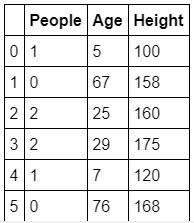
from sklearn.preprocessing import LabelEncoder # 載入標籤編碼功能 import labelencoder
labelencoder = LabelEncoder()
data_le = pd.DataFrame(dic)
#不要弄亂剛剛的DataFrame,建一個新的來編碼 create a new dataframe for labelencoding
data_le['People'] = labelencoder.fit_transform(data_le['People']) # 以標籤編碼完的資料取代原欄位 replace the column with encoded data
data_le
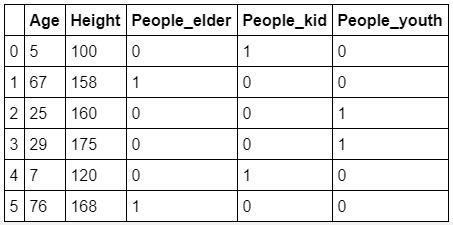
使用Pandas中get_dummies()函數可以輕易將DataFrame進行獨熱編碼。
Using the get_dummies() function in Pandas to easily One-Hot encode DataFrame.
data_dum = pd.get_dummies(data)
pd.DataFrame(data_dum)
本篇程式碼請參考Github。The code is available on Github.
文中若有錯誤還望不吝指正,感激不盡。
Please let me know if there’s any mistake in this article. Thanks for reading.
Reference 參考資料:
[1] 第二屆機器學習百日馬拉松內容
[2] Engeneering Statistic Handbook
[3] 機器學習中的Label Encoder和One Hot Encoder
[4] 選擇正確的編碼方法—Label vs OneHot Encoder
[6] Discrete and Continuous Random Variables
