
今天來完成 How Google does Machine Learning 第三章節的最後部分~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第三章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
ML and Business Processes
The Path to ML
End of phases deep dive
課程地圖
(from "No ML" to "ML")在目前的組織中加入ML的方式,我們可以先原先的業務流程來看,
我們先觀察客戶與公司之間的活動,這裡以call center作為例子:
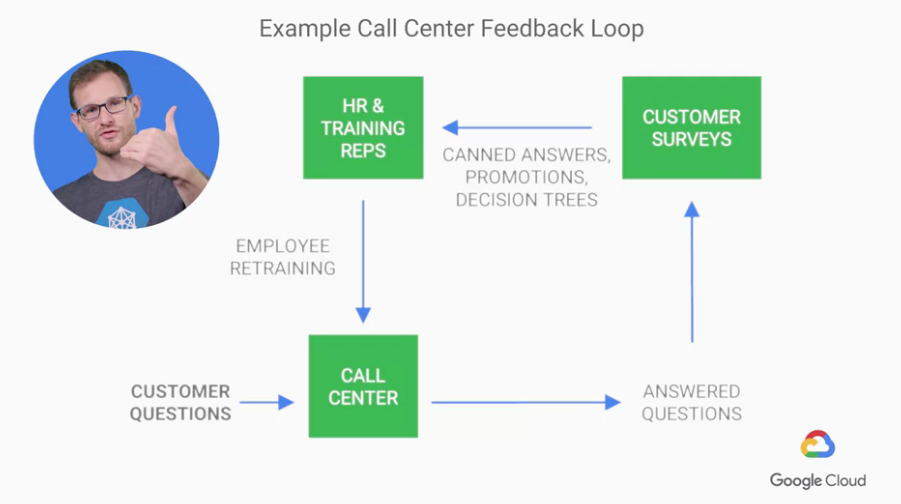
現在有個call center
而這樣的例子我們用一個較一般化的表示方法如下圖:
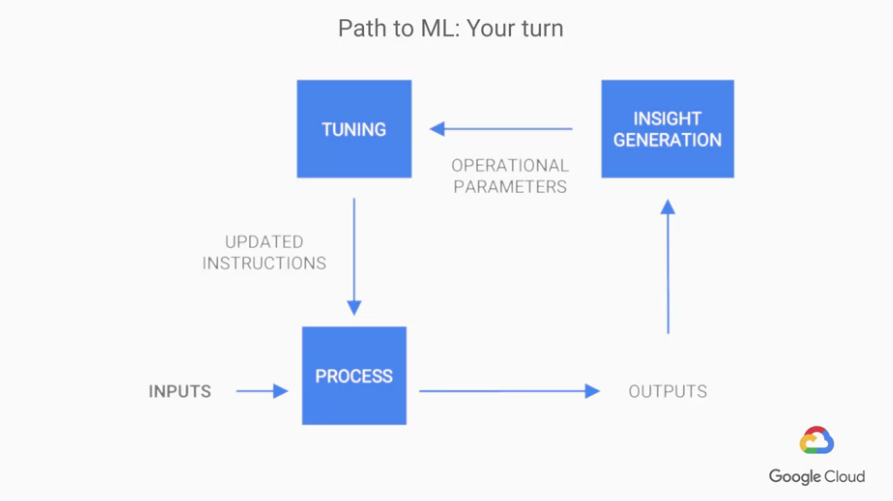
這樣就是一般的 General Feedback Loop,我們試著在其中加入ML,
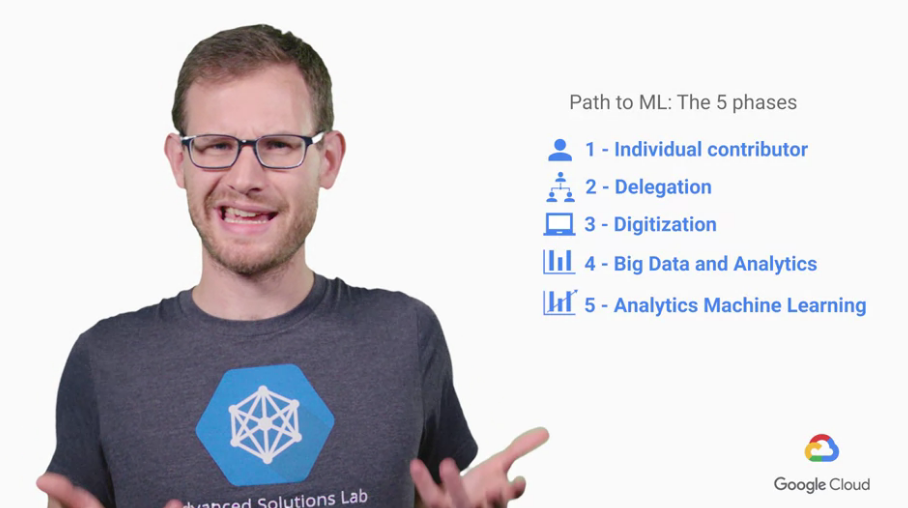
這裡我們必須先提到有五點 Path to ML 的方法
一個人負責這件事情
開始多人負責這件事情,有組織化,或有組織平行的在運作相同任務
(通常到這階段會開始制定一些rules)
開始將一些"重複性高"的動作(rules),透過電腦來自動化幫人處理
一個容易理解的例子:ATM
使用大量的data去更符合使用者的需求(insights)
再將前面的所有資料,去進化我們的電腦處理流程(使完全自動化處理)
(自己的註:這邊的自動化,指的是連"符合使用者的需求"這件事也自動化了)
例子:youtube推薦,要先讓使用者有回饋給youtube喜好,youtube才能主動推薦影片
而回到我們該如何加入進去我們的 General Feedback Loop,
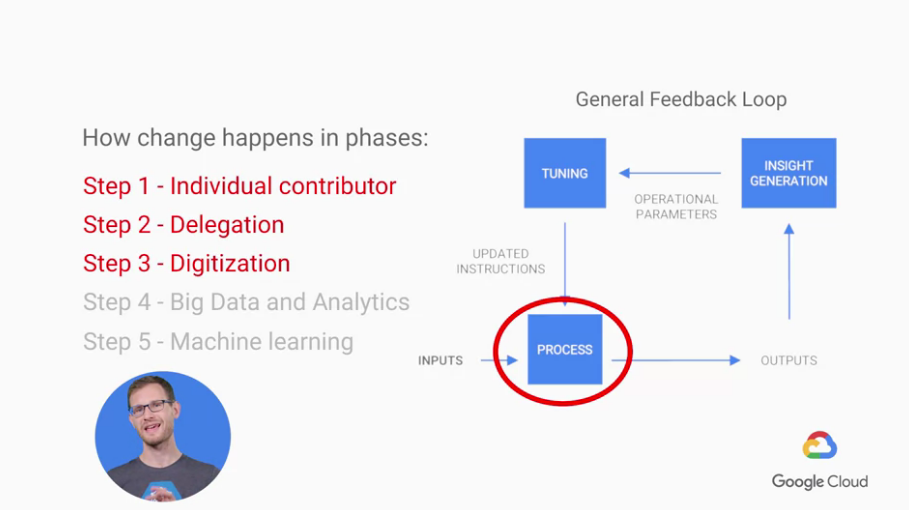
前三個步驟裡面可以影響到process本身,
這三個步驟主要是再處理使用者面臨到我們產品的階段。
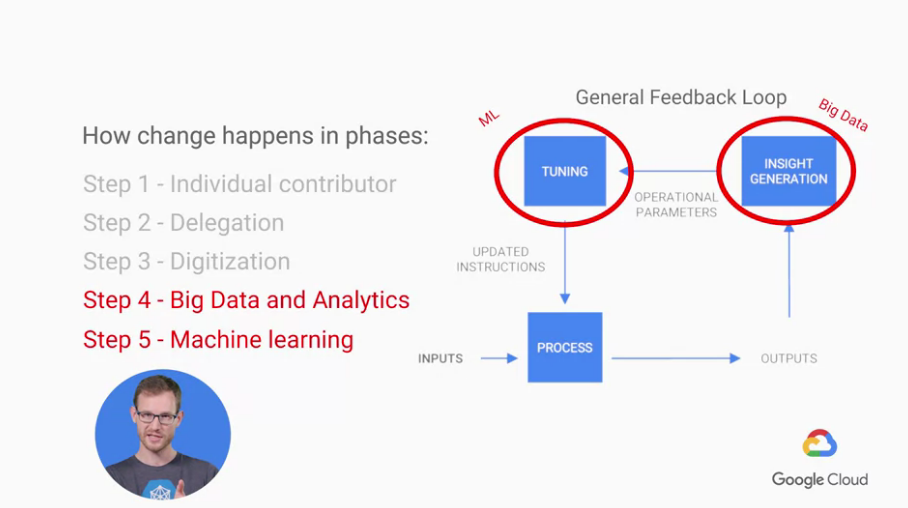
Big Data and Analytics主要影響到的是我們如何找尋使用者的insights,
簡單換句話說就是知道(或更加清楚)使用者想到的是什麼,
Machine Learning,我們原本藉由調查來知道使用者需求(上一個階段),
並依這件事情訓練員工,使顧客能享受到更好的服務,
但現在我們可以用ML處理掉這階段,使得訓練員工(員工現在已經是我們的電腦),
自動化的讓顧客能享受到更好的服務。
課程地圖
這個章節我們要接續講上章的Path to ML,
但我們要來更詳細分析這幾個階段,
如果需要定義的話可以往上一章節看。
而在這個章節中,我們也可以拿這五個步驟來檢視一間企業目前可能碰到的問題。
Path to ML的五大步驟如下圖:

Step1. Individual contributor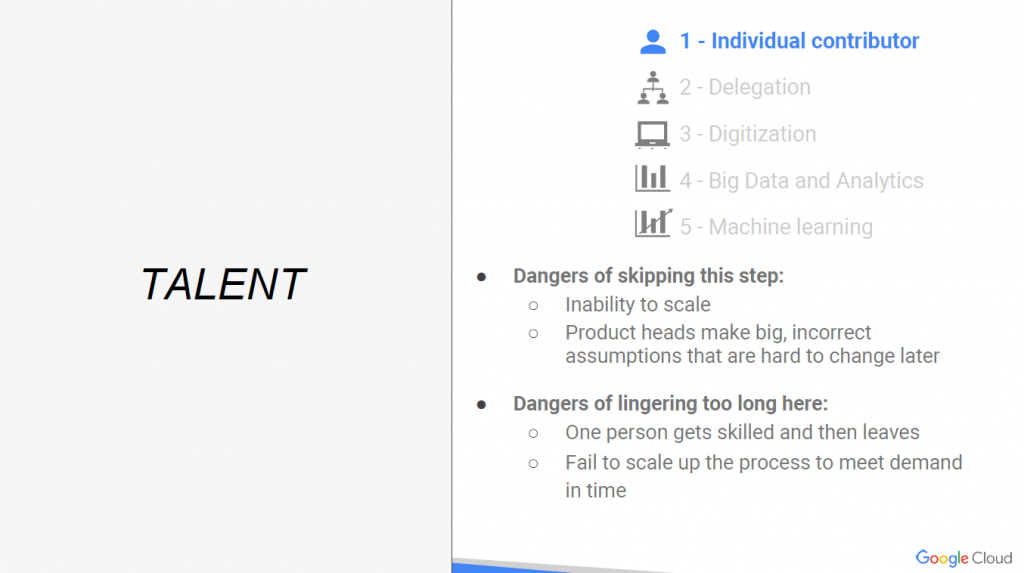
由個別的人去應對一件需求。
如果skip這步驟會怎麼樣?
- 可能很難擴展規模。
- 沒有一個人先嘗試過,或先提早失敗過,直接建立一個很大的團體,
如果問題發現後,很難能夠整個組織大幅度的調整。
如果這步驟太久會怎麼樣?
- 一個人掌握了所有的技術,當他離開時也將所有技術帶走,
公司直接沒有了這樣的技術,嚴重可能公司因為沒有會此技術的人而停止運作。- 很難去擴大規模去應對使用者的需求。
Step2. Delegation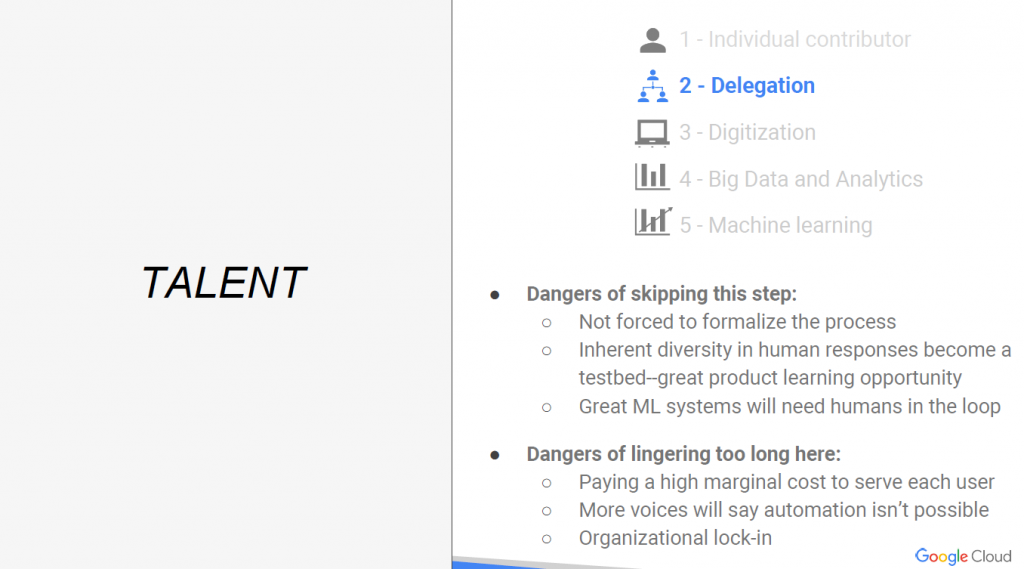
開始由個別的人擴展變多人去應對一件需求,能同時處理需求的量也提升。
如果skip這步驟會怎麼樣?
- 不知道怎麼建立process,很多rules都是再規模化的這階段被建立起來的。
如果沒有rules,也很難在下一個步驟交由電腦自動完成。- 可以再這階段累積大量不同的使用者需求,藉由不同人不同個性能得到不同的回饋經驗,
例子:call center,每個人回覆的個性不同,也能幫助我們收集需求考慮得更全面。
(反過來說skip就沒有)- 也是藉由大量客戶的反應回饋,造成human in the loop的良性循環。
(使客戶能反覆地提供我們改進的地方。)
如果這步驟太久會怎麼樣?
- 付出很高的成本在服務每一個客戶
(試想一個人一直待在銀行,只為了等待客戶來處理事情的成本,與ATM比較)- 有太多的人,就會有太多種聲音,可能導致服務標準不一致。
- 甚至最後可能會讓組織發展停留在這階段。
Step3. Digitalization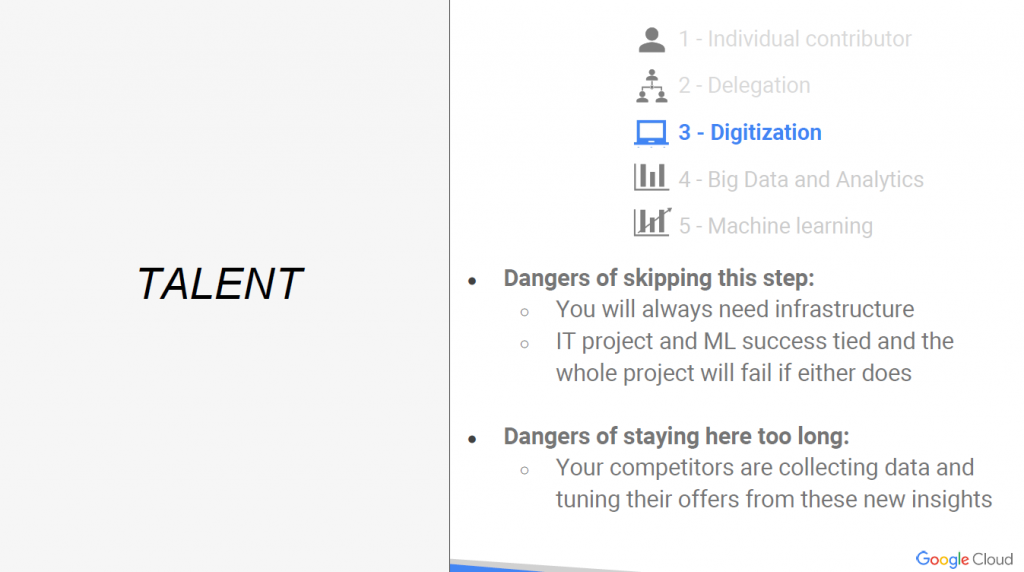
開始讓電腦來代替人力去自動化處理一些反覆的事情。
如果skip這步驟會怎麼樣?
- 就算是ML,也需要一些基礎的設備
- 沒有先做一些基本的IT project(software),
沒辦法提早在這階段先測試一些簡單的case能否成功,
直接跳到ML階段,導致ML失敗,整個project也失敗了。
如果這步驟太久會怎麼樣?
- 你的競爭者更快速的收集資料,並搶先找到新的insights,
別人的General Feedback Loop先被良好的建立後,你可能就會被打敗。
Step4. Big Data and Analytics
藉由自動化的服務,收集大量使用者的數據,並找到新的使用者需求(痛點)。
如果skip這步驟會怎麼樣?
- 不夠乾淨與組織化的資料,你也不知道做ML訓練的最終目的是為了什麼。
- 沒有大量數據的證明,很難預估自己會成功。
ML是拿來improving成功的,也就是要先有一定的基礎才能透過ML強化,
我們先自己反覆的做這樣的分析,再交由ML替我們分析,這樣ML訓練能順水推舟。
如果這步驟太久會怎麼樣?
- 基本上,在這裡待很久並不會產生太大的問題,
google也很常在這個階段停留非常久、甚至數年。- 但是透過ML能分析得更快,甚至讓結果更好,
停留在此有可能會限制能解決問題的複雜性。
Step5. Machine Learning
這個步驟就是將前面的步驟(Step4. Big Data and Analytics)自動化,
透過ML能處理的訊息量遠遠超過一個人能應付的極限,
而且我們能用更快的速度處理前面所有的需求,
甚至是更細緻的細節處理,帶來整體更好的效率與體驗。
課程地圖
這章節是Path to ML的總結論,另外我們也會在此試著用另外的角度來看這五個流程。
我們一樣先回到五個步驟,我們換個圖來表示:
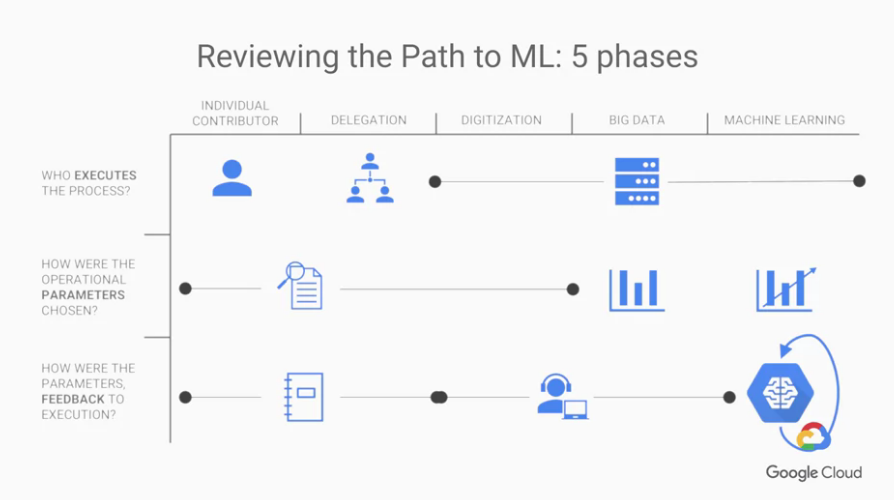
觀點1:誰是執行者?
從第一列我們可以看出,> 階段從
一個人(階段1.)->
很多人(階段2.)->
電腦處理(階段3.4.5.)」
觀點2:我們怎麼選擇調整的參數? (我們從哪裡知道如何調整以符合使用者需求?)
從第二列我們可以看出,階段從
一個個的調查結果(階段1.2.3.)->
調查結果整體分析(階段4.)->
調查結果分析並找出公式(階段5.)
觀點3:誰來幫助我們進步? (我們自己如何調整以符合使用者需求?)
從第三列我們可以看出,階段從
員工手冊或有人帶領新員工學習新的應對方式(階段1.2.) ->
工程師找到規則,並對機器coding符合使用者需求(階段3.4.) ->
machine learning(階段5.)
最後的提醒:
- 從沒有到直接"完全的使用ML"來解決問題是很危險的(對企業來說)
依照上面所說的Path to ML做可以減少很多不確定性,是比較安全的做法- Path to ML的終極目標就是將整個General Feedback Loop的過程自動化。
- 使用GCP平台的協助,能使這段Path to ML過程更加順利。
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
