上一篇我們將購買記錄轉化為 RFM 指標,接著,就可以使用各種集群分析(Clustering)的演算法,將客戶自動分群,進而找出 VIP 客戶。
由於我們的目標只是要將現有的客戶分群,並沒有要預測新客戶,所以,不需要切割出測試資料,直接將全部資料丟進演算法作訓練。
這裡使用最簡單的 k-means 演算法,它必須先決定分幾群(即k),通常,我們會使用elbow方法,計算 k=1,2,3,4, ..,n群時的損失函數(wcss),找到CP值最高的k,程式如下:
Cust_All.drop(Cust_All.columns[0], axis=1, inplace=True)
from sklearn.cluster import KMeans
wcss = []
# 計算 k=1~10 的損失函數
for i in range(1,11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=0)
kmeans.fit(Cust_All)
# kmeans.inertia_
wcss.append(kmeans.inertia_)
損失函數(wcss)為Y軸,k為X軸,作圖如下:
%matplotlib inline
import matplotlib.pyplot as plt
plt.plot(range(1,11), wcss, marker='o')
plt.title('Elbow graph')
plt.xlabel('Cluster number')
plt.ylabel('WCSS')
plt.show()
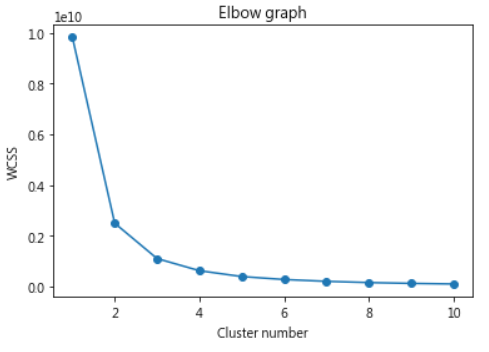
從上圖看,分成3、4、5、6群,都不錯,損失函數(wcss)都已壓低到一個程度,假設選4,我們就可以進一步計算每一群的質心:
kmeans = KMeans(n_clusters=4, init='k-means++', random_state=0)
Cust_All['clusters'] = kmeans.fit_predict(Cust_All)
print(round(pd.DataFrame(kmeans.cluster_centers_),2))
註:也可以使用 Silhouette Coefficient 來判別,避免篇幅過長,就請有興趣的讀者自行google一下。
結果如下,觀看R、F、M值,最大者就是VIP,由下表看就是第3集群(Cluster),我們就可以列出VIP名單,好好的照顧他們,猛發EDM,攻佔他們的荷包。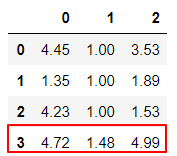
Cust_All[Cust_All.clusters== 2]
可以依據R、F、M畫個3D 散佈圖,驗證資料分群是否成功,其中質心以紅色三角形表示,確認同一群的資料是否聚集在一起,由於圖形無法在jupyter內旋轉,故另外作一個 Customer Segmentation.py,可以用滑鼠操作旋轉,看得更加清楚。
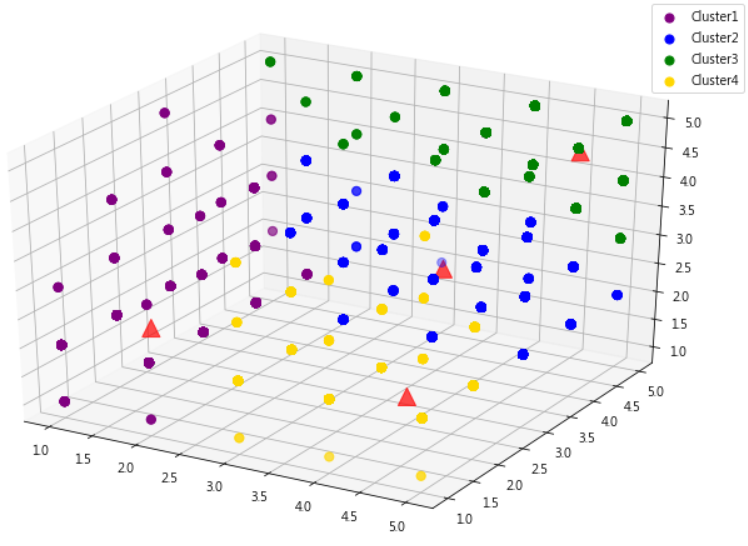
程式如下:
from mpl_toolkits.mplot3d import Axes3D
colors=['purple', 'blue', 'green', 'gold']
fig = plt.figure()
fig.set_size_inches(12, 8)
ax = fig.add_subplot(111, projection='3d')
for i in range(kmeans.n_clusters):
df_cluster=df2[df2['clusters']==i]
ax.scatter(df_cluster['Recency_Flag'], df_cluster['Monetary_Flag'],df_cluster['Freq_Flag'],s=50,label='Cluster'+str(i+1), c=colors[i])
plt.legend()
ax.scatter(kmeans.cluster_centers_[:,0],kmeans.cluster_centers_[:,1],kmeans.cluster_centers_[:,2],s=200,marker='^', c='red', alpha=0.7, label='Centroids')
實務上我們可以做得更精緻一點,例如:
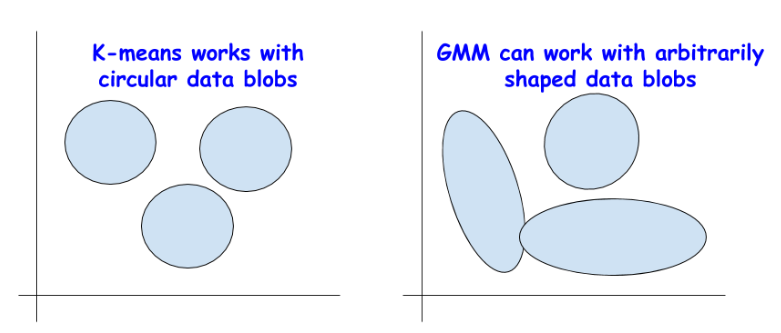
圖片來源:Clustering metrics better than the elbow-method
RFM 只是特徵工程的一種作法,實務上就是要找到真正影響目標變數的關鍵因素,最近看了一篇很好的報導,真好玩遊戲開發商董事長周玄昆指出幾個迷思:
因此他提出三項指標:
看了很有感,告訴自己,不要緊抱 RFM 教條式的作法,要掌握產業知識,找到獲利模式的關鍵特徵,才是決勝商場的利器。
相關程式碼放在這裡 的 Day02 Customer Segmentation 目錄。

