
昨天花費了不少時間談了 batch_normalization,今天來介紹 dropout 在 tensorflow 中的實作,drop 其實比 batch_normalization 簡單多了,簡單説說 dropout 吧!
Dropout 顧名思義,就是資料通過這層時,會將一部分的輸出過濾成0,有多少比例被過濾掉,可以設定它的 drop rate 來定義,反之,keep rate 就是有多少比例會被保留,因此,dropout 對資料的破壞性是比較強的,因為它直接把部分訊息抹去。
而在 tensorflow 的 API 中,我們是設定 drop rate,官方註解上說明:
rate: The dropout rate, between 0 and 1. E.g. "rate=0.1" would drop out 10% of input units.
要注意是像 tf.nn.dropout 參數就有 rate 和 keep_prob,兩者意義上相對,目前官方建議設置 rate 來使用,可別把這兩個值設反囉!
我們來看一下 tensoboard 看到的 dropout。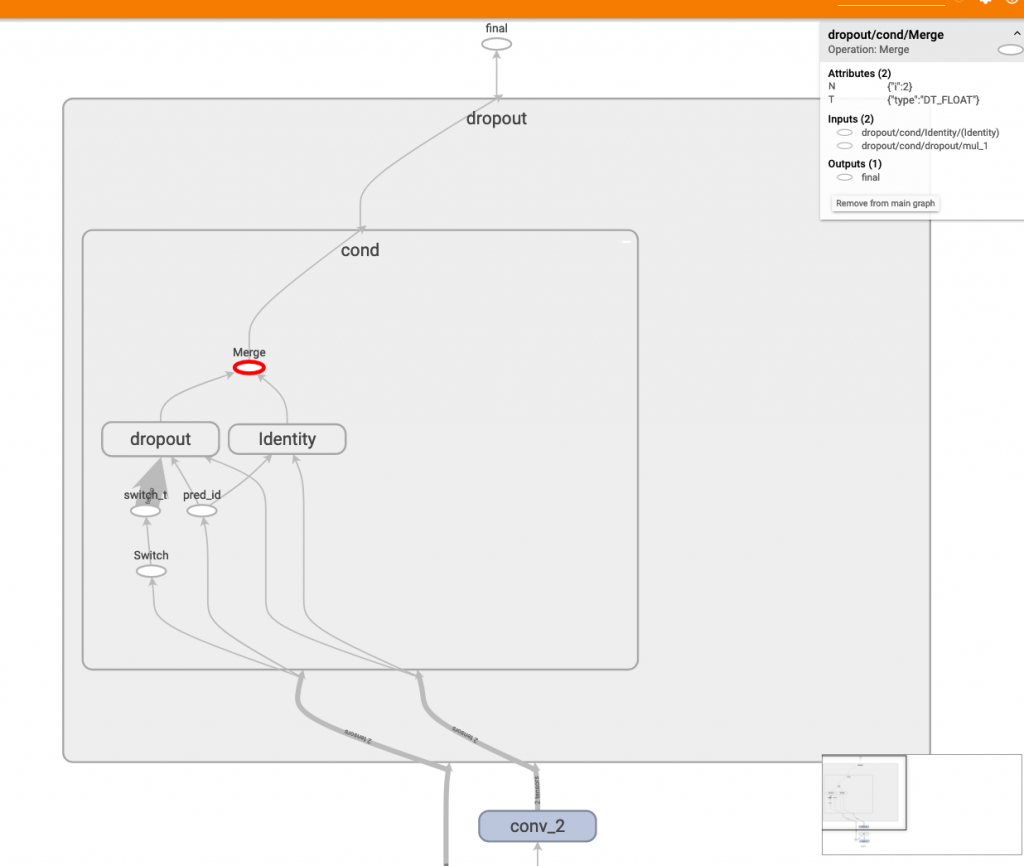
可以看到有 dropout 和 identity 兩個 subgraph,dropout 底下被 switch 控制。亦即,當為訓練模式時,資料流走 dropout 這條路,當為推論模式時,資料走identity 這條路,恩...就是這麼簡單!
最後再執行一下程式碼:
with tf.Session() as sess:
image = cv2.imread('../05/ithome.jpg')
image = np.expand_dims(image, 0)
result = sess.run(debug_node, feed_dict={input_node: image, training_node: True})
print(f'training true:\n{result[0, 22:28, 22:28, 0]}')
result = sess.run(debug_node, feed_dict={input_node: image, training_node: False})
print(f'training false:\n{result[0, 22:28, 22:28, 0]}')
可以看到如下結果: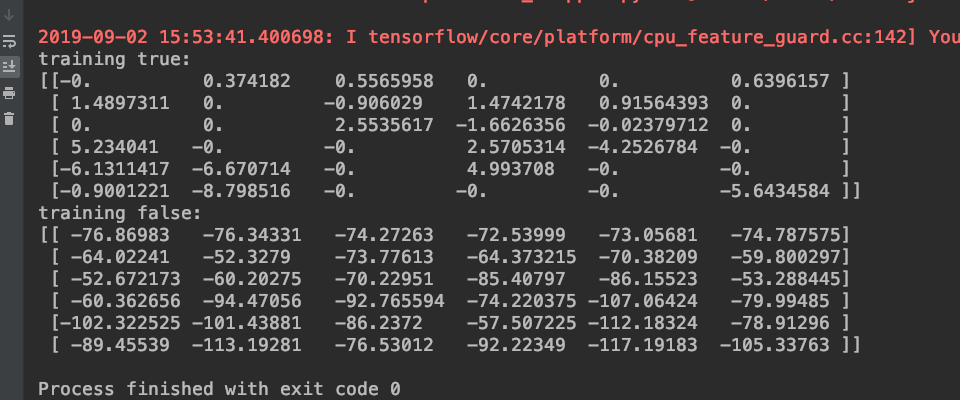
我們看到 training_node: True 時,輸出很多變成了0,而 training_node: False 時,形同沒有dropout 一般,數值直接搬過來。
今天的內容比昨天簡單很多,以上是 batch_normalization 和 dropout layer介紹,根據我自己使用心得,如果能夠使用 batch_normalization,就盡量用 batch_normalization 取代dropout,多個實驗表示 batch_normalization 比起 dropout 更有效率,當然如果你餵的資料不是 batch 型式,那就選擇用 dropout 作為手段吧。
以上希望讀者們對 tensorboard 更有感覺,我自己在 debug 模型時,很常運用上面的技巧去驗證!
ref:
Dropout VS Batch Normalization? 是時候放棄Dropout了
