從這一篇開始,我們要開始介紹一些演算法及其應用,了解 Keras 的進階用法。首先,介紹【卷積神經網路】(Convolutional Neural Networks work, CNN),以下簡稱CNN。
CNN 的原理在網路上已經有太多的說明,筆者就不再從頭介紹其原理,有興趣的讀者可以參考筆者之前的系列文章[1]、[2]、[3],這次會著重在程式的解說,包括:
在【Day 03:撰寫第一支完整的 Keras 程式】中,我們使用像素(pixel)作為辨識影像的特徵變數,但是人類應該不會以這種一點一點的比對來辨識影像,仔細觀察,以線條或輪廓辨識應該比較合理。CNN以卷積計算找出各種線條特徵,再將它們輸入至完全連接層(Dense)進行影像辨識。
CNN 一般的結構如下:
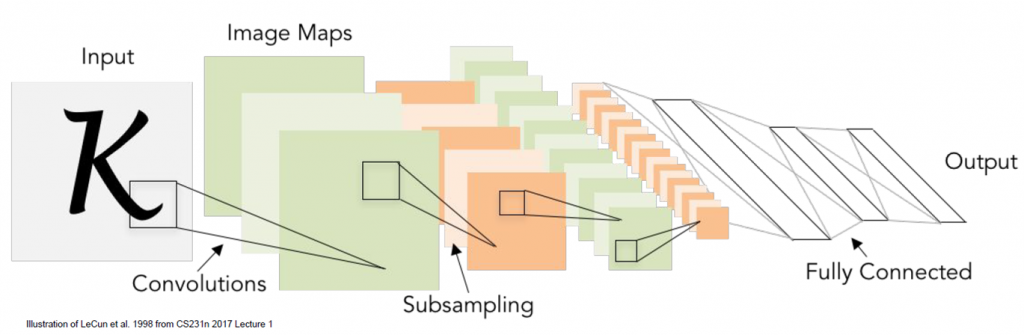
圖一. 卷積神經網路(CNN)結構,圖片來源:CS231n Convolutional Neural Networks Lecture-5

圖二. 卷積神經網路(CNN)處理
同樣辨識手寫阿拉伯數字,模型修改如下:
# 建立模型
model = tf.keras.Sequential(
[
tf.keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(10, activation="softmax"),
]
)
函數說明如下:
除了輸入,其他處理程序幾乎一樣,CNN是允許彩色影像輸入,故輸入影像須加一個維度 -- 色彩。預測時,記得樣本也要加一維。
# 加一個維度,MNIST是單色影像,故最後一維是 1,shape = (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
範例檔案名稱為11_01_CNN_MNIST.ipynb,執行結果的準確率確實有提高至98.86%。
利用不同的卷積核(kernel)作卷積運算,會有不同的效果,例如,卷積核如下,將像素以週圍像素的平均值取代,會造成模糊化的效果,目的是將去躁(Denose),將雜訊去除。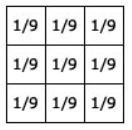
圖三. 模糊化的卷積核(kernel)
以下使用 OpenCV 的 cv2.filter2D 函數實驗卷積運算,若未安裝 OpenCV 套件,執行下列指令:
pip install opencv-python
程式如下:
# 使用cv2.filter2D進行convolution
image_name = './0_images/conv_org.png'
image = cv2.imread(image_name)
smallBlur = np.ones((7, 7), dtype="float") * (1.0 / (7 * 7))
result = cv2.filter2D(image, -1, smallBlur)
範例檔案名稱為11_02_Convolutions.ipynb,可以作出多種效果,包括模糊化(Blur)、銳化(Sharpen)、邊緣偵測(Edge detection)...等。
可以將每次卷積(Convolution)後的影像視覺化(Visualization),範例檔案名稱為11_03_CNN_Visualization.ipynb,結果如下,可以看出最後一列有些圖片可以把鳥的輪廓顯現出來。

圖四. 各卷積層處理結果
測試及閱讀文件的心得如下:
希望透過以上的程式,能對CNN更深的認識,一些細節就請大家參閱筆者之前的文章了。
以上我們利用CNN辨識手寫阿拉伯數字,其實有幾個缺點:
我們在下篇就來效能調校一下。
本篇範例包括11_01_CNN_MNIST.ipynb、11_02_Convolutions.ipynb、11_03_CNN_Visualization.ipynb,可自【這裡】下載。

