這個月的規劃貼在這邊文章中我們的基因體時代-AI, Data和生物資訊 Overview,也會持續調整!我們的基因體時代是我經營的部落格,如有對於生物資訊、檢驗醫學、資料視覺化、R語言有興趣的話,可以來交流交流!
沒有了數據的AI就是耍流氓,要發揮AI最大效果的地方就是數據飛快增長的地方,網路相關產業的數據增長,以及運算成本的下降,算是造就了這一波的AI浪潮,另一個潛伏的重要領域就是生醫產業,先不提影像、生理資訊,光談基因定序的增長和價錢的變化,就是一個超越摩爾定律的增長曲線。
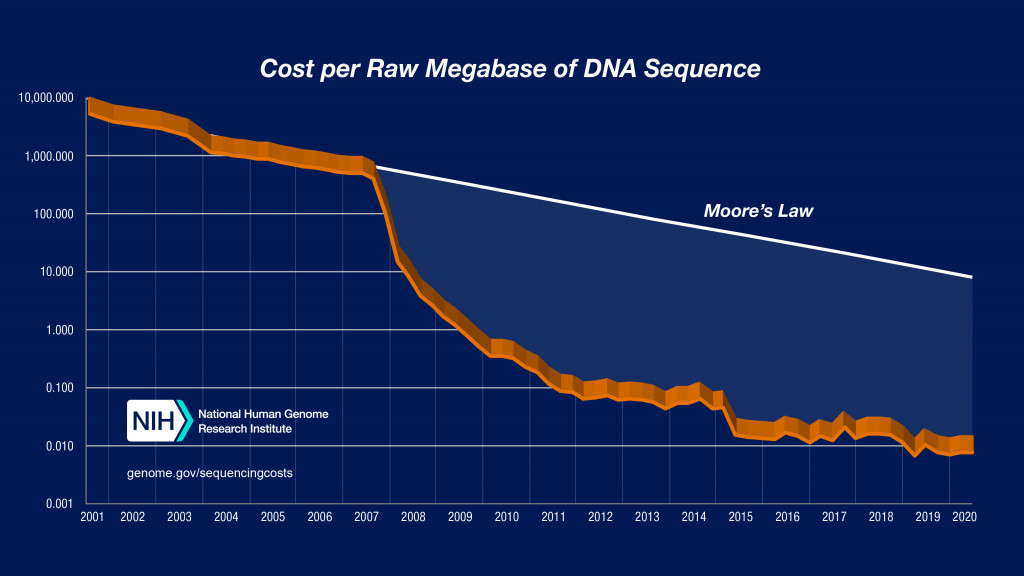
從上面這個圖可以看到,數量和價錢是反比關係的,在2003前第一個人類基因體定序的數據,花了27億美元,跟曼哈頓計劃以及阿波羅計畫並列美國20世紀的三大工程之一,如今以2021年台灣定序一個人全外顯子序列(佔一個人全部基因序列的約莫1-4%)大概只需要8000元成本價,短短不到二十年,這個成本下降的速度飛快,當然這也暗示者後續的資料儲存和分析的成本將大幅上升。所以,產生大量數據的基因體領域,一定是未來AI重要發揮的地方(已經是了),所以剛好在這一系列中來分享這個主題絕對是非常洽當的。
台灣人體生物資料庫是近年來台灣很重要的一個計畫,要收集至少二十萬人的基本資料包含健康情況、醫藥史、生活環境等,做為醫療和健康相關使用,可以看到下面的表格,是從一個人取得基因體資訊的檔案大小: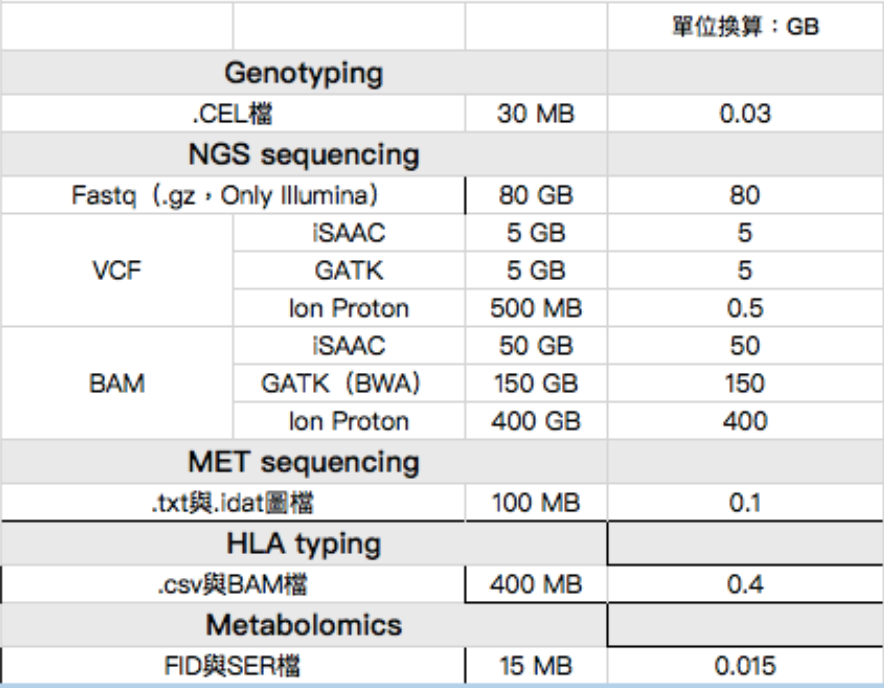
可以看到一個人單看衍生的基因體資料就要500Gb,二十萬人的話,加起來就是十萬Tb的資料大小,需要至少十台全台最頂級的高速電腦台灣山三號的儲存空間。
除了知道外來生醫產業會是一個巨量資料的儲存地外,另一個有趣的點是相對於資料產生的速度,目前資料儲存的設備的製造速度已經慢慢追不到資料產生的速度了,那解鈴還須繫鈴人,其實基因成分核酸,由A、T、C、G所組成,本身也可以用來儲存資料,只是相對於傳統資料以0和1來儲存資料,它每個位置有四個模式可以來儲存,除此之外,DNA是非常穩定的材料,我們能挖出幾萬年前的生物體,然後可以定序此生物之基因,還可以用此來知道人類的祖先,但硬碟大概能撐過十年就蠻了不起了,下面這張圖: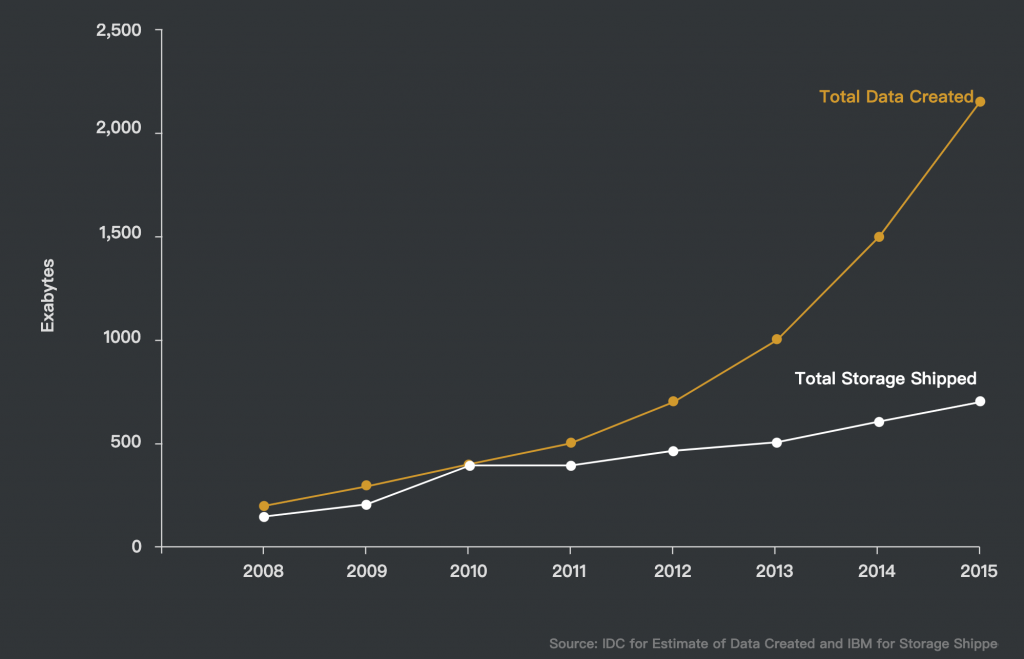
可以看到從2015年開始,這個數據產生速度遠高於資料儲存的能力已經發生了。而下面這張來在Goerge Church教授在2012年發表於Science的文章:Next-Generation Digital Information Storage in DNA,比較了現代傳統的硬碟和生物體儲存資料間,資料寫入量和資料儲存密度的差異(這是2012年的數據,現在的話,可能不論是儲存量和密度應該都遠高於過去了)。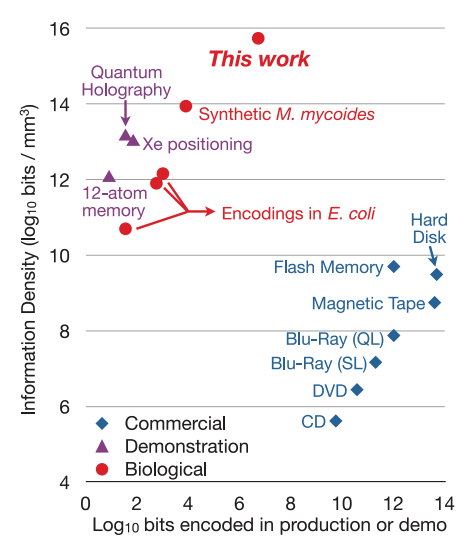
大家對於AI應用在生醫領域應該都是想到像是胸部X光片的判讀、髖骨骨折判讀等等,但實際上,對於AI的挑戰來說,基因數據才是真的困難,可能有人會雌之以鼻,美國Scripps研究中心的所長,知名的Eric Topol醫師在今年美國NIH National Human Genome Research Institute的系列演講Machine Learning in Genomics中開場有提到,可以看他的簡報: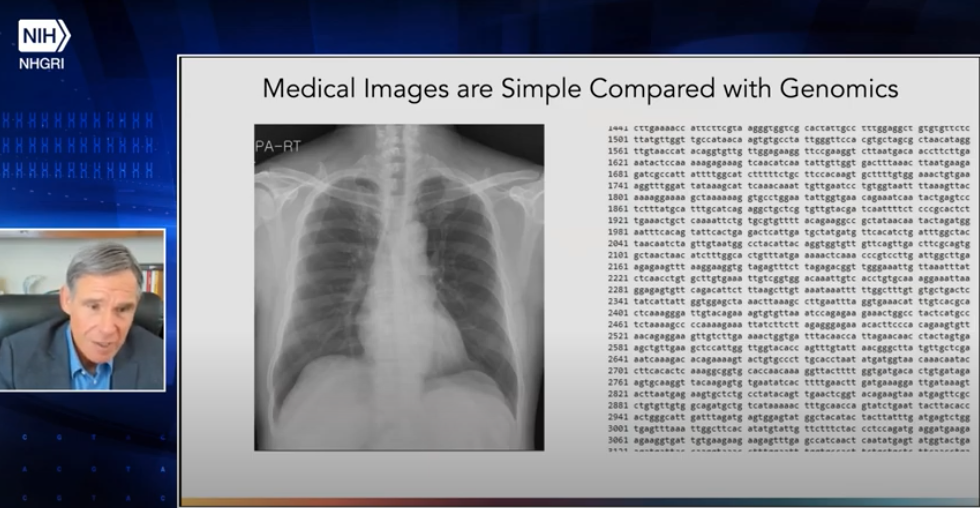
為什麼看起來比較複雜的影像會比右邊的ATCG...字串資訊複雜呢?實際上是因為影像假如由pixel組成的話,pixel之間的關聯性相對單純,且有一個固定的模式,反之,在基因資訊中,每段資訊間的關聯和互動是相當複雜的,甚至跟其在細胞中的3D立體結構有關,短短幾句話,解釋了為何基因資訊反而比左邊的胸部X光困難許多。
未來你將擁有一個數位替身,也就是一個可以代表你部分的生理模型,在2020年7月的時候美國舉行了一個腦洞大開的工作坊:Toward Building a Cancer Patient 'Digital Twin',雖然數位替身或是數位雙胞胎的概念其實在1990年在電腦科學家David Gelernter的書中有被提到,是用來作為產品生命週期管理的一個技巧,現在我們則可以用收集來自於我們身體的資訊來建立一個複雜的數位替身,並且用它來預測我們的複雜行為!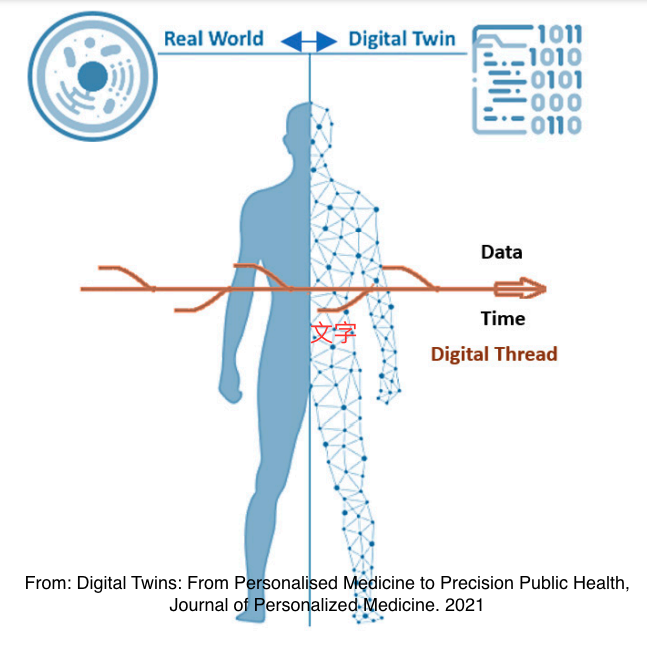
分享到這邊應該已經感受到生醫領域的資料是如此快速地增加,急須各界高手們來挖掘裡面的寶庫,這裡的資料並非都是鎖在私人機構裡的,很多都是開放開源的,只是分析的背景知識會需要比較多一點,所以需要跨領域的人一起來合作開挖這個寶庫!

