上一篇我們的基因體時代-AI, Data和生物資訊 Day04- 深度學習在基因體學的建模架構01中我們開始往下深入以一個生物問題為例,展開可以怎麼使用其中一種監督式學習的架構來回答,大部分都需要把問題轉換成可以由資料回答的方式,並且把資料整理成表格狀,一行一筆資料,一欄則是一個feature,且其中要有一個所謂的label,這邊把上一篇中提到的工具和資料稍加介紹!
首次google的時候記得使用關鍵字「fabrik deep learning」,不然會導引到其他網頁去喔。
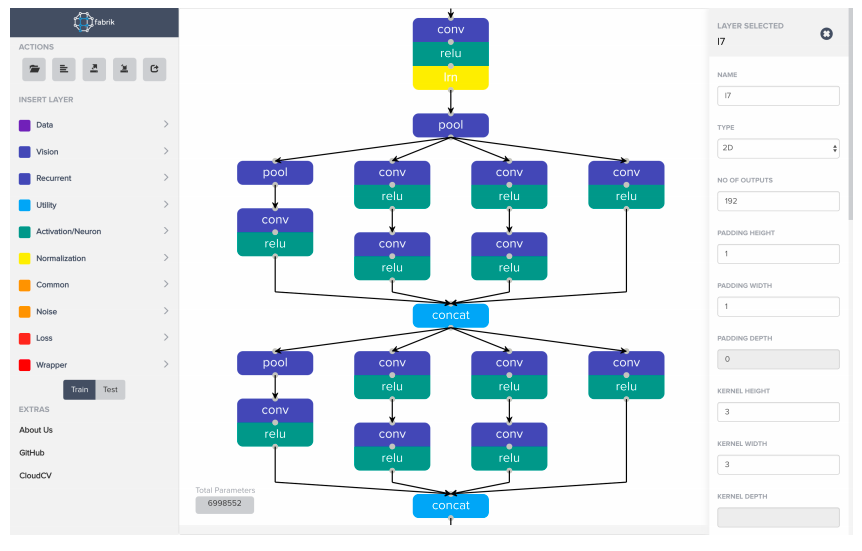
Fabrik是個模擬神經網絡連結的編輯器,提供瀏覽器中的視覺化、編輯和共享神經網絡。它可以輸入由Caffe, Keras, TensorFlow建立好的架構,這樣的好處是可以方便團隊協作和討論,同時可以將此框架輸出成不同系統相容的架構。可以到這個github的網址去看他們實際的代碼,雖然似乎2018年後就沒有再更新了,可能可以稍微自己評估一下是否嘗試使用。
相對於Fabrik在2018年停止更新許久,FloydHub算是有比較活躍的經營,他們在2016年成立,當初的願景是成為像是Heroku之於軟體工程師一樣,針對資料科學家提供服務的公司,不過令人驚訝的是他們官網上面已經在2021/08/20停止服務了,時代的眼淚,雲端深度學習的公司似乎沒有想像中好做!
這家目前還是持續營業之中,目前有兩個服務,一個是Gradient,一個是CORE,分別想要解決不同的使用者需求,Gradient提供一個即開即用的Jupyter notebook式的服務,且串接多個框架及工具如TensorFlow, PyTorch, Scikit Lear, Keras, TensorRT, TensorBoard, ONNX, XGBoost, HuggingFace, Fast.ai, RAPIDS, R, Streamlit, Jupyter, TF serving等等,另一個產品CORE,看起來是比較to B的服務,提供更高性能的運算資源。
這個平台Valohai的服務比較偏向DevOps所用的ML服務需求,且沒有像是PaperSpace的服務整合的那麼精緻,你有三個方法可以使用,第一個是可以local安裝他們的客戶端,來定義yaml後調用他們的服務,第二個是直接git他們的repository來運行,這個方式蠻有趣的,第三種則是運行他們建好的jupyter notebook來運行分析。
這個月的規劃貼在這篇文章中我們的基因體時代-AI, Data和生物資訊 Overview,也會持續調整!我們的基因體時代是我經營的部落格,如有對於生物資訊、檢驗醫學、資料視覺化、R語言有興趣的話,可以來交流交流!
閱讀參考:


 iThome鐵人賽
iThome鐵人賽