資料科學橫跨多個領域,包括統計、科學方法、人工智慧 (AI) 和資料分析,目的在於從資料中發現價值。想要進行資料科學分析,機器學習演算法是不可或缺的。
Data Science能力圖: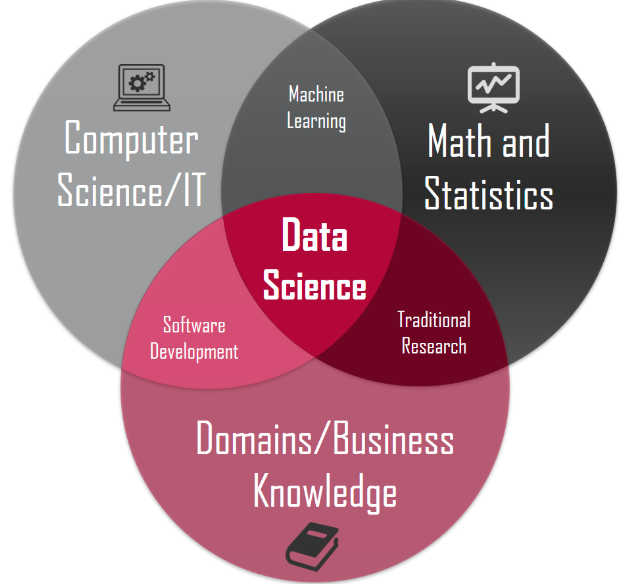
機器學習是人工智慧的分支,和傳統解決問題的不同,它是一個由電腦 從資料(經驗)中自動學習(訓練出模型)的演算法。
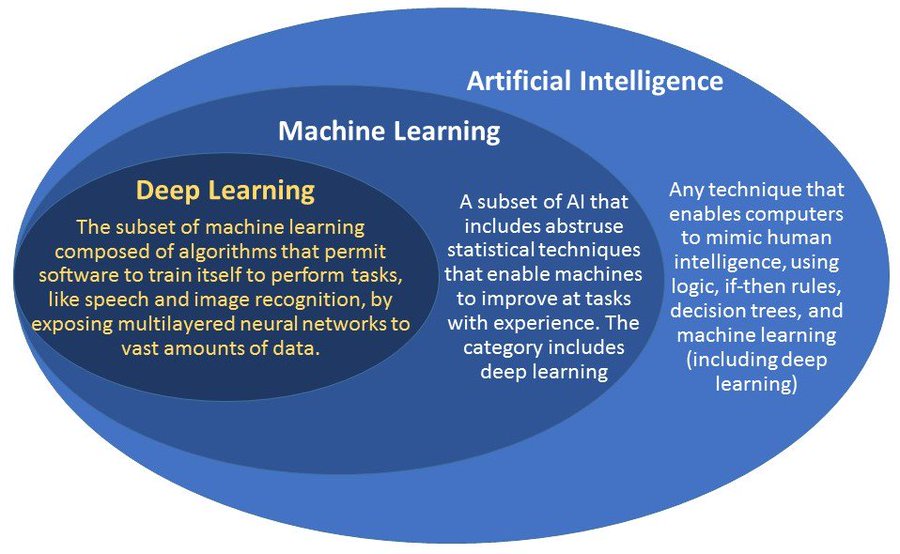
機器學習廣為人知的定義:
[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed.
Arthur Samuel, 1959
工程導向的定義:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks on T, as measured by P, improves with experience E.
Tom Mitchell, 1997

由於機器學習模型的方便和準確性高,搭配現在電腦高強度的運算能力,它常常被應用於圖像識別、語音識別、醫療診斷、文字、網頁分析...等領域。
機器學習種類大概可以分成以下幾種: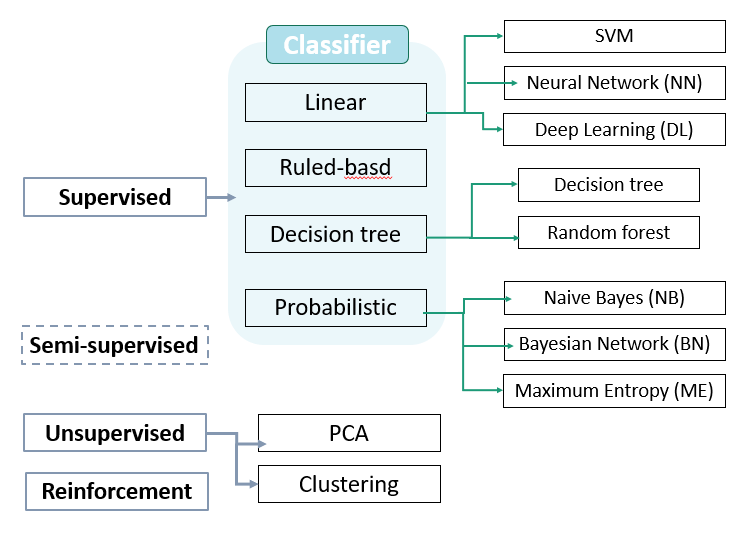
放入模型中的訓練資料(Y)是被標記好的(Labeled),從資料中學習,我們可以建立出一個模型去進行機率推論(Inference)或是預測(Prediction)。
「機率推論」可以得知輸出變項Response/Output 跟輸入變項Predictors/Input 之間的關係性,例如正相關、上升趨勢等等。「預測」則是能讓人輸入未知結果的輸入值,計算出結果。
沒有Supervising output(沒有標記好的類別或數值Y),但是我們能藉由機器學習去了解資料裡的結構和關係,並展現資料可能是怎麼樣的組成或是分群的狀況。
半監督式學習是指一小部分的資料是被標記好的,而大部分資料是Unlabeled的訓練資料,且Unlabel的資料遠大於Label的資料。
提供了一個環境(Environment/ Simulation System)給機器去學習,但是「強化學習」不像「監督式或非監督式」學習一般,這個環境裡會有錯誤的標記(結果)出現,所以我們需要安排給予懲罰項(Reward and Penalty)對機器的決策(Action)做反應,在這個環境下重複做決策進行學習就是「強化學習」。
各種前置作業、簡單介紹的部分就到這裡~
從明天開始就正式要來介紹各種不同的機器學習方法和程式碼應用了!!
以前上機器學習課程的筆記
機器學習
https://zh.wikipedia.org/zh-tw/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0
什麼是資料科學?
https://www.oracle.com/tw/what-is-data-science/
圖片來源:
Data Science能力圖
https://www.fox.temple.edu/institutes-and-centers/data-science/
What is the difference between AI, machine learning and deep learning?
https://www.geospatialworld.net/blogs/difference-between-ai%EF%BB%BF-machine-learning-and-deep-learning/
感謝網路上各種圖片支援~

