今天要來補充前面幾天曾提過的機個非線性的監督式學習分類演算法的 PYTHON 程式碼,包括 KNN(K鄰近法)、 SVC(支援向量機分類, Support Vector Classifiers)、 TREE(決策樹, Decision Tree)、 RF(隨機森林, Random Forest)。
資料是使用 Iris Dataset ,可以從sklearn套件中取得。問題的目標是想來分類 Iris 是否為 "Virginica" 這個類別,因此這是一個二元分類的範例。
慣例先去載入常用的套件:
## import慣例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels as sm
## Common imports
import sys
import sklearn # scikit-learn
import os
import scipy
## plot 視覺化
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
以及接下來會使用到的套件:
## 分割資料
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
## 報表結果、模型評估
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
## modelbuilding 各模型套件
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
[補充]獲取資料後最好先去觀察資料,並進行一下EDA:
from sklearn import datasets
## 如果你的資料是dataframe:
df = datasets.load_iris(as_frame=True).frame #整個資料 DataFrame 包含X、Y
df_x = datasets.load_iris(as_frame=True).data # X(特徵內容)
df_y = datasets.load_iris(as_frame=True).target # Y (分類結果)
## 觀察資料
df.head() #觀察資料
## 5個變數, 4個解釋變數X(sepal length (cm),sepal width (cm),petal length (cm),petal width (cm)), 1個目標變數Y(target)
#print(df.shape) # shape
#print(dataset.describe()) # Statistical Summary
#print(df.groupby('target').size()) # 'setosa', 'versicolor', 'virginica'的資料數量分別有多少
## EDA & Data Visualization
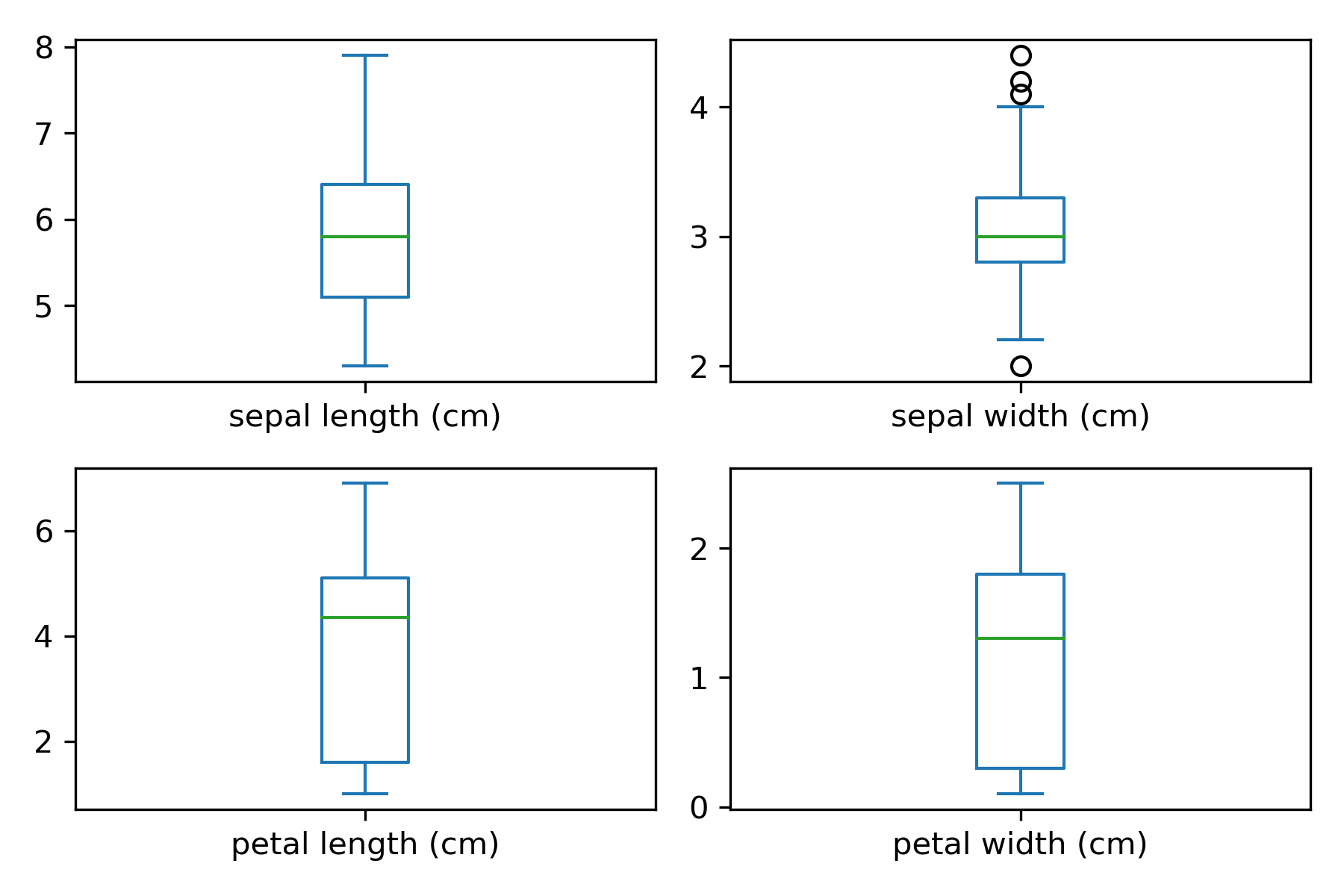
# box and whisker plots
df_x.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
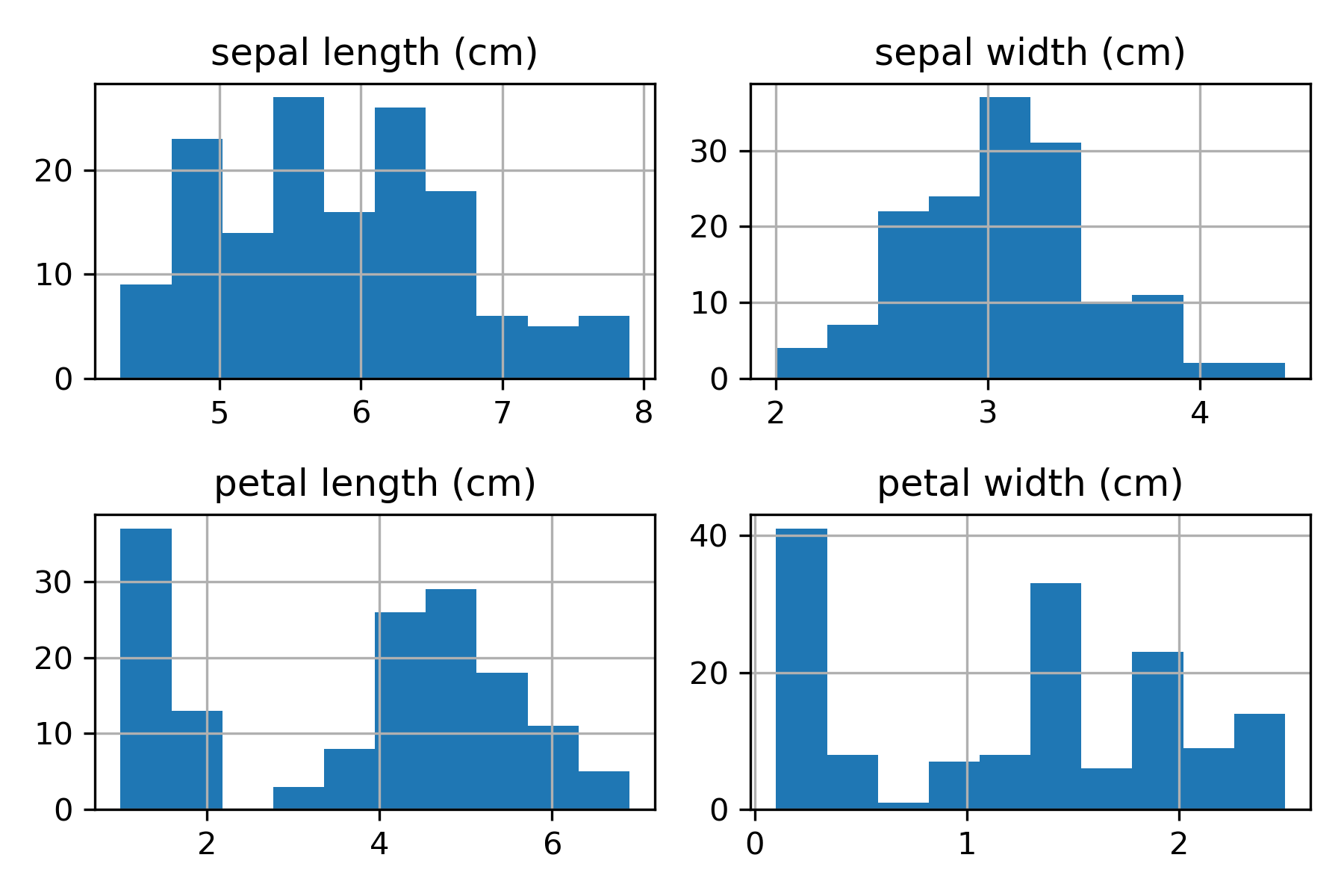
# Histogram
df_x.hist()
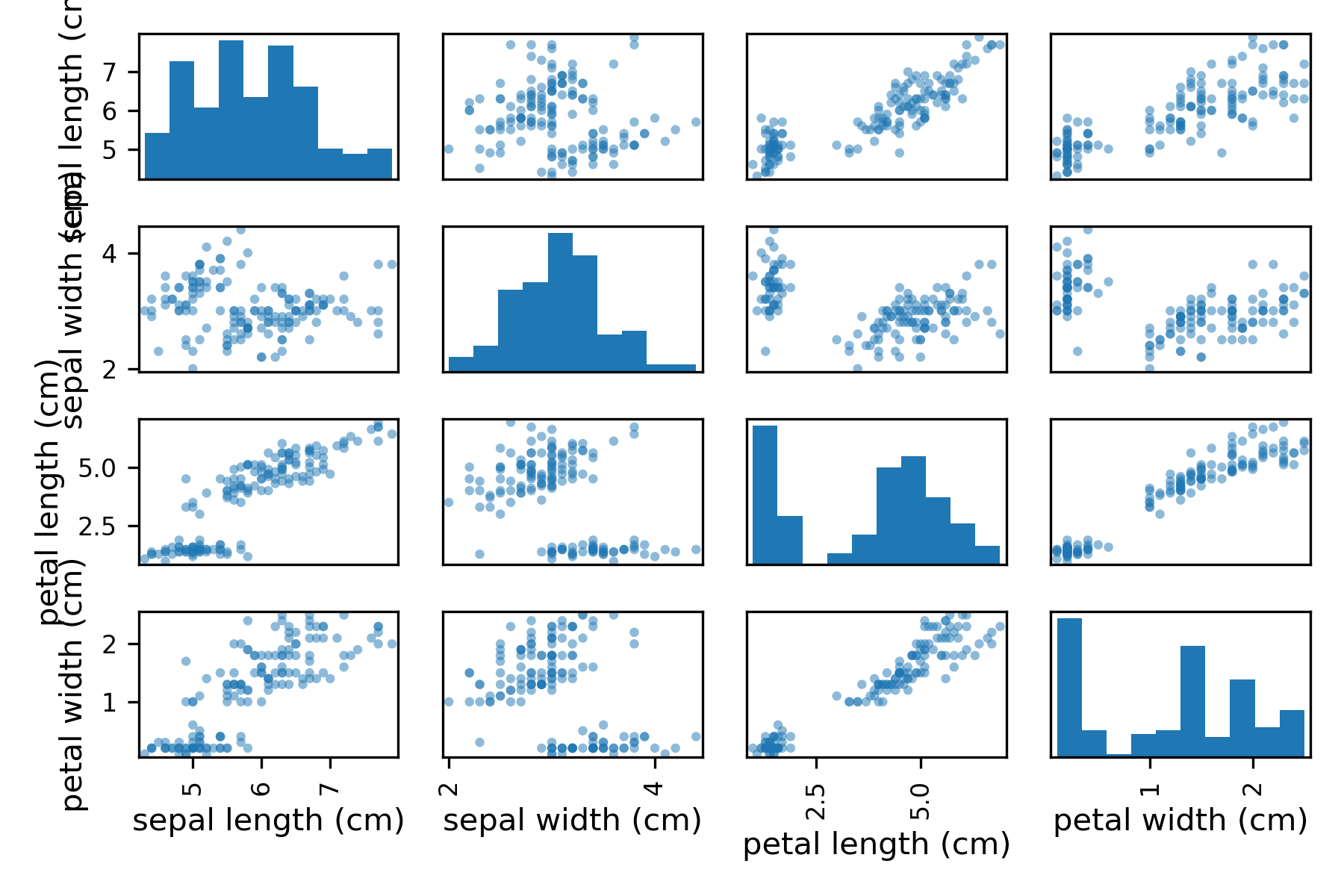
# scatter matrix plot
scatter_matrix(df_x)
EDA 和資料視覺化的部分之前講過了,所以回到正題,獲取要使用來建模的資料Iris Dataset:
## Load Iris Dataset
from sklearn import datasets
X, y = datasets.load_iris(return_X_y=True)
y = y == 2 #0, 1 是否為 Iris- 'virginica'
# 分割資料 Split-out test dataset 80% training data 20% testing(test) data
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
接著開始建立模型,我們可能會建立很多模型,再去看哪個表現比較好,進行模型選擇,把它決定為最終模型:
這裡把多個建立的模型組合稱作models,並輸出各模型使用 cv 的方式計算出的 平均validation error和validation errors的標準差。
# Spot Check Algorithms
models = []
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('RF', RandomForestClassifier(n_estimators=100, random_state=1)))
models.append(('SVM', SVC(gamma='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)
#使用 cv ,並用validation data 計算 validation error 判斷哪種模型比較好
cv_results = cross_val_score(model, x_train, y_train, cv=kfold, scoring='accuracy')
results.append(cv_results)
names.append(name)
print('%s: %f (%f)' % (name, cv_results.mean(), cv_results.std()))
LDA: 0.941667 (0.065085)
KNN: 0.950000 (0.040825)
CART: 0.933333 (0.062361)
RF: 0.941667 (0.038188)
SVM: 0.975000 (0.038188)
當然也可以去視覺化,讓人能一眼看出各演算法模型的表現:
# Compare Algorithms
plt.boxplot(results, labels=names)
plt.title('Algorithm Comparison')
plt.show()
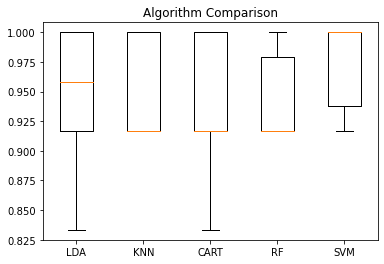
這邊可能覺得 SVM classifier 的模型表現最好,想以 SVM classifier 作為最終選擇的模型,所以我們進一步用模型去預測 測試集資料(test data) ,進而得到一些指標供我們去做模型評估。
## 這邊假設覺得 SVM classifier的模型表現最好,想以 SVM classifier 作為最終選擇的模型
model = SVC(gamma='auto')
model.fit(x_train, y_train)
predictions = model.predict(x_test)
# Evaluate predictions
# # 0:'setosa', 1:'versicolor', 2:'virginica'
print(accuracy_score(y_test, predictions)) #準確率
print(confusion_matrix(y_test, predictions)) # 混淆矩陣confusion matrix
print(classification_report(y_test, predictions))
0.9666666666666667 #準確率
##混淆矩陣:
[[23 1]
[ 0 6]]
##各種模型指標
precision recall f1-score support
False 1.00 0.96 0.98 24
True 0.86 1.00 0.92 6
accuracy 0.97 30
macro avg 0.93 0.98 0.95 30
weighted avg 0.97 0.97 0.97 30
當我們有一個二元的混淆矩陣時,我們可以將結果歸類成以下模式的矩陣:
| \ | 實際分類 YES | 實際分類 NO |
|---|---|---|
| 模型預測 YES(Positive) | TP(True Positive, 真陽性);6 | FP(False Positive, 假陽性);1 |
| 模型預測 NO (Negative) | FN(False Negative, 假陰性);0 | TN(True Negative, 真陰性);23 |
| 模型評估指標 | 計算方式 | 計算、說明 |
|---|---|---|
| precision(精準度) | TP/(TP+FP) | 預測為正(+)時,實際上真的是正(+)的比例。 |
| recall(召回率) | TP/(TP+FN) | 真實的正(+)中,成功預測出了多少的比例。 |
| f1-score | 2 ‧ [precision ‧ recall/(precision+recall)] | 調和平均數,兼顧準確率和召回率。 |
| support | TP+FP or TN+FN | 那個類別的真實數目。 |
| accuracy(準確率) | (TP+TN)/(TP+FP+FN+TN) | 整體資料預測正確的比例。 |
| macro avg(宏觀平均) | (True+False的指標)/2 | |
| weighted avg(加權平均) | (指標 ‧ support數目)/all 進行加權平均 |
其他衡量指標還包括:
靈敏度 Sensitivity (=Recall):TP/ (TP+ FN),true positive rate,真實的正(+)中,成功預測出了多少的比例。
特異度 Specificity:TN / (FP + TN),true negative rate,真實的負(-)中,成功預測出了多少的比例。
1-Specificity:
1-Specificity = FP / (FP + TN) ,即為 false positive rate。
1-Specificity的值對應 Sensitivity的分布情況可以畫成 ROC Curve,計算ROC Curve 曲線下面積可以得到 AUC (Area Under Curve), AUC 值越大,代表分類模型的正確率越高。
[Example] 對照報表結果,這邊再示範一次使用混淆矩陣做評估指標的計算。
報表結果:
> print(confusion_matrix(y_test, predictions))
> print(classification_report(y_test, predictions))
##混淆矩陣:
[[23 1]
[ 0 6]]
##各種模型指標
precision recall f1-score support
False 1.00 0.96 0.98 24
True 0.86 1.00 0.92 6
accuracy 0.97 30
macro avg 0.93 0.98 0.95 30
weighted avg 0.97 0.97 0.97 30
\ | True(1) | 實際 1 | 實際 0 | | | False(0) | 實際 0 | 實際 1 |
------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | ------------- | -------------
| 模型預測 1 | TP=6 | FP=1 | | | 模型預測 0 | TP=23 | FP=0 |
| 模型預測 0 | FN=0 | TN=23 | | | 模型預測 1 | FN=1 | TN=6 |
| \ | precision | recall | f1-score | support |
|---|---|---|---|---|
| 0 | 23/(23+0)=1.0 | 23/(23+1)=0.958 | 2x(1x0.958/(1+0.958))=0.978 | 24 |
| 1 | 6/(6+1)=0.857 | 6/(6+0)=1.0 | 2x(0.857x1/(0.857+1))=0.922 | 6 |
| accuracy | (6+23)/(6+1+0+23)=0.966 | |||
| macro avg | (1+0.86)/2=0.93 | (0.96+1)/2=0.98 | (0.98+0.92)/2=0.95 | 30 |
| weighted avg | (1x24 + 0.86x6)/30=0.972 | (0.96x24 + 1x6)/30=0.968 | (0.98x24 + 0.92x6)=0.968 | 30 |
在比較不同的二元分類模型時,可以將每個模型的ROC曲線都畫出來,比較曲線下面積做為模型優劣的指標。
AUC (Area Under Curve)曲線下面積 的值越大,代表分類器的正確率越高。
使用sklearn.metrics套件裡的RocCurveDisplay,可以協助畫 ROC Curve 。
⇒ 但須注意sklearn的版本,若是出現 ERROR,可以先去檢查套件版本:
print('sklearn: {}'.format(sklearn.__version__))
建議使用 sklearn:1.0 以上的版本,若是版本為舊版,可以到 Anaconda Prompt 執行以下程式碼更新版本。
pip install --upgrade scikit-learn
## ROC Curve #比較不同模型,例如 決策樹 和 隨機森林
from sklearn.metrics import RocCurveDisplay
ax = plt.gca()
DT=DecisionTreeClassifier().fit( x_train, y_train)
DT_disp = RocCurveDisplay.from_estimator(DT, x_test, y_test, ax=ax, alpha=0.8)
RF=RandomForestClassifier(n_estimators=100, random_state=1).fit( x_train, y_train)
RF_disp=RocCurveDisplay.from_estimator(RF, x_test, y_test, ax=ax, alpha=0.8)
plt.show()
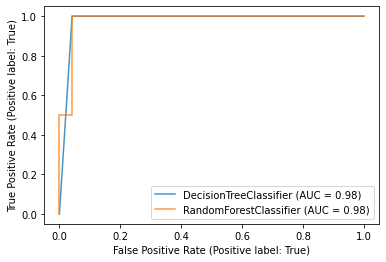
這裡可以看到兩模型的 AUC 相同,模型的預測能力差不多。
from sklearn.metrics import RocCurveDisplay
ax = plt.gca()
for model in models:
RocCurveDisplay.from_estimator(model[1].fit( x_train, y_train), x_test, y_test).plot(ax=ax, alpha=0.8)
#plt.show()

同張圖內用 ROC Curve 比較多個不同模型。但是這樣圖會比較亂,不建議一次話太多模型在同張圖,可以挑幾個出來即可。
當分類的類別不只有兩類時,可以針對各類別畫出多個 ROC Curve ,去對各類別預測做模型比較,這裡就不進行補充了。
相關程式碼可以參考網路上Multiclass Classification Problems Using the Iris Dataset 的範例 by Scott Miner。
Your First Machine Learning Project in Python Step-By-Step. (@Jason Brownlee)
https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
ROC Curve with Visualization API
https://scikit-learn.org/stable/auto_examples/miscellaneous/plot_roc_curve_visualization_api.html#sphx-glr-auto-examples-miscellaneous-plot-roc-curve-visualization-api-py
Plots and Discusses ROC curves for Binary and Multiclass Classification Problems Using the Iris Dataset(@Scott Miner)
https://scottminer.rbind.io/post/roc-curves/

