在上篇中完成 TensorFlow 開發環境後,接下來我們就可以透過 TensorFlow,搭配上 Keras API 的輔助,來完成各種機器學習和深度學習的問題了。本文會以TensorFlow 官方在 Colab 的教學做為主要的參考資料,在 TensorFlow 的基礎應用中說明其流程與功能。
TensorFlow 的模型流程如下:導入套件(Import)-> 讀取資料集(Load Datasets)-> 定義模型(Refine)-> 編譯模型(Compile)-> 訓練模型(Train)-> 評估模型(Evaluate)-> 部屬模型(Deploy)
[1]
Keras 是一個基於 Python 所編寫的開源神經網路庫,專注於介面友善、模組化和可擴充性,這也是為何我們會大量應用 Keras。而 Keras 能使深度神經網路的運作更快,並支持多種不同的神經網路架構,包括卷積Convolution、和遞迴 Recurrent…等。
Keras 是甚麼?對我有什麼幫助?
Keras 是一個基於 Python,所編寫的開源神經網路資料庫,用意在於使深度神經網路的運作,能使運行 CNN、DNN、以及 RNN 時都可以更加快速。
Keras 與 TensorFlow 的關係是甚麼?
Keras 是 TensorFlow 的高階 API 之一,可應用 TensorFlow 的底層功能,因此 Keras 本身具有良好的可擴展性。
對我在學習 Tensor Flow 有什麼幫助
由於 Keras 可加速深度神經網路的運作,便可以省下諸多時間成本,提高產能。
Keras 有甚麼需要了解的架構?
(1.) 核心概念:Model 與 Layer 的關係
Model 是神經網路模型的核心概念,由一個或多個 Layer 組成。Layer 是 Model 中的功能模組,可以包含於 Model 之中進行訓練和推理。Keras 中的 Layer 可以分為以下幾種類型:
A. 輸入層:用來接收輸入數據。
B. 轉換層:用來對輸入數據進行轉換。
C. 隱藏層:用來學習數據的表示。
D. 輸出層:用來生成輸出結果。
(2.) Keras 提供了 Sequential 和 Functional 這兩種模型
Sequential 模型是一種線性的模型構建方式,由一個或多個 Layer 組成,每一個 Layer 的輸出會做為下一層的輸入,因此適合如 MNIST 手寫數字識別的簡單模型。
Functional 模型使建立架構方式更加靈活的模型,可以用來構成具有多輸入、多輸出或非線性的模型,適合複雜如自然語言處理的模型。
程式的最一開始,我們要在程式中導入 TensorFlow 套件,以及其他必要套件:
`import tensorflow as tf
print("TensorFlow version:", tf.__version__)`
Google Colab 引用了MNIST 資料集,這是一個包含6萬張訓練圖片還有1萬張從0到9的手寫數字的圖像資料庫數據集,是機器學習初學者容易上手的數據集之一。[2]
mnist = tf.keras.datasets.mnist
我們把 MNIST 中的圖像灰階值設定在 0 到 255,這代表每一個像素都有它的值,而0代表黑色、255 代表白色,我們便將樣本數據從整數轉換成TensorFlow支援的浮點數
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
我們將使用相對簡單的 Sequential 執行分析,我們可以透過 Keras 的網路層指令,將 MNIST 數據庫分為四層的 Layers,依序是
(1) 展開層 Flatten Layer:先將 28x28 的影像轉換成一維向量
(2) 全連接層 Dense Layer:具有 128 個單位與 ReLU 啟用函數
(3) 漏失層 Dropout Layer:隨機拋棄其中 20% 的神經元避免過擬合(Overfitting)
(4) 全連接層 Dense Layer:這層具有10個神經元,使用 Softmax 函數
程式碼如下:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10)
])
接下來我們便可以在訓練集的第一個圖像上運作模型,看會預測出甚麼結果:
predictions = model(x_train[:1]).numpy()
predictions

然後使用 Softmax 函數將預測結果轉換為隨機分佈之程式碼如下:
tf.nn.softmax(predictions).numpy()

最後再利用 Keras 中的 “稀疏類別交叉熵” 的函數來定義 Loss Function。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
loss_fn(y_train[:1], predictions).numpy()

注意在定義 Loss Function 時,需要根據模型的輸出和目標值來選擇合適的函數。 Loss Function中採用 Ground truth value 以及邏輯向量來計算許多指標,並回傳純量值。在訓練(Training)以及驗證(Validation)準確度的時候,便可以將 Loss Function 用於評估模型的性能優劣,並找出改進模型的方向。[4]
接下來就可以對模型進行編譯,指定 Optimizer、Loss Function 和設定評估指標。其中我們使用 Optimizer(優化器)做為更新模型參數的演算法:
model.compile(optimizer='adam', loss=loss_fn, metrics=['accuracy'])
而後就可以開始使用訓練集,對模型進行訓練。訓練過程是通過不斷迭代(Iteration)模型參數使 Loss 達到最小化;而迭代的次數就是 epoch。
model.fit(x_train, y_train, epochs=5)
上述方法一般在驗證集或測試集中的Model.evaluate上,做檢查模型的性能
model.evaluate(x_test, y_test, verbose=2)
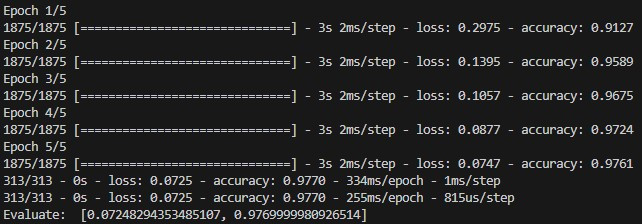
這時可以發現我們的準確率來到了 97.7%,便可以開始進行下一步
現在整個 TensorFlow 模型已經透過上述方式,在資料集中訓練到 98% 的準確度了。這時我們可以透過打包整個訓練好的模型附加 softmax,將模型的輸出轉換為預測機率:
probability_model = tf.keras.Sequential([
model, tf.keras.layers.Softmax()])
probability_model(x_test[:5])

執行這個行為的理由何在呢?
因為 softmax 可以將模型的輸出,轉換為具有鑑別度和與其機率分佈,減少模型的誤判率。也可以根據需要調整輸出的機率分佈,可塑性很高。[5]
這樣我們就完成一次基本的 TensorFlow 的模型訓練了!
[1] Introduction to Keras for Engineers:https://keras.io/getting_started/intro_to_keras_for_engineers/
[2] MNIST:https://en.wikipedia.org/wiki/MNIST_database
[3] Overall Code for Demonstration:https://www.tensorflow.org/tutorials/quickstart/beginner
[4] Ground Truth Value:https://domino.ai/data-science-dictionary/ground-truth
[5] Intro to Softmax for Neural Network:https://www.analyticsvidhya.com/blog/2021/04/introduction-to-softmax-for-neural-network/


 iThome鐵人賽
iThome鐵人賽