昨天使用了Pix2Pix來修復圖像,不知道各位的Pix2Pix有沒有得到好的成果,同時也希望各位可以試試看將Pix2Pix應用在其他影像處理的任務中。今天要來介紹本系列的最後一個GAN了,因為只有30天,礙於篇幅我決定先介紹這些GAN,其他有名的GAN例如CycleGAN、StackGAN、InfoGAN等就等之後有機會再來介紹吧。
SRGAN (Super-Resolution Generative Adversarial Network)於2016年9月被提出。SRGAN的應用層面主要是在圖像增強和圖像修復方面,例如可以用於提升低分辨率的影像、影片或醫學影像的品質,或者用於恢復受到雜訊、模糊或壓縮等影響的圖片。SRGAN主要也是使用CNN層並定義了一個與傳統GAN不同的損失函數,這個GAN能夠將一張圖片轉為長寬都放大四倍的高分辨率圖片。
本篇所使用的圖片均出自於原始論文!
下圖是SRGAN與其它超分辨率模型的對比,其中bicubic是直接將原圖放大四倍,並透過插值法將圖片像素補齊,可以看到比較模糊;接著使用超分辨率的殘差網路 (SRResNet)效果好一點,但某些細節還是有些模糊;而SRGAN效果就比前兩者好,一些細節的把控也有到位。
接著來看看SRGAN的模型架構,SRGAN的生成器與判別器都有許多細節可以注意。
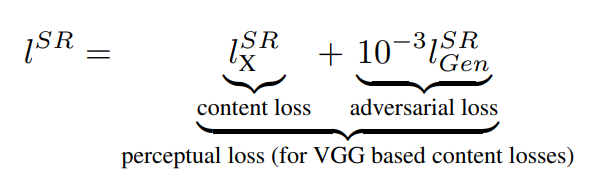
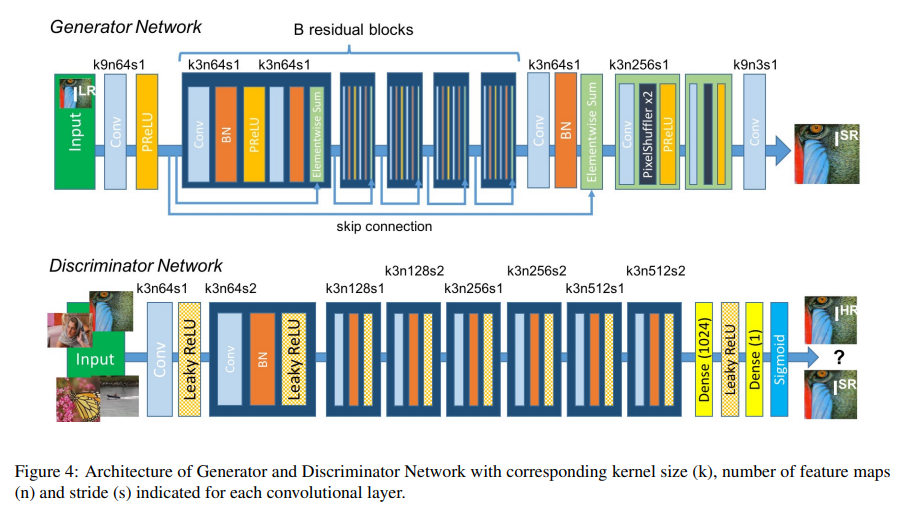
另外剛剛提到的VGG網路可能也有許多人有疑問,這是把一個神經網路用在SRGAN裡面嗎?是的,VGG網路就是直接被應用到SRGAN的對抗模型中作為計算Perceptual Loss的方式,並跟判別器判斷結果一起計算損失並給生成器訓練優話。VGG網路是一個已經預訓練好的網路,可以根據使用者來決定要使用幾層網路至其他任務中,這個使用預訓練模型的方式稱為遷移學習 (Transfer Learning)。作者於SRGAN中使用VGG19,也就是使用了19層網路。
下圖為Perceptual Loss的公式部分,看到一大串英文頭真的很痛,不過釐清符號代表的意思就很簡單了。
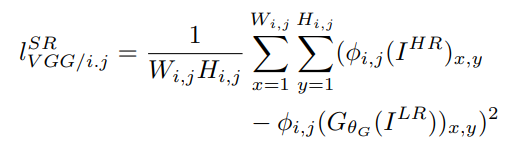
最後對抗模型的目標函數就與原始GAN的目標函數相同,只是符號不同而已。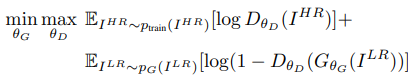
SRGAN與GAN不同的點也有許多:
今天介紹了SRGAN,SRGAN對於圖片轉成高清圖有許多幫助,也可以將圖片的解析度提升許多。明天會來帶各位實作mnist的圖片超分辨率轉換,具體做法基本上就將mnist的解析度降低,由原本的28*28變成7*7的大小,然後再經過SRGAN生成比較高清的圖片,也就是原始圖片,這樣子進行生成就是我們明天的任務了。在GAN結束後就會來講講數學理論最麻煩、複雜的擴散模型,希望各位能夠盡力去理解這些生成式AI的細節。

