筆者透過觀察身邊的人發現使用chatgpt做vibe coding上,最容易讓人暴怒的點就是ai擅自更改了不想被更改的程式碼,也不會告訴使用者,並且比較健忘,說過不要隨意更改了,對話一陣子又會做出一樣的事情,gemini相對於gpt又更加健忘,常常造成程式碼越寫越煩躁的跡象,和AI討論後得出以下幾點問題:
📝 擅自修改程式碼卻不告知原因
🧠 健忘症嚴重,前一分鐘的約定下一分鐘就忘
😤 不懂讀空氣,無法察覺使用者的挫折感
🔄 重複犯錯,讓開發體驗越來越糟糕
理想上,筆者希望EmoRAG整合AI編程助手能夠:
🔍 記住你的偏好:將你的程式風格和約定儲存起來
📚 累積互動歷史:學習你的工作模式和習慣
⚡ 即時檢索相關脈絡:在每次互動中調用相關經驗
所以希望透過RAG模型在30天內做一個入門學習筆記,並且理論和實務並進,
實務上,模型訓練之類的需要比較多時間,這邊只會做一個讀者也可以一起學習的簡單程式。
理論上,會比較傳統特徵工程和RAG的使用情境、如今AI編程工具生態分析、看到解決AI編程工具有的四點問題的可能性。
檢索增強生成 (RAG) 是 Meta 於 2020 年推出的框架,可將 LLM 連接到您的外部數據。最先進的 LLM 結合了三種技術:檢索、增強和生成,它們協同工作,為我們提供最新且準確的資訊。
通過結合這三種技術;RAG 生成流暢的對話式答案(就像 ChatGPT 一樣),同時也從可靠來源提取數據。
詳細介紹可見此文章
舉例來說,當有人問「牙周病手術要花多少錢?」
先到外部來源(如健保網站、醫療院所公告、醫療相關文件)搜尋與「牙周病手術費用」相關的最新資訊。
將剛剛檢索到的外部醫療費用資訊,跟自己知識結合,把這些內容(例如費用範圍、健保補助規定)當成輔助材料餵給生成模型。然後模型就能根據查到的資料,生成貼合問題情境、具體且有參考依據的自然語句,而不是照抄知識來源。
用自己的語言重組擴增的資料,給出「牙周病手術在台灣多數項目由健保補助,部分特殊手術需自費,金額會根據醫院及治療方式不同而變動,大約落在150到470元之間」這樣的答案。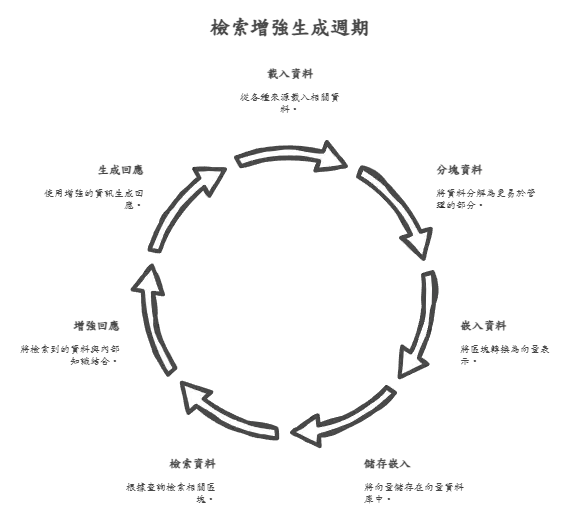

import langgraph
from deepface import DeepFace
import chromadb
import streamlit as st
# 建立EmoRAG專案結構
def setup_emorag_project():
"""初始化EmoRAG專案結構"""
project_structure = {
'data/': ['text/', 'images/', 'videos/'],
'models/': ['text_emotion/', 'image_emotion/', 'video_emotion/'],
'agents/': ['retrieval/', 'generation/', 'emotion/'],
'experiments/': ['baselines/', 'comparisons/']
}
return create_project_dirs(project_structure)
文章重點:將八種reasoning models和八種specialized tools做分類比較
Reasoning Models (8個)
ChatGPT系列:GPT-5統一推理系統、GPT-5 Thinking深度推理、GPT-4.1 mini高效方案
Claude系列:Sonnet 4領先72.7% SWE-bench、3.7混合推理模型
Gemini系列:2.5 Pro目前編程最強63.8%、2.0 Flash多模態支援
Specialized Tools (8個)
v0.dev(前端專精)、Bolt.new(全棧生成)、Cursor AI(AI-first IDE)、GitHub Copilot(廣泛採用)、Replit AI(雲端IDE)、Continue.dev(開源方案)、Tabnine(企業隱私)、Windsurf(次世代IDE)
文章重點:推理機制差異分析,ChatGPT-5智能路由系統 vs Gemini 2.5 Pro編程領先 vs Claude Sonnet 4.5解釋性最強
文章重點:專門工具技術路線,前端開發、全棧應用、大型專案、團隊協作四大場景對比
文章重點:1M tokens實際價值分析,Gemini 2.5 Pro超長上下文 vs Claude 3.7高品質處理 vs GPT-4.1平衡方案
綜合分析:變更說明、記憶技術、情緒感知、錯誤防範的現有方案成熟度
前沿探討:Agentic AI發展、本地部署趨勢、混合雲架構、技術標準化
實用導向:FAANG採用策略、新創vs企業差異、ROI計算實例、風險評估
設計重點:持久化記憶與上下文管理。
設計重點:持久化記憶與上下文管理。
設計重點:版本控制與變更說明機制
設計重點:版本控制與變更說明機制
設計重點:情緒辨識與回應策略
設計重點:情緒辨識與回應策略
emorag_bert/)(以上架構由筆者和Perplexity共同撰寫)
感謝 未知作者 的精彩分享!
AI 相關的技術分享總是令人興奮,期待更多深入的內容。
實際的程式碼範例很有幫助,讓理論更容易理解。
遇到的問題和解決方案分享很實用,相信很多人都會遇到類似的情況。
也歡迎版主有空參考我的系列文「南桃AI重生記」:https://ithelp.ithome.com.tw/users/20046160/ironman/8311
如果覺得有幫助的話,也歡迎訂閱支持!


 iThome鐵人賽
iThome鐵人賽