我們從眾多資料當中用which的方式僅挑出站名為"關山"的資料並且命名為a
a = data[which(data$STOP_NAME == "關山"),]
因為這資料記錄每一天的進出站狀況,其實是有些過詳盡了,我想要先進行每一個月的預測,因此我用substr(資料,開始,結束)把日期"天數"的部分處理掉。
a$BOARD_DATE = substr(a$BOARD_DATE,1,6)
並且將每一天的資料全部sum起來變成了每一個月的資料。
newdata = (a %>% group_by(BOARD_DATE) %>% summarise(sum(進站)))[,2] %>% unlist()
library(tseries)
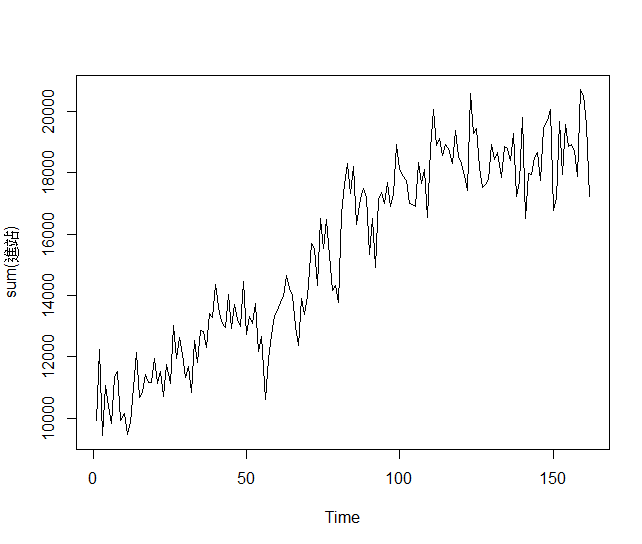
plot.ts(newdata)
#用tsdisplay()可以進行資料的觀測
tsdisplay(newdata)
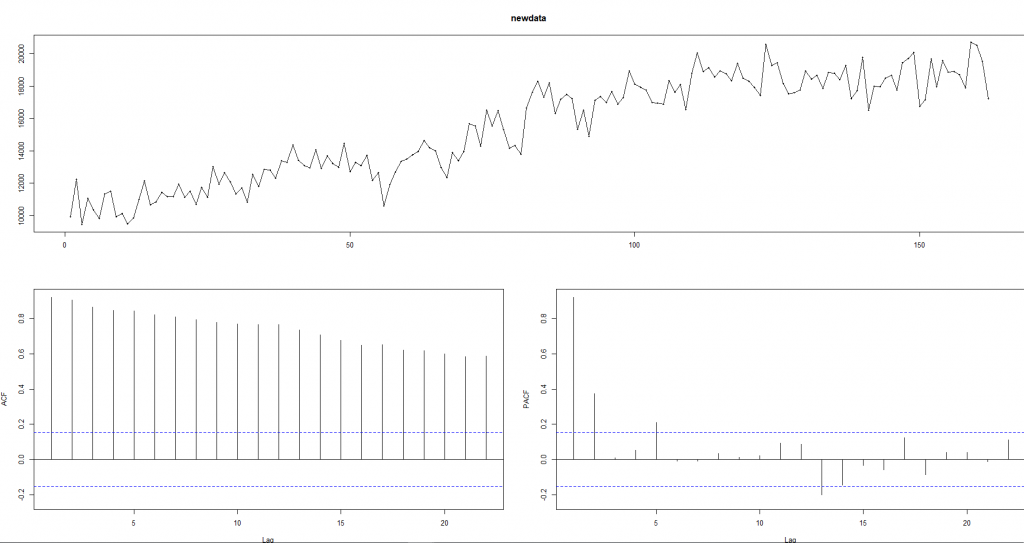
然後我們將資料的最後一年來檢測資料準不準,因此我們看調最後一年的資料。
length(newdata)-12# = 150
newdata_t<-ts(as.vector(newdata[1:150]),frequency=12,start=c(2005,1))
#再看一下訓練資料集的圖形
tsdisplay(newdata_t)
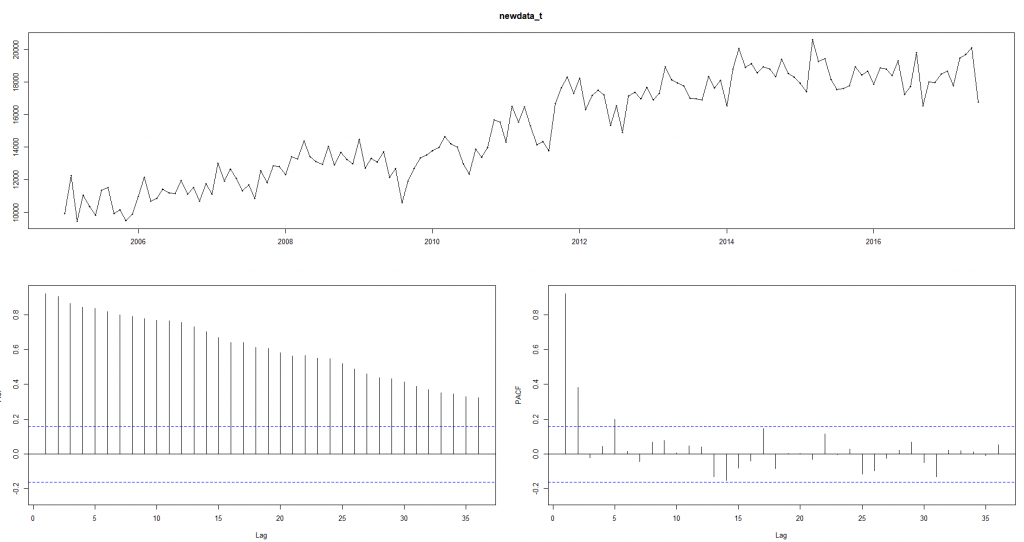
我們發現資料有明顯向上的趨勢,因此我們進行一次分差(減上一個數)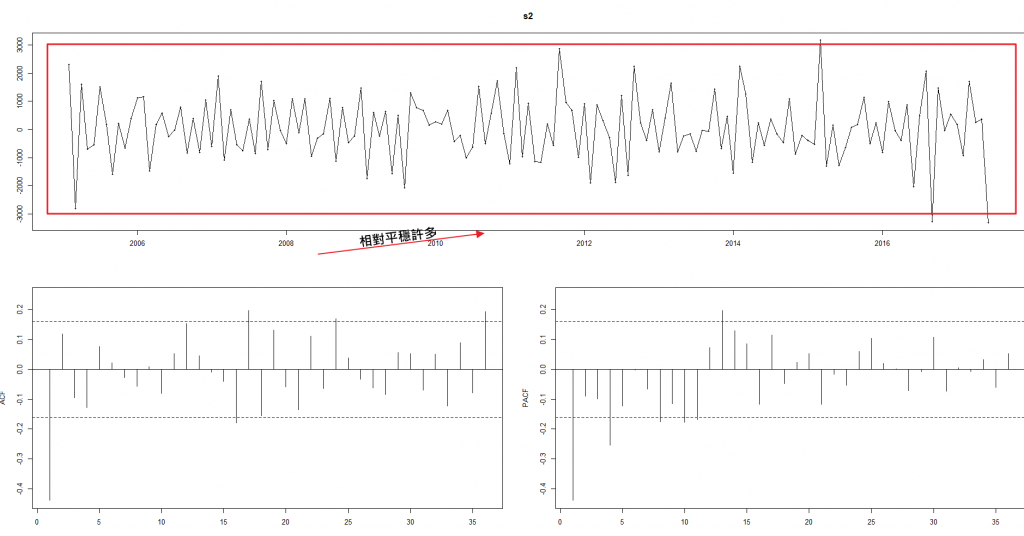
s2<-diff(newdata_t,1)
#看起來都在0附近了,很平穩,有個adf檢定,可以看資料是否平穩(是否存在單位根)
adf.test(s2)
tsdisplay(s2)
#檢驗通過(p < 0.05,顯著拒絕存在單位根),資料穩定之後進行預測會更加準確。
參考出處:https://blog.csdn.net/gdyflxw/article/details/55509656

