
我們繼續 How Google does Machine Learning 的第五章節~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第五章節的課程地圖: (紅字標記為本篇文章中會介紹到的章節)
Cloud Shell
Third wave of cloud
Third Wave of Cloud: Fully-Managed Services
Third Wave of Cloud: Serverless Data Analysis
Third Wave of Cloud: BigQuery and Cloud Datalab
Machine Learning with Sara Robinson
ML, not rules
課程地圖
我們之前所做的事情是建立一個 Compute Engine VM,他幫我們實現了一些功能。
但其實以這樣的需求來說,這樣做是有點浪費的。
現在我們將來介紹 Google Cloud Shell,
想要執行 Cloud Shell 只需要點選 GCP console 右上角的Activate Google Cloud Shell,即可開始執行。
我們所開啟的視窗,稱為 Cloud Shell,他是一種小型的VM,
雖然小,但當我們的目的只是嘗試些小事情(跑幾行code、複製東西...),Cloud Shell絕對夠用。
我們看到Cloud Shell的視窗,基本上我們可以做與Compute Engine VM幾乎相同的事情,
此外,Cloud Shell更適合給developers使用,
在Compute Engine VM中,我們可能還需要安裝一些軟體(因為是全新的環境),
但這些在Cloud Shell幾乎都不用,已經都裝好了。
這邊以git,git clone作為示範,可以看到我們能直接使用。
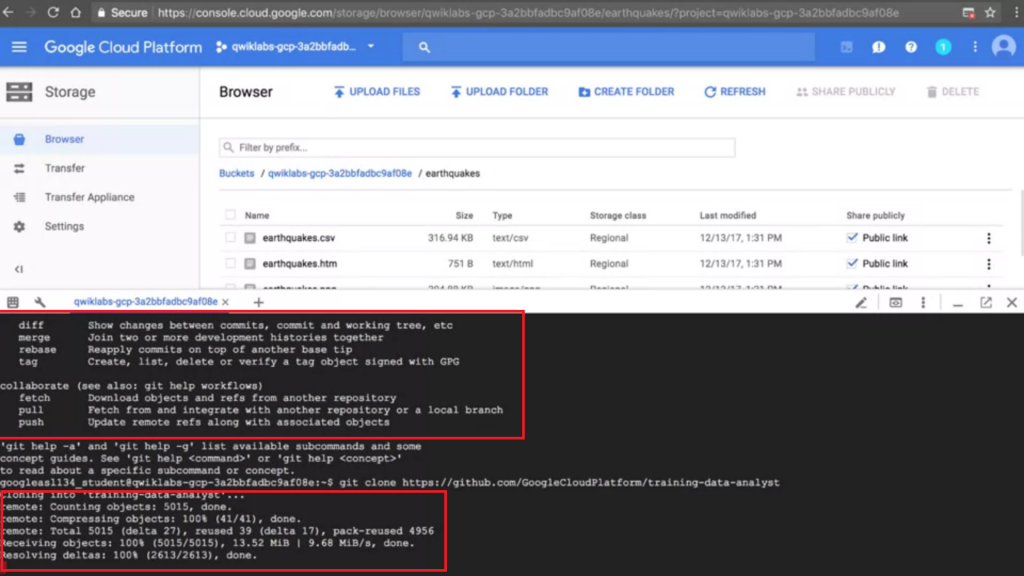
但要注意的事情就是 Cloud Shell 是一個很短暫的 VM,
也就是說大概一陣子(可能大約一小時)沒使用,這VM的內容會被自動回收。
但我們也能隨時重新在啟動新的 Cloud Shell,
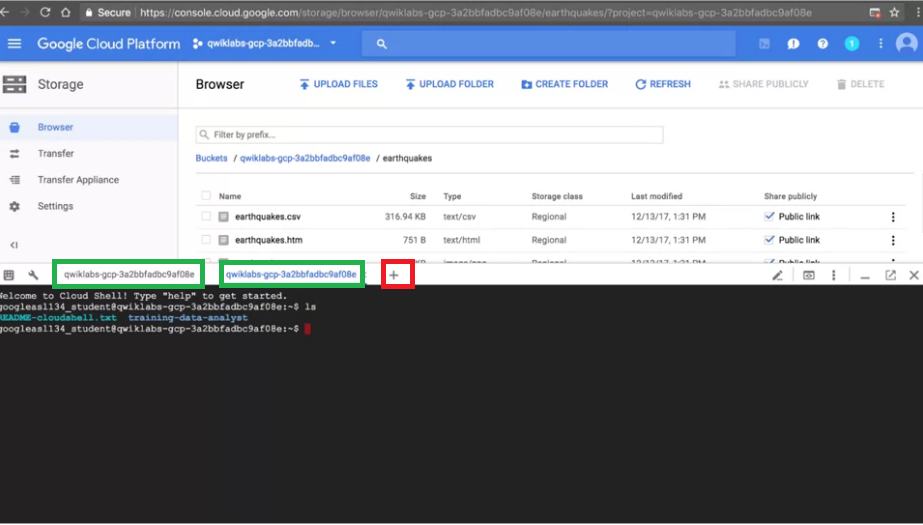
或者我們也可以按新的tab啟動另外一個 Cloud Shell (下圖"+"號),這仍是相同的VM。
當有兩個tab的時候,你可以執行其他指令在另外一個tab,
讓每個 Cloud Shell 所做的事情更清楚。
注意:仍是在同個VM下執行指令。
課程地圖

這邊講一點歷史,三波google雲的變化:
課程地圖
而上面這些內容實際上對應到的是什麼,這邊我們做一個範例,
我們開啟BigQuery console,BigQuery是一個存放data的倉庫。
我們現在想查詢醫療保險索賠的public dataset,我想要查2014年的Medicare索賠。
而我們想做一個ad hoc(臨時的)query查詢,
所以我們也沒有創建indices,也沒有準備database使這查詢更有效率。
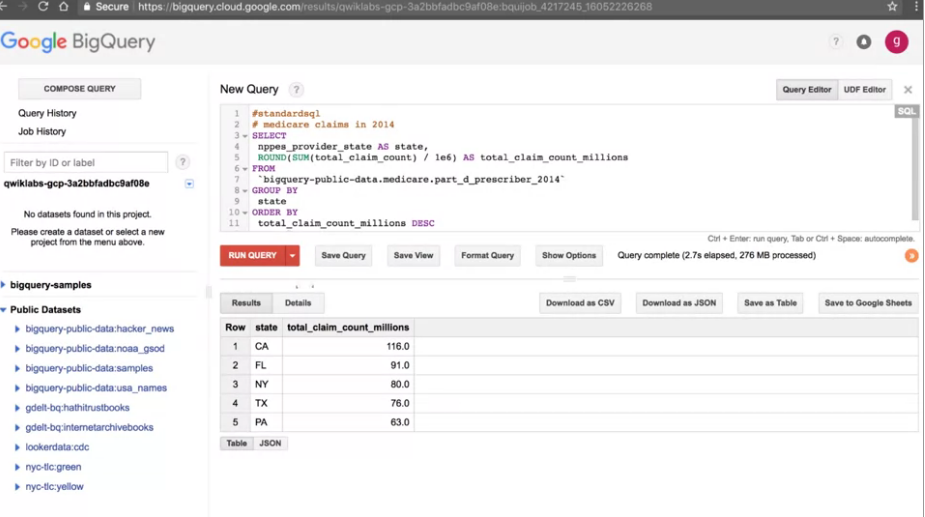
我們只花了3秒左右查詢了276MB的資料,BigQuery是一個columnar database,
我們可以注意一下結果,它們在Medicare的公共數據中。
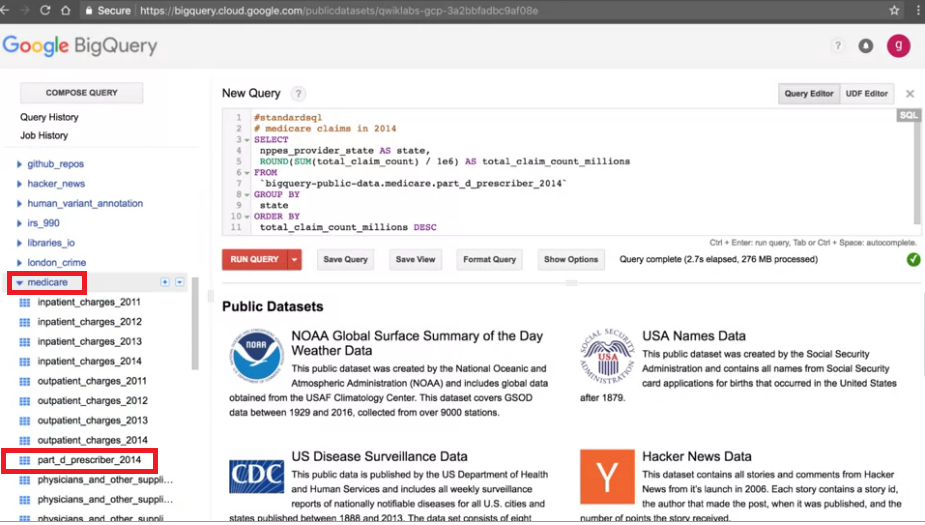
這個數據大約有2400萬行,因此我們能在幾秒鐘對一個大約2400萬行的數據集進行查詢,
而且在不建立任何VM、不安裝任何軟體下完成這樣的查詢操作。
當我們說第三波雲時,就是這件事,我們想做到完全的managed services,
到時我們只需要寫一些code,並交由他執行即可。
課程地圖

在上面的小實驗中,我們看到了BigQuery的一些優點
能快速地進行大量資料的查詢。
我們能使用SQL2011做一個ad-hoc(臨時的)查詢。
而想將資料傳入BigQuery也非常簡單,直接上傳檔案,
或透過web GUI存到雲端中,再將它們的資料流向BigQuery。
另外匯出BigQuery的資料也非常簡單,google有提供非常多的APIs,
運行SQL query並保存成任何你想要的格式結果。
BigQuery資料儲存不貴。
最重要的目的是,因為有了BigQuery,
Datalab可以與BigQuery有良好的整合,
所以我們可以探索數據、運行query,
並將結果以Pandas DataFrame的方式匯出,還能用Python來製圖。
課程地圖
這邊我們要稍微討論一下機器學習比起一般方法更強大的地方,
但要比較,我們就必須要先思考,「如果沒有機器學習,我們要怎麼解一樣的問題?」

你可能會想說,我們只要分辨顏色就好了。 這是正確的方向。
如果我們的程式分辨出大多像素是紅色,就輸出apple;大多像素是橘色,就輸出orange。
但一樣的問題,如果我們今天拿到的是灰階的圖片呢?

這時候我們可能就需要開始尋找表面的紋理或梗的形狀之類的。
但你會發現,我們會因此而要開始改寫我們的演算法,才能夠達到這題目正確的分類結果。
但正當你寫完的時候,如果我們突然想要分辨出三種水果呢?

你到那時才會知道,你整個的算法又會需要再重寫了,
但這些圖片是如此的相似、都是接近一個橢圓形的立體、都是水果,
如果我們的任務改成相差很多的,或許就會變簡單了吧?
這裡就有一個例子,我們來分辨狗與拖把的圖片:

狗有生命且會呼吸,掃把沒眼睛、鼻子、嘴巴,
正當你想這個問題看來能夠輕易地被解決的時候,
突然有人請你分辨sheep dogs(羊狗)與拖把的差別時,你又崩潰了 ,
,
況且這是一個連人由自己的眼睛分辨都很難的題目,

我們就不要再寫code(寫rules)解決這樣的問題了吧,
我們沒有必要特別針對特定的圖片多寫幾行code,只為了能多識別出那個圖像,
而且就算寫出來了,還有可能在別的情況下,這份code又沒有用了。
所以我們應該要改寫能自動幫助我們找到這些規則的code,
這時候我們就需要依靠ML。
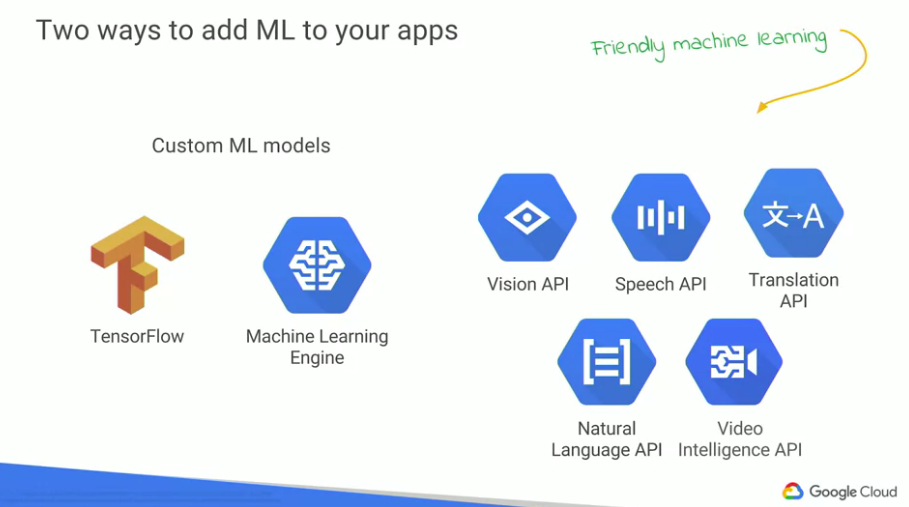
Google Cloud Platform提供了兩種簡單的方式讓ML能加在我們自己的project中,
而且我們可以自己定義ML的功能,如圖的左邊,
Tensorflow: Google Brain團隊提供的open source library,Cloud Machine Learning Engine: Tensorflow模型除了在自己的電腦跑之外,圖的右側指的是一些google已經訓練好的ML所提供的API,
google又稱之為"友善的機器學習",可以透過REST API取得資料,
下個章節中,我們會把所有的API的應用做介紹並且demo每一個功能。
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
