影像分割(Image Segmentation)也稱【語義分割】(Semantic Segmentation),它可以是物件偵測演算法 RCNN 的延伸 -- Mask RCNN,也可以是 Autoencoder 演算法的延伸 -- U-Net,可以用來標示更準確的物體位置,比物件偵測標示的矩形來的準確,因此,它廣泛被應用到醫學、衛星...等方面的影像辨識。詳細的介紹可參閱【Deep Learning for Image Segmentation: U-Net Architecture】、也有中文翻譯 -- 【圖像分割中的深度學習:U-Net 體系結構】。
U-Net 是 Autoencoder 的一種變形(Variant),因為它的模型結構類似U型而得名。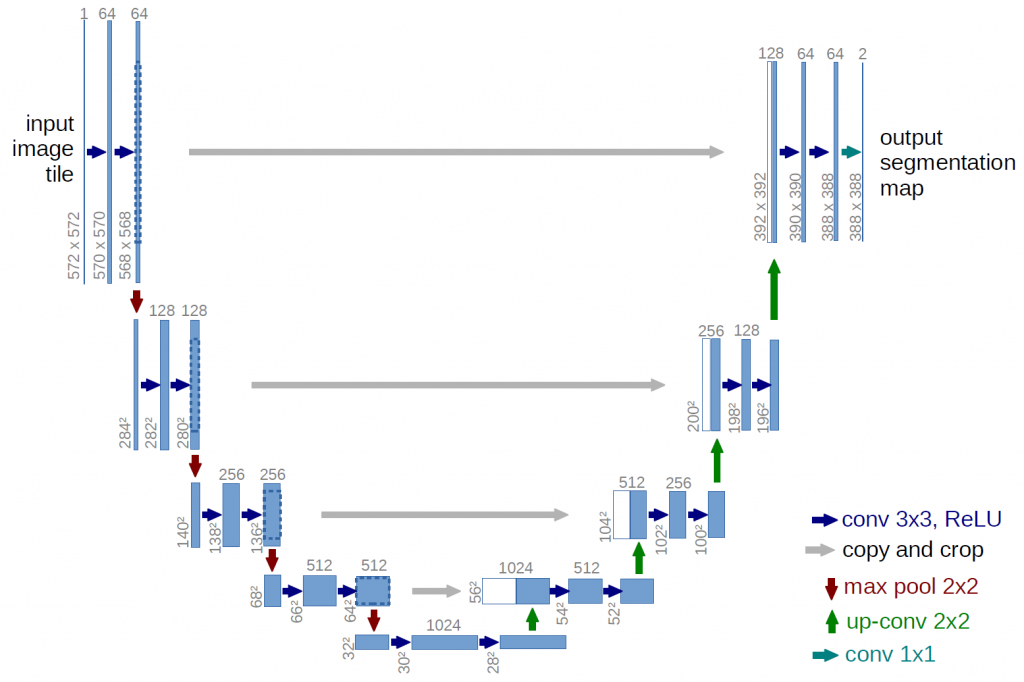
圖一. U-Net 結構,圖片來源:【Deep Learning for Image Segmentation: U-Net Architecture】
傳統的 Autoencoder 的缺點是前半段的編碼器(Encoder),它萃取特徵的過程,使輸出的尺寸(Size)越變越小,之後,解碼器(Decoder) 再由這些變小的特徵,重建成與原圖一樣大小的新圖像,原圖很多的資訊,如前文談的雜訊,就沒辦法傳遞到解碼器了。這在去除雜訊的應用是很恰當的,但是,如果我們目標是要偵測異常點時(如黃斑部病變),那就糟了,經過模型過濾,異常點通通都不見了。
所以,U-Net 在原有的編碼器與解碼器的聯繫上,增加了一些連結,每一段的編碼器的輸出都與對面的解碼器連接,使編碼器每一層的資訊,額外輸入到一樣大小的解碼器的對應層,如圖一的灰色長箭頭,這樣在重建的過程就比較不會遺失重要資訊了。
接下來,我們就來實作 U-Net。
我們就作一個實驗,準備訓練資料時,必須使用標注工具,例如 Labelimg,把圖片內的物件框起來,存成【註解】(Aannotations)檔案為XML格式,參見圖三。
圖二. 原圖
圖三. 標注結果
import os
# 原圖目錄位置
input_dir = "./ImageSegmentData/images/"
# 目標圖遮罩(Mask)的目錄位置
target_dir = "./ImageSegmentData/annotations/trimaps/"
# 超參數
img_size = (160, 160)
num_classes = 4
batch_size = 32
# 取得原圖檔案路徑
input_img_paths = sorted(
[
os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
]
)
# 取得目標圖遮罩的檔案路徑
target_img_paths = sorted(
[
os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")
]
)
print("樣本數:", len(input_img_paths))
for input_path, target_path in zip(input_img_paths[:10], target_img_paths[:10]):
print(input_path, "|", target_path)
from IPython.display import Image, display
from tensorflow.keras.preprocessing.image import load_img
import PIL
from PIL import ImageOps
# 顯示第10張圖
print(input_img_paths[9])
display(Image(filename=input_img_paths[9]))
# 調整對比,將最深的顏色當作黑色(0),最淺的顏色當作白色(255)
print(target_img_paths[9])
img = PIL.ImageOps.autocontrast(load_img(target_img_paths[9]))
display(img)

圖四. 原圖

圖五. 目標圖遮罩(即標注)
from tensorflow import keras
import numpy as np
from tensorflow.keras.preprocessing.image import load_img
class OxfordPets(keras.utils.Sequence):
"""Helper to iterate over the data (as Numpy arrays)."""
def __init__(self, batch_size, img_size, input_img_paths, target_img_paths):
self.batch_size = batch_size
self.img_size = img_size
self.input_img_paths = input_img_paths
self.target_img_paths = target_img_paths
def __len__(self):
return len(self.target_img_paths) // self.batch_size
def __getitem__(self, idx):
"""Returns tuple (input, target) correspond to batch #idx."""
i = idx * self.batch_size
batch_input_img_paths = self.input_img_paths[i : i + self.batch_size]
batch_target_img_paths = self.target_img_paths[i : i + self.batch_size]
x = np.zeros((batch_size,) + self.img_size + (3,), dtype="float32")
for j, path in enumerate(batch_input_img_paths):
img = load_img(path, target_size=self.img_size)
x[j] = img
y = np.zeros((batch_size,) + self.img_size + (1,), dtype="uint8")
for j, path in enumerate(batch_target_img_paths):
img = load_img(path, target_size=self.img_size, color_mode="grayscale")
y[j] = np.expand_dims(img, 2)
return x, y
from tensorflow.keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape=img_size + (3,))
### [First half of the network: downsampling inputs] ###
# Entry block
x = layers.Conv2D(32, 3, strides=2, padding="same")(inputs)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
# Blocks 1, 2, 3 are identical apart from the feature depth.
for filters in [64, 128, 256]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(filters, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(filters, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(filters, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
### [Second half of the network: upsampling inputs] ###
for filters in [256, 128, 64, 32]:
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2DTranspose(filters, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.UpSampling2D(2)(x)
# Project residual
residual = layers.UpSampling2D(2)(previous_block_activation)
residual = layers.Conv2D(filters, 1, padding="same")(residual)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
# Add a per-pixel classification layer
outputs = layers.Conv2D(num_classes, 3, activation="softmax", padding="same")(x)
# Define the model
model = keras.Model(inputs, outputs)
return model
# Free up RAM in case the model definition cells were run multiple times
keras.backend.clear_session()
# Build model
model = get_model(img_size, num_classes)
model.summary()
import tensorflow as tf
tf.keras.utils.plot_model(model, to_file='model.png')
圖六. 模型結構的部份結構
import random
# Split our img paths into a training and a validation set
val_samples = 1000
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_img_paths)
train_input_img_paths = input_img_paths[:-val_samples]
train_target_img_paths = target_img_paths[:-val_samples]
val_input_img_paths = input_img_paths[-val_samples:]
val_target_img_paths = target_img_paths[-val_samples:]
# Instantiate data Sequences for each split
train_gen = OxfordPets(
batch_size, img_size, train_input_img_paths, train_target_img_paths
)
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
# 設定優化器(optimizer)、損失函數(loss)、效能衡量指標(metrics)的類別
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
# 設定檢查點 callbacks,模型存檔
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.h5", save_best_only=True)
]
# 訓練 15 週期(epoch)
epochs = 15
model.fit(train_gen, epochs=epochs, validation_data=val_gen, callbacks=callbacks)
# 預測所有驗證資料
val_gen = OxfordPets(batch_size, img_size, val_input_img_paths, val_target_img_paths)
val_preds = model.predict(val_gen)
# 顯示遮罩(mask)
def display_mask(i):
"""Quick utility to display a model's prediction."""
mask = np.argmax(val_preds[i], axis=-1)
mask = np.expand_dims(mask, axis=-1)
img = PIL.ImageOps.autocontrast(keras.preprocessing.image.array_to_img(mask))
display(img)
# 顯示驗證資料第11個圖檔
i = 10
# 顯示原圖
print('原圖')
display(Image(filename=val_input_img_paths[i]))
# 顯示原圖遮罩(mask)
print('原圖遮罩')
img = PIL.ImageOps.autocontrast(load_img(val_target_img_paths[i]))
display(img)
# 顯示預測結果
print('結果')
display_mask(i) # Note that the model only sees inputs at 150x150.

圖七. 原圖

圖八. 原圖遮罩

圖九. 結果
AIGO 曾經出個題目,希望利用AI演算法進行去背的功能,如應用此類演算法應該是很難吧 !!
本篇範例包括 20_01_Image_segmentation.ipynb,可自【這裡】下載。
您好 非常感謝教學
我有一點不懂在於
為什麼 num_classes = 4
因為訓練輸入資料的Y為 (160, 160, 1)
但是輸出 卻是 (160, 160, 4)
有點不太明白這樣的用意是什麼
感謝大神解答~
好問題,一般Filter都是設成4的倍數,作者利用display_mask函數取最大值,判斷遮罩每一個像素是黑或白。也有人直接設為1,可參閱:
https://towardsdatascience.com/understanding-semantic-segmentation-with-unet-6be4f42d4b47
感謝解答 我明白了 是由於最後一層是Conv2D的緣故,所以num_classes就跟我平常以為的分類種類的意義就不太一樣了,感謝

不好意思打擾了,我是個新手,想請問大大一個問題,就是要如何顯示 accuracy (完整),因為將 accuracy 輸出時會等於 3.1988e-07 成小數點的狀態,自己嘗試了一下還是無法變成像一般常見的 0.5,0.7 等等的數值這樣,希望可以求解,謝謝你。
一般 RCNN 的效能衡量指標採用 mAP,不僅比較物件類別,也比較邊框或遮罩的涵蓋比例,相關資料可參照 Evaluating performance of an object detection model。
謝謝你,我再研究一下
您好,感謝您的好文章,受益匪淺!
有個小問題想跟您請教
在您實作的U-net裡面是否沒有包含[圖一. U-Net 結構]裏面橫跨U型中間的灰色長箭頭呢?
我跟著您的code畫出來的net看不出有橫跨down sampling和up sampling之間的連接
還是說是我哪邊沒搞清楚
希望您可以解惑,謝謝
可看 model.summary(),或
residual = layers.UpSampling2D(2)(previous_block_activation)
residual = layers.Conv2D(filters, 1, padding="same")(residual)
x = layers.add([x, residual]) # Add back residual
previous_block_activation 是上半部的神經層。
了解,感謝您的回覆,我再研究看看
感覺你的residual有錯,由於你每層down sample與up sample都會re-assign新的previous_block_activation,所以你的架構只有down sample層與層之間的skip connect、以及up sample層與層之間的skip connect,而非down sample層到up sample層的skip connect。
Model Architecture建議參考high-star的github。

