遺失值(Missing Value)資料的插補也是訓練模型前資料清洗重要的一環,在進行資料分析時資料常常是不完善的,因此需要有一些方法來處理資料遺失的狀況。不過,遺失值的插補是一門很大的學問,根據不同的成因可以分成常見的兩種類型,例如完全隨機遺失(missing completely at random, MCAR)與非隨機遺失(missing not at random, MNAR),而這兩種類型的處理方式不太一樣,非隨機遺失的情況或許需要研究者深入探究原因找出問題,也需要比較艱深的模型插補方法,在今天的內容會提到幾種完全隨機遺失常見的處理方式。
| 函數名稱 | 說明 |
|---|---|
isnull() |
檢查遺失值傳回布林值 |
notnull() |
與isnull()相反的操作 |
dropna() |
將有遺失值的資料移除 |
fillna() |
傳回含有被插補後的資料 |
isnull()偵測遺失值import pandas as pd
data = pd.DataFrame([[1, np.nan, 2],
[2, 3, 5],
[np.nan, 4, 6]])
data
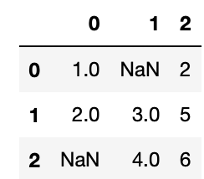
data.isnull()
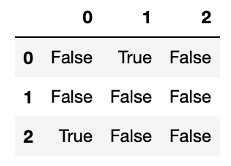
data.isnull().values #返回Dataframe的Numpy形式
data.isnull().values.any() #若有任何元素為True則回傳True,可檢查是否有遺失值
drop()去除遺失值data.dropna() #預設會移除任何有遺失值的列
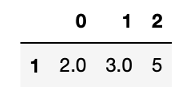
data.dropna(axis = "columns") #移除所有存在遺失值的欄位

data[3] = np.nan #新增一個欄位示範下面的指令
data
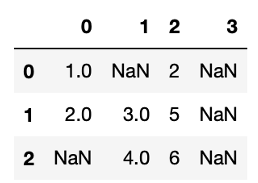
data.dropna(axis = "columns", how = "all") #how="all"使都是遺失值的欄位或列才會被丟掉
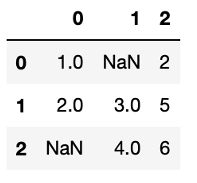
data.dropna(axis = "rows", thresh = 3) #至少有三筆非遺失值的列才會被保留

fillna()填入遺失值data.fillna(0) #將0指定到遺失值的位置
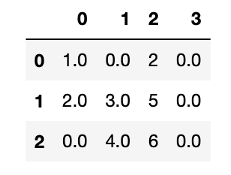
常見完全隨機遺失的遺失值插補方法有以下幾種:
在資料夠多時可以使用第一種方式將遺失值整筆移除,要注意是在完全隨機遺失的假設下,若為非隨機遺失這樣的做法可能會使資料失去大量的資訊。另外,最常見的方法就是利用平均值或中位數來插補(類別型資料則利用眾數),今天主要會介紹此方法,這種方法最為方便,缺點是可能會改變資料的分佈。
import pandas as pd
housing = pd.read_csv("https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/housing/housing.csv")
housing.isnull().sum()
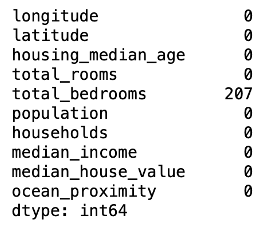
剛好只有連續型變數totoal_bed有207筆的遺失值,我們接著針對此變數進行插補。
fillna()填入median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median, inplace = True)
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy = "median") #可以指定其他插補方式,這裡以中位數為例
housing_num = housing.drop("ocean_proximity", axis = 1) #先將類別的變數欄位去除,否則會有問題
housing_imp = imputer.fit_transform(housing_num) #回array形式
housing_imp = pd.DataFrame(housing_imp, columns = housing_num.columns)
housing_imp.isnull().sum() #檢查是否將遺失值補上了
到今天為止是幾個在開始使用機器學習演算法前常見一些簡單的資料處理方法,未來遇到更複雜的資料時,可能需要更加複雜的處理方式,這幾天的內容我們只能提到一些基本的方法,從明天開始就會進入到系列文章的主軸,開始機器學習常見的主題!
https://www.kaggle.com/datasets/camnugent/california-housing-prices


 iThome鐵人賽
iThome鐵人賽