今日大綱
決策樹有點類似演算法Divide and conquer,將一個問題分割成數個小問題,依照規則對資料進行遞迴分割。隨著深度不斷的增加,資料雜亂的程度就會越低。如果分割後的資料的標籤幾乎都相同,代表不純度較低;反之,如果資料的標籤都不太一樣,那不純度較高。
決策樹與SVM一樣可以用於迴歸問題與分類問題,有三個常見的模型ID3、C4.5與CART。ID3 是最原始的決策樹,利用資訊增益產生決策樹,而C4.5是ID3的改版,使用資訊增益率決定,最後CART則是使用基尼不純度決定模型。

使用某個特徵A劃分資料集D,計算劃分後資料子集的熵為 H(D|A)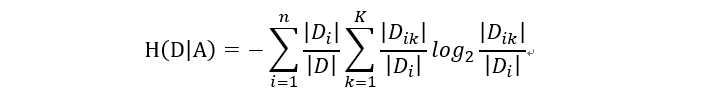
資訊增益 (Information gain)為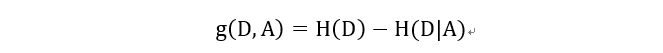
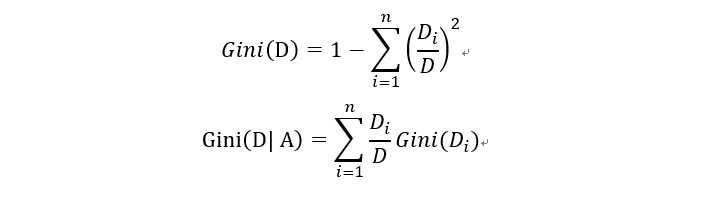
下圖為範例,獨立變數為天氣與距離,目標變數為要不要去上課。依照天氣與距離決定是否要去上課。
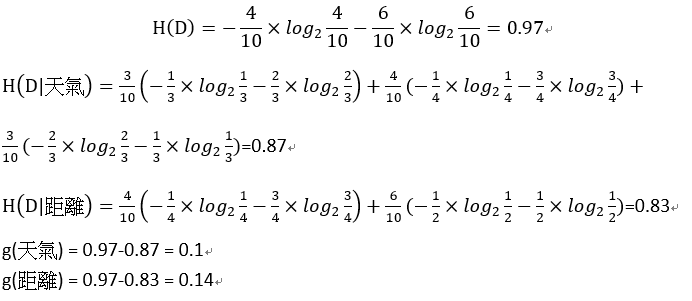
距離所得的資訊增益較大,因此選擇距離當第一個切點
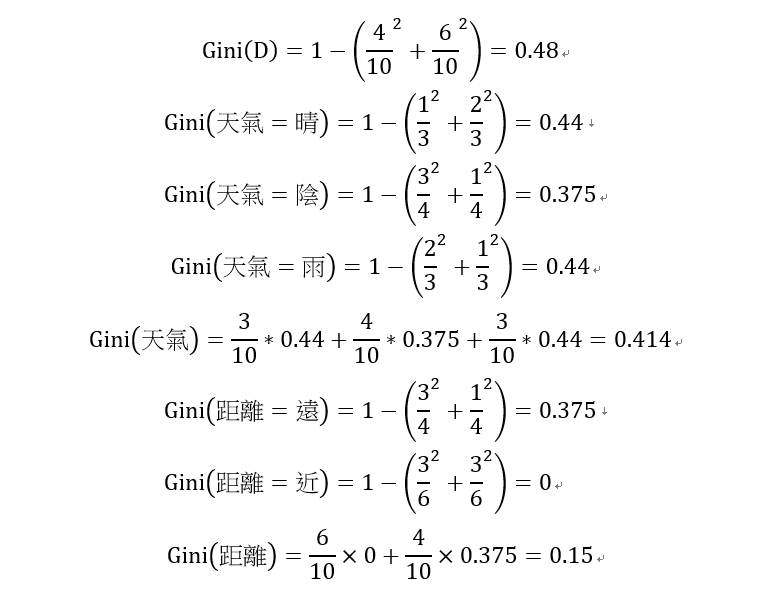
距離所得到的GINI係數較小,因此選擇距離當作第一個切點
感謝您的瀏覽,我們明天見!

