昨天 (Day 6) 我們第一次跑出 Minimal RAG QA Bot,流程是:
使用者提問 → Embedding → 檢索 → LLM 回答。
但那個版本只能使用命令列 (Command Line) 印出結果,使用體驗不直觀。
今天,我們要把它包裝成一個簡單的 Web API + 前端頁面,讓非工程背景的朋友也能透過網頁問問題 👌。
完整可執行專案 已經放在 GitHub。
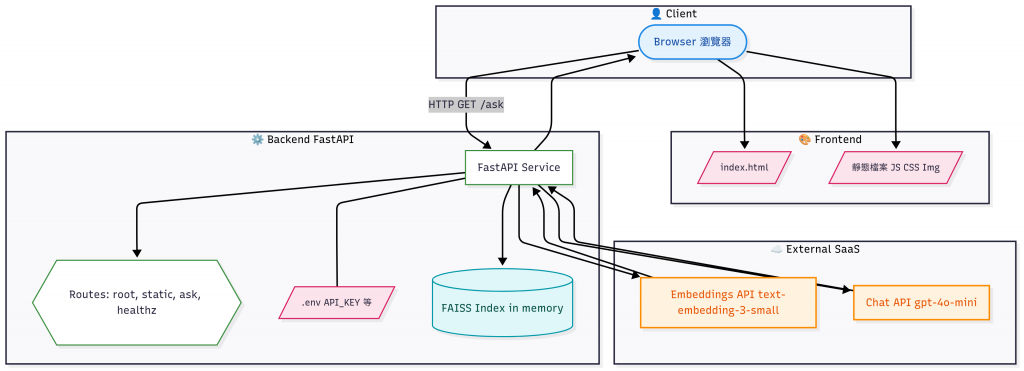
我們擴充知識庫,模擬企業內部 FAQ:
# backend/main.py
from fastapi import FastAPI, Query
from fastapi.middleware.cors import CORSMiddleware
from fastapi.staticfiles import StaticFiles
from fastapi.responses import FileResponse, JSONResponse, RedirectResponse
from openai import OpenAI
from dotenv import load_dotenv
import numpy as np
import faiss
from pathlib import Path
import os, time, traceback
app = FastAPI(title="Day07 RAG QA Demo")
load_dotenv()
# 讀取 .env 檔案裡面的環境變數
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("沒有找到 OPEN_API_KEY,請檢查環境變數!")
# ------- 基本設定 -------
# 避免請求卡住:設定 OpenAI 逾時與不重試
OPENAI_TIMEOUT = float(os.getenv("OPENAI_TIMEOUT", "20"))
client = OpenAI(timeout=OPENAI_TIMEOUT, max_retries=0)
# CORS(local開發先放寬;上線要改白名單)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# ------- 前端頁面顯示 -------
# <repo>/
# backend/main.py
# frontend/index.html
BACKEND_DIR = Path(__file__).resolve().parent
FRONTEND_DIR = BACKEND_DIR.parent / "frontend"
# 讓根路徑直接回傳前端頁面
@app.get("/")
def root():
index_file = FRONTEND_DIR / "index.html"
if index_file.exists():
return FileResponse(index_file)
return JSONResponse({"error": "frontend/index.html not found"}, status_code=404)
# 之後要放 js/css 圖片可用 /_static
app.mount("/_static", StaticFiles(directory=FRONTEND_DIR, html=True), name="frontend")
# healthcheck
@app.get("/healthz")
def healthz():
return {"ok": True}
# ------- 模擬知識庫與索引(這邊可以自行擴充) -------
docs = [
"請假流程:需要先主管簽核,然後到 HR 系統提交。",
"加班申請:需事先提出,加班工時可折換補休。",
"報銷規則:需要提供發票,金額超過 1000 需經理簽核。",
"出差申請:需填寫出差單,並附上行程與預算,送交主管審核。",
"電腦設備申請:新進員工需向 IT 部門提出申請,並由主管批准。",
"VPN 使用:連接公司內網必須使用公司發放的 VPN 帳號。",
"考勤規則:遲到超過 15 分鐘需填寫說明單。",
"文件管理:重要檔案需存放於公司雲端硬碟,不可存個人電腦。",
"安全規範:不得將公司機密資料外傳或存放於私人雲端。",
"年度健檢:每位員工需於 9 月前完成公司指定醫院的健康檢查。"
]
def get_embedding(text: str):
return client.embeddings.create(
model="text-embedding-3-small", input=text
).data[0].embedding
# L2 距離索引
d = 1536
index = faiss.IndexFlatL2(d)
doc_embeddings = [get_embedding(doc) for doc in docs]
index.add(np.array(doc_embeddings).astype("float32"))
# 推薦把門檻放寬,避免常常判定沒有(1.5 ~ 2.0 都可以)
L2_THRESHOLD = float(os.getenv("L2_THRESHOLD", "1.8"))
@app.get("/ask")
def ask(q: str = Query(..., description="你的問題")):
start = time.time()
try:
print(f"[ask] q={q}")
q_emb = np.array([get_embedding(q)]).astype("float32")
D, I = index.search(q_emb, k=3) # 取三筆較穩
best_idx = int(I[0][0])
best_dist = float(D[0][0])
if best_dist > L2_THRESHOLD:
context = "知識庫裡沒有相關答案。"
else:
context = docs[best_idx]
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一個企業 FAQ 助理。"},
{"role": "user", "content": f"根據以下知識庫內容回答:\n{context}\n\n問題:{q}"},
],
temperature=0.2,
)
answer = resp.choices[0].message.content
return {"question": q, "context": context, "answer": answer, "debug": {"l2": best_dist}}
except Exception as e:
traceback.print_exc()
# 回 500,讓前端顯示錯誤並關閉 loading
return JSONResponse(status_code=500, content={"error": str(e)})
finally:
dur = time.time() - start
print(f"[ask] done in {dur:.2f}s")
# 直接 python3 backend/main.py 可啟動
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=True)
| 變數 | 預設 | 作用 | 調整的時機點 |
|---|---|---|---|
OPENAI_TIMEOUT |
20 |
OpenAI 請求逾時(秒) | 一直轉圈或網路不穩時,先調大到 30~60 |
EMBEDDING_MODEL |
text-embedding-3-small |
向量維度/成本 | 要更準可換 -large(成本↑) |
CHAT_MODEL |
gpt-4o-mini |
生成回答模型 | 成本敏感用 -mini;品質要好換 gpt-4o |
TOP_K |
3 |
取回的片段數 | 資料碎片化↑→調大到 5;上下文爆炸→調小 |
L2_THRESHOLD |
1.8 |
L2 距離門檻(越小越相似) | 常說「找不到」→調高到 2.0~2.2 |
COSINE_MODE |
0 |
是否改用 cosine 檢索(1=啟用) |
想更穩就開;搭配 COS_TH 使用 |
COS_TH |
0.35 |
cosine 相似度門檻(越大越嚴) | 命中太鬆→調到 0.4;太嚴→降到 0.3 |
TEMPERATURE |
0.2 |
文本生成活潑度 | 回答太發散→降到 0.0;太死板→升到 0.4 |
HOST / PORT |
127.0.0.1 / 8000 |
服務位址與埠號 | 要外部訪問或反代時調整 |
💡L2 與 cosine 只擇一。若啟用
COSINE_MODE=1,請忽略L2_THRESHOLD、改用COS_TH。
src/index.html 如下,有加入 loading 的動畫,因為呼叫 OpenAI 還是會花一些時間:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>RAG QA Bot Demo</title>
<style>
body { font-family: ui-sans-serif, system-ui; max-width: 720px; margin: 40px auto; }
input { width: 70%; padding: 8px; }
button { padding: 8px 12px; }
pre { background: #f6f6f6; padding: 12px; border-radius: 8px; white-space: pre-wrap; }
.overlay { position: fixed; inset: 0; background: rgba(0,0,0,0.25); display: none; align-items: center; justify-content: center; z-index: 9999; }
.overlay.show { display: flex; }
.spinner { width: 48px; height: 48px; border: 5px solid #fff; border-top-color: transparent; border-radius: 50%; animation: spin 1s linear infinite; }
@keyframes spin { to { transform: rotate(360deg); } }
.muted { opacity: 0.6; pointer-events: none; }
</style>
</head>
<body>
<h2>RAG QA Bot Demo</h2>
<input type="text" id="question" placeholder="輸入你的問題">
<button id="askBtn">提問</button>
<pre id="answer"></pre>
<div id="loading" class="overlay"><div class="spinner" aria-label="Loading"></div></div>
<script>
document.addEventListener("DOMContentLoaded", () => {
const input = document.getElementById("question");
const btn = document.getElementById("askBtn");
const out = document.getElementById("answer");
const loading = document.getElementById("loading");
// 若前端是由 FastAPI 服務(同源),可用 origin;否則用固定位址
const API_BASE = window.location.origin || "http://127.0.0.1:8000";
function showLoading(on) {
loading.classList.toggle("show", on);
input.disabled = on;
input.classList.toggle("muted", on);
btn.disabled = on;
btn.classList.toggle("muted", on);
}
async function ask() {
const q = input.value.trim();
if (!q) return;
showLoading(true);
out.textContent = "";
try {
const res = await fetch(`${API_BASE}/ask?q=${encodeURIComponent(q)}`);
if (!res.ok) throw new Error(`HTTP ${res.status}`);
const data = await res.json();
out.textContent =
`📌 問題: ${data.question}\n\n` +
`📚 參考文件: ${data.context}\n\n` +
`🤖 答案: ${data.answer}`;
} catch (err) {
out.textContent = `⚠️ 請求失敗:${err}`;
} finally {
showLoading(false);
}
}
btn.addEventListener("click", ask);
input.addEventListener("keydown", (e) => { if (e.key === "Enter") ask(); });
});
</script>
</body>
</html>
安裝環境,並且啟動主程式:
conda create -n rag-demo python=3.10 -y
conda activate rag-demo
pip install -r requirements.txt
python backend/main.py
在瀏覽器輸入 http://localhost:8000/ 或是 http://127.0.0.1:8000/ 會出現如下畫面:
啟動 FastAPI 後可以問以下問題:
- 我要怎麼報銷?
- VPN 怎麼用?
- 遲到會怎樣?
- 什麼時候要去健檢?
- 公司午餐補助多少?
輸出結果 (部分示例):
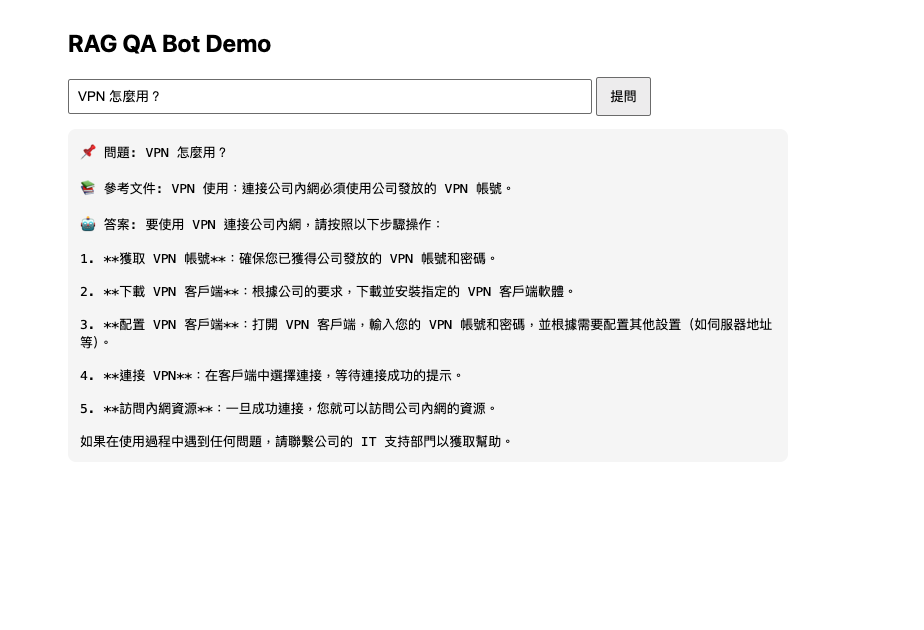
Demo 1:
📌 問題: 我要怎麼報銷?
📚 參考文件: 報銷規則:需要提供發票,金額超過 1000 需經理簽核。
🤖 答案: 要報銷,您需要遵循以下步驟:
1. 準備相關的發票。
2. 如果報銷金額超過 1000 元,請確保獲得經理的簽核。
3. 提交報銷申請,附上發票和經理簽核(如適用)。
請確保所有文件齊全,以便順利完成報銷流程。
Demo 2:
📌 問題: VPN 怎麼用?
📚 參考文件: VPN 使用:連接公司內網必須使用公司發放的 VPN 帳號。
🤖 答案: 要使用 VPN 連接公司內網,請按照以下步驟操作:
1. **獲取 VPN 帳號**:確保您已獲得公司發放的 VPN 帳號和密碼。
2. **下載 VPN 客戶端**:根據公司的要求,下載並安裝指定的 VPN 客戶端軟體。
3. **配置 VPN 客戶端**:打開 VPN 客戶端,輸入您的 VPN 帳號和密碼,並根據需要配置其他設置(如伺服器地址等)。
4. **連接 VPN**:在客戶端中選擇連接,等待連接成功的提示。
5. **訪問內網資源**:一旦成功連接,您就可以訪問公司內網的資源。
如果在使用過程中遇到任何問題,請聯繫公司的 IT 支持部門以獲取幫助。
Demo 3:
📌 問題: 公司午餐補助多少?
📚 參考文件: 加班申請:需事先提出,加班工時可折換補休。
🤖 答案: 根據提供的知識庫內容,並沒有提到公司午餐補助的具體金額。建議您查閱公司內部的相關政策或聯繫人力資源部門以獲取準確的信息。
如果要用 API 也可以:
❯ curl -G "http://127.0.0.1:8000/ask" --data-urlencode "q=我要怎麼報銷?"
{"question":"我要怎麼報銷?","context":"報銷規則:需要提供發票,金額超過 1000 需經理簽核。","answer":"要報銷,您需要按照以下步驟進行:\n\n1. 準備發票:確保您有相關的發票作為報銷的依據。\n2. 金額確認:如果報銷金額超過 1000 元,您需要獲得經理的簽核。\n3. 提交報銷申請:將發票和必要的簽核文件提交給財務部門或相關負責人。\n\n請確保所有文件齊全,以便順利完成報銷流程。","debug":{"l2":1.1838947534561157}}%
今天我們完成了一個 最小可行的 Web QA Bot,做的事情很單純:
Embedding 模型 ,並且詢問 LLM,把答案丟回來 HTML 頁面/ask 端點可以透過命令列問問題今天的 Bot 還很簡單,使用「整篇文件」在比對,所以顆粒度很粗。顆粒度太粗的話,回答問題會相對不精準,但顆粒度太細的話,有可能會缺乏關鍵的前後文。
接下來,我們要處理一個實際問題:
❓ 文件通常很長,要怎麼切片 (Chunking) 才能讓檢索更精準?
這個問題,會留到明天的 Chunking 來處理:把長文件切成適合檢索的小段,命中率會明顯提升、答案也會更貼近問題。


 iThome鐵人賽
iThome鐵人賽