今天是鐵人的第20天,在進入金融數據分析之前要先學習統計分析(Statistical Analysis),統計分析是以數據為基礎,對數據進行科學處理、分析。統計分析包括兩大部分
在學習描述統計之前,先進行數據分類。
當拿到數據後拿來分析,最常使用圖表的方式呈現數據。有以下圖表可以呈現數據。
分析數據時,想要了解數據分布的位置,在統計分析中有專門的指標用於描述數據的位置。常用的指標有以下四種方式:
假設現在有n個樣本觀測值(X1,X2,.....Xn),在統計學中樣本平均數有兩種計算方式:
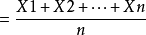
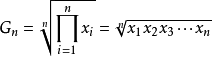
示範建立一個陣列
import numpy as np
x = np.random.randint(0,100,size = 20)
print('x----------->',x)
print('np.sort(x)----------->',np.sort(x))
# 輸出結果
x-----------> [38 60 17 34 13 8 34 35 21 49 61 48 93 12 63 29 80 86 61 60]
x.sort()-----------> [ 8 12 13 17 21 29 34 34 35 38 48 49 60 60 61 61 63 80 86 93]
顯示x的平均值
print('x.mean()----->',x.mean())
# 輸出結果
x.mean()-----> 45.1
將樣本從小到大做排序,如果樣本是奇數個中位數即為最中間的值,如果是偶數個,中位數是中間兩個數值的平均。
print('np.median(x)----->',np.median(x))
# 輸出結果
np.median(x)-----> 43.0
# 可以看到x的中間兩個位數為38, 48 中位數為(38+48)/2 = 43
樣本中出現次數最多的數值。
from scipy import stats
print('stats.mode(x)----->',stats.mode(x).mode[0])
# 輸出結果
stats.mode(x)-----> 34
# 可以看到x陣列中出現最多的數字為34
假設現在有n個樣本觀測值(X1,X2,.....Xn),第α百分位數: n*α%
統計學中經常將25百分位數、中位數和75百分位數組成四分位數(Quartile)。25百分位數叫做第一四分位數(下四分位數)、中位數為第二四分位數、75百分位數為第三四分位數(上四分位數)。
print('np.percentile(x, 25)----->',np.percentile(x, 25))
print('np.percentile(x, 75)----->',np.percentile(x, 75))
# 輸出結果
np.percentile(x, 25)-----> 27.0
np.percentile(x, 75)-----> 61.0
# 0.25*21 + 0.75*29 = 27
# 0.25*61 + 0.75*61 = 61
要分析數據除了需要數據的位置,還需要反應數據分佈的特徵也稱為數據的變異性,常用的離散度指標有
指的是數據中的最大值和最小值,公式為:
全距 = 最大值 - 最小值
示範建立一個陣列
import pandas as pd
ironman = pd.Series([60,70,80,80,90,100])
print('ironman.mean()----->',ironman.mean())
# 輸出結果
ironman.mean()-----> 80.0
ironman的全距就是 100 - 60 = 40
採用的方式是用樣本與平均值(Mean)的差值來計算,當差值越大則表示數據值偏離均值越遠。這邊需要注意到的是平均偏差(Mean Deviation)的相加為0,所以需要加上絕對值來運算。公式如下: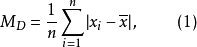
ironman的平均絕對偏差
print('ironman.mad()----->',ironman.mad())
# 輸出結果
ironman.mad()-----> 10.0
# |(60-80)| + |(70-80)| + (80-80) + (80-80) + (70-80) + (100-80) = 60
# MAD = 60 / 6 = 10
變異數也是用來描述數據的離散程度,標準差就是變異數得平方根
變異數公式:
ironman的變異數
print('ironman.var()----->',ironman.var())
# 輸出結果
ironman.var()-----> 200.0
# 20*20 + 10 * 10 + 0*0 + 0*0 + 10 * 10 + 20*20 = 1000
# Variance = 1000 / (6-1) = 200
標準差(σ)公式: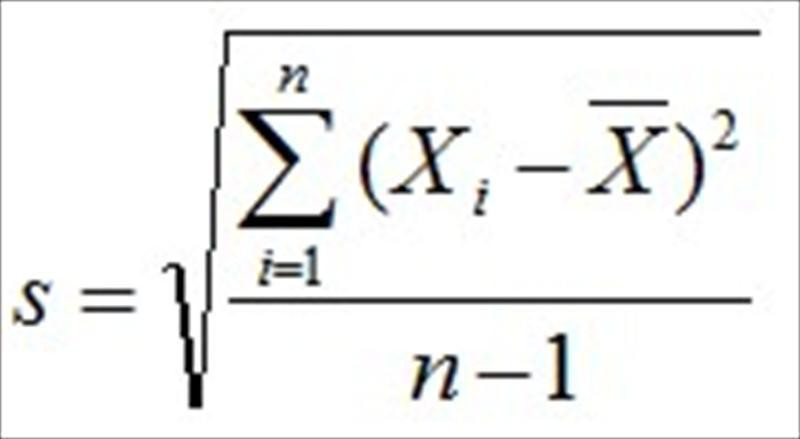
ironman的標準差
print('ironman.std()----->',ironman.std())
# 輸出結果
ironman.std()-----> 14.142135623730951
# 200的平方根
* [安裝Anaconda](https://ithelp.ithome.com.tw/articles/10199666)
* [安裝Jupyter notebook](https://ithelp.ithome.com.tw/articles/10200046)

