之前的有一些案例程式使用 Tensorflow Dataset,但沒有多作解釋,心中有愧,因此,花了一些時間,整理相關用法如下。
Tensorflow Dataset 正式的名稱為 tf.data API,它是一個 Python Generator,可以視需要逐批讀取必要資料,不必一股腦將資料全部讀取放在記憶體,若資料量很大時,記憶體就爆了。另外,它還有快取(Cache)、預取(Prefetch)、篩選(Filter)、轉換(Map)...等功能,值得我們一探究竟。
參考資源主要有兩篇:
程式檔案為22_01_tf.data_basics.ipynb,可自【這裡】下載。
import tensorflow as tf
import pathlib
import os
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
dataset = tf.data.Dataset.from_tensor_slices([8, 3, 0, 8, 2, 1])
for elem in dataset:
print(elem.numpy())
# iterator
it = iter(dataset)
# 一次取一筆
print(next(it).numpy())
print(next(it).numpy())
# 求總和
gfg = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5])
# 0: axis 0
print(gfg.reduce(0, lambda x, y: x + y).numpy())
# Map
gfg = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5])
for elem in gfg.map(lambda x: x * 2):
print(elem.numpy())
# Filter
gfg = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5])
filter = lambda x: x % 2 == 0
for elem in gfg.filter(filter):
print(elem.numpy())
def count(stop):
i = 0
while i<stop:
yield i
i += 1
# args=[25] : 最多從 count 函數取25個
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
# repeat():取完會重頭再開始
# batch(10):一次取 10 個
# take(5):取 5 次
for count_batch in ds_counter.repeat().batch(10).take(5):
print(count_batch.numpy())
def gen_series():
i = 0
while True:
size = np.random.randint(0, 10)
yield i, np.random.normal(size=(size,))
i += 1
for i, series in gen_series():
print(i, ":", str(series))
if i > 5:
break
# 一次取 20 個洗牌,取完,再抽 20 個洗牌
# batch(10):一次取 10 個
# take(5):取 5 次
for count_batch in ds_counter.shuffle(20).batch(10).take(5):
print(count_batch.numpy())
# 下載檔案
flowers = tf.keras.utils.get_file(
'flower_photos',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
untar=True)
# rescale:特徵縮放
# rotation_range:自動增補旋轉20度內的圖片
img_gen = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1./255, rotation_range=20)
images, labels = next(img_gen.flow_from_directory(flowers))
import matplotlib.pyplot as plt
plt.imshow(images[0])
labels[0]
ds = tf.data.Dataset.from_generator(
img_gen.flow_from_directory, args=[flowers],
output_types=(tf.float32, tf.float32),
output_shapes=([32,256,256,3], [32,5])
)
fsns_test_file = tf.keras.utils.get_file("fsns.tfrec", "https://storage.googleapis.com/download.tensorflow.org/data/fsns-20160927/testdata/fsns-00000-of-00001")
dataset = tf.data.TFRecordDataset(filenames = [fsns_test_file])
raw_example = next(iter(dataset))
parsed = tf.train.Example.FromString(raw_example.numpy())
parsed.features.feature['image/text']
)
# 讀取三個檔案directory_url = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'
file_names = ['cowper.txt', 'derby.txt', 'butler.txt']
file_paths = [
tf.keras.utils.get_file(file_name, directory_url + file_name)
for file_name in file_names
]
# 合併多個檔案為一資料集
dataset = tf.data.TextLineDataset(file_paths)
# 讀取5行資料
for line in dataset.take(5):
print(line.numpy())
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
df = pd.read_csv(titanic_file, index_col=None)
df.head()
titanic_slices = tf.data.Dataset.from_tensor_slices(dict(df))
for feature_batch in titanic_slices.take(1):
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
# 選擇部份欄位
titanic_batches = tf.data.experimental.make_csv_dataset(
titanic_file, batch_size=4,
label_name="survived", select_columns=['class', 'fare', 'survived'])
# 顯示欄位值
for feature_batch, label_batch in titanic_batches.take(1):
print("'survived': {}".format(label_batch))
print("features:")
for key, value in feature_batch.items():
print(" {!r:20s}: {}".format(key, value))
相關用法可參考【Better performance with the tf.data API】。
看看效能比較圖。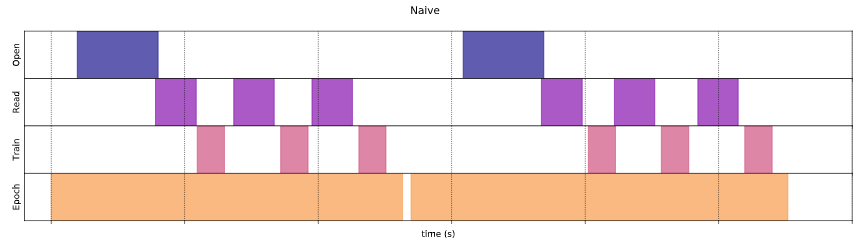
圖一. 不使用 prefetch(),一切循序漸進。
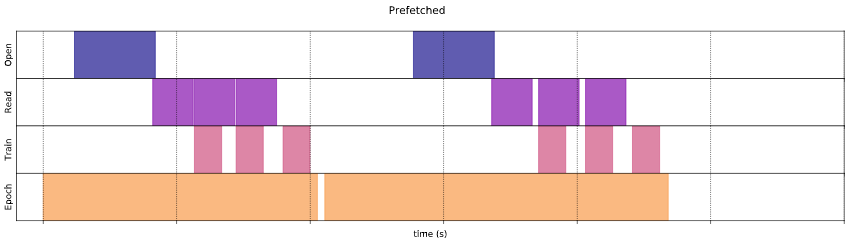
圖二. 使用 prefetch(),訓練與轉換工作重疊。
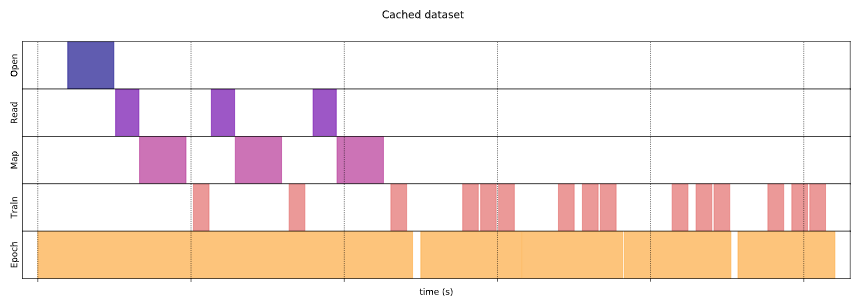
圖二. 使用 cache(),讀取硬碟的時間減少。
我們在實作練習時,常一次載入所有資料,並未發生問題,但是實際執行專案時,就必須考慮效能,Tensorflow Dataset 是一個不錯的模組,不僅可以節省記憶體,也可以提升效能。相關實例應用可以參考【Basic text classification】。
本篇範例包括 22_01_tf.data_basics.ipynb,可自【這裡】下載。
Tensorflow Dataset 可以切訓練、測試、驗證集嗎?
漏寫了,在【實作】第10點,可使用洗牌(shuffle),作隨機抽樣。如果資料源是不同目錄,應該各建一個Dataset,比較方便。
請問老師要怎麼做可以一邊讀取資料一邊訓練模型?有範例可以分享嗎
直接對 dataset 下 prefetch()、cache() 即可,請參考:
https://www.tensorflow.org/datasets?hl=zh-tw
了解我嘗試看看謝謝老師
請教老師在【Basic text classification】中有一段,
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
它這段的意思是pipline的效果嗎?有點看不太懂它是如何運作的,看起來好像是只取一次沒有分批取好幾次再做訓練,因為若要不斷取部分資料做訓練,不是應該要透過一個for或者是類別來取的部分資料嗎?它裡面都沒有特別描述所以有點不太明白,還請老師解答。
這幾行只是定義 dataset 及其屬性而已,並沒有讀取資料。以下才是讀取資料:
# 讀取5行資料
for line in dataset.take(5):
print(line.numpy())
或是 fit() 才會觸動。
老師可以示範一個簡單的take在fit嗎?因為我測試過take的功能,take多少就是一次取多少,可是假如我有100筆資料,我只take 10 ,他就只會用那10比訓練,不會用到其他的資料,請老師賜教
https://ithelp.ithome.com.tw/articles/10235805
model.fit(
train_ds, epochs=epochs, validation_data=val_ds,
)
看完了老師的教學,內部沒有提到關於take的用法,take的用法是不是不能跟model.fit()一起用
take 是手動取資料,fit則是自動會取所需的資料。
哦哦~原來是這樣,那這樣我了解了,謝謝老師的解說

