上一篇我們的基因體時代-AI, Data和生物資訊 Day07- 蛋白質結構和機器學習02:AlphaFold2 和 RoseTTAFold主要分享由DeepMind公司的AlphaFold2和David Baker團隊的RoseTTAFold之簡易架構,兩個基本上都是基於Attention Model來架構,且使用預測蛋白質序列的相關序列矩陣和相關的蛋白質結構資料庫,但AlphaFold2主要是有比較複雜的Model系統,而RoseTTAFold則是使用Domain Knowledge的概念來架構網絡,分成一級結構、二級結構、三級結構分別來學習和預測。
合成生物學(synthetic biology)本質上相對於傳統生物學,更強調主動地去利用生物系統創造新的功能,目前已經是一個非常廣大的領域,有的人專注在模式生物的改質、有的人在創造新的生物材料,且越來越多已經直接影響到人們的食衣住行。
有興趣多了解的人可以看看下面這本書:
其中會牽涉到的事情就是去重組或是修改一段核酸,再放入到生物體中,這生物體可以是細菌、酵母菌、哺乳類細胞、植物,甚至不用是完整的細胞,但目前的問題是這些生物體是一個複雜系統,往往會發生無法預測的結果,所以變成需要大量的測試,這看起來就是一個不錯的機器學習應用的實務場景。
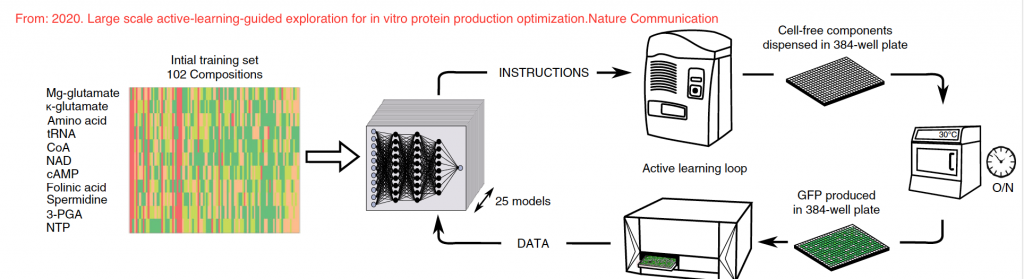
這篇研究就是在分享如何用機器學習來降低需要做的高通量實驗數量,這邊是在測試無細胞蛋白表達系統的各種溶液排列組合,基本上,這個實驗中會有11種成分,分別是Mg-glutamate, K-glutamate, Amino acid, tRNA, CoA, NAD, cAMP, Folinic acid, Spermidine, 3-PGA, NTP,然後希望建立這組合跟螢光蛋白質產量的關係,初始階段先選擇22組想要測試的濃度,接者設定每個成分的最大濃度上限,這邊採用ensemble neural network的架構,但跟其他領域的機器學習用法不同,這邊其實是比較探索性的,他的做法主要來自於這篇論文High-Throughput Optimization Cycle of a Cell-Free Ribosome Assembly and Protein Synthesis System,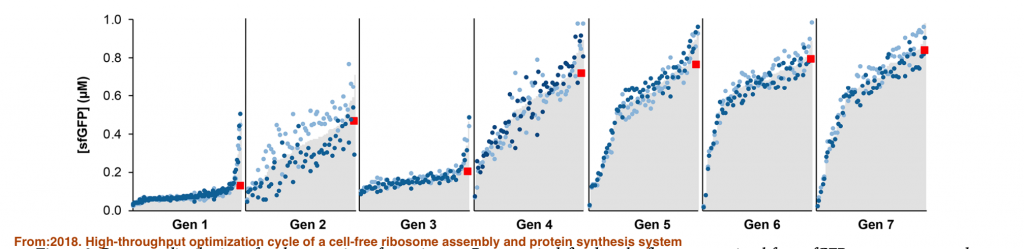
實際上的概念就如這張圖所示,假如有七組迭代的實驗,每一次測試完後的數值和結果,會用來建立模型,接者來預測可能可以提高產量的實驗參數,再往下一回合設計實驗點,結束後再從實際實驗的參數輸入模型再往下進行另一回合,藉這個方法找到能取得最佳輸入的參數組合模型。他所使用的方法為25層的feed-forward neural network,每層網絡初始使用隨機的權重,整個過程使用nnet這個R的函數包,每個網路11個節點,分別代表實驗的參數,和一個輸出結果,就是最後所量測的輸出濃度。就由這樣的方法,最後能將蛋白質的產量增加10倍。在這過程中還發現在傳統認為需要添加的成分,在另外兩個成分高濃度下,其實去掉反而有助於產量的上升。
閱讀參考:
2020. A machine learning Automated Recommendation Tool for synthetic biology. Nature communications
2019. Opportunities at the intersection of Synthetic Biology, Machine Learning, and Automation. ACS Synth. Biol
2019. Adapting machine-learning algorithms to design gene circuits. BMC Bioinformatics
2021. In silico, in vitro, and in vivo machine learning in synthetic biology and metabolic engineering. Curr Opin Chem Biol
2018. High-Throughput Optimization Cycle of a Cell-Free Ribosome Assembly and Protein Synthesis System. ACS Synth Biol. 2018
ProtoLife: https://pdt.protolife.com/pdt_validation
這個月的規劃貼在這篇文章中我們的基因體時代-AI, Data和生物資訊 Overview,也會持續調整!我們的基因體時代是我經營的部落格,如有對於生物資訊、檢驗醫學、資料視覺化、R語言有興趣的話,可以來交流交流!


 iThome鐵人賽
iThome鐵人賽