今天將以Python建立KNN的模型,包含如何選擇一個適當的K值。以iris為例,將屬種(Species)當成反應變數或outcome,共有三類,以KNN嘗試建立預測模型。
urlprefix = 'https://vincentarelbundock.github.io/Rdatasets/csv/'
dataname = 'datasets/iris.csv'
iris = pd.read_csv(urlprefix + dataname)
iris = iris.drop("Unnamed: 0", 1)
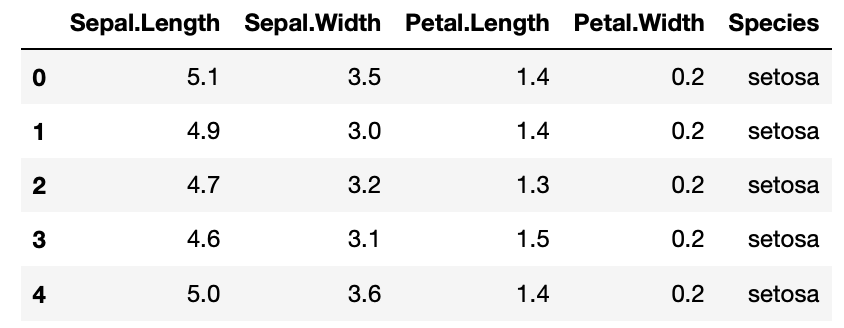
iris.head()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(iris.drop('Species',axis=1))
scaled_features = scaler.transform(iris.drop('Species',axis=1))
iris_feat = pd.DataFrame(scaled_features,columns=iris.columns[:-1])
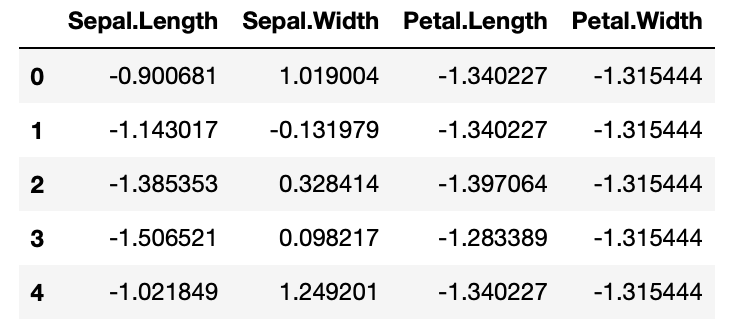
iris_feat.head()
from sklearn.model_selection import train_test_split
X = iris_feat
y = iris['Species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 1)
knn.fit(X_train,y_train)
pred = knn.predict(X_test)
from sklearn.metrics import classification_report,confusion_matrix
print(confusion_matrix(y_test,pred))

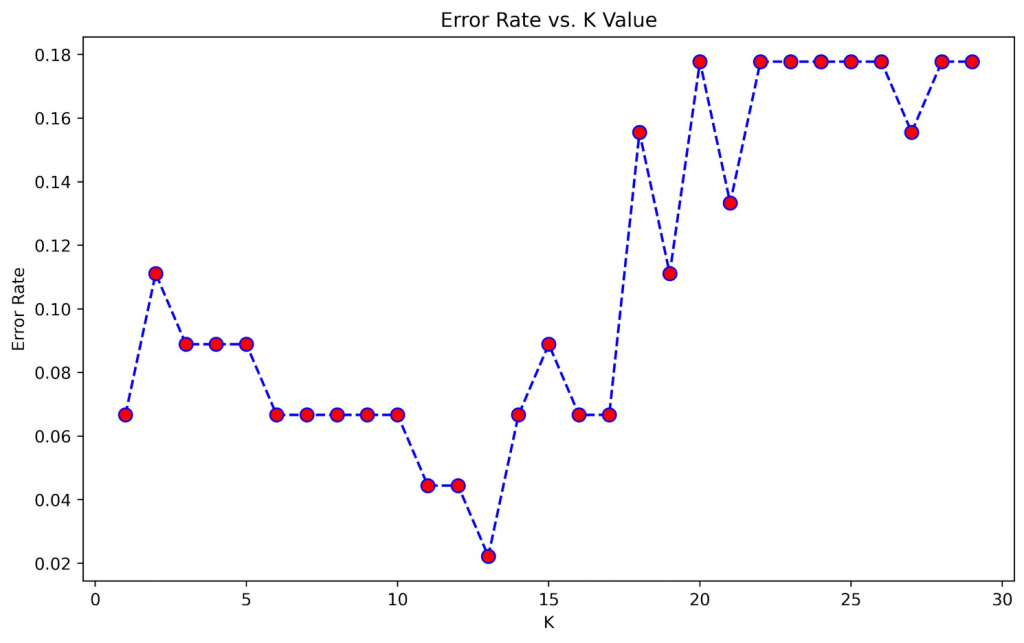
error_rate = []
for i in range(1,30):
knn = KNeighborsClassifier(n_neighbors = i)
knn.fit(X_train,y_train)
pred_i = knn.predict(X_test)
error_rate.append(np.mean(pred_i != y_test))
plt.figure(figsize=(10, 6))
plt.plot(range(1, 30),error_rate,color = 'blue',linestyle = 'dashed', marker = 'o', markerfacecolor = 'red', markersize = 8)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
plt.show()


 iThome鐵人賽
iThome鐵人賽