在一個大數據中,屬性與數據這麼多的情況下,要如何挑出有用的特徵屬性,且將數據都映射於平面二維中呢?
今天就要來跟大家說明如何使用昨天講述到的PCA來操作拉~
首先,先運用「Paint Data」來繪製數據的分布,再將其連接「PCA」組件傳入剛剛的數據。

接著連線「Data Table」將它們之間的連線以Component(構成要素)與Data接。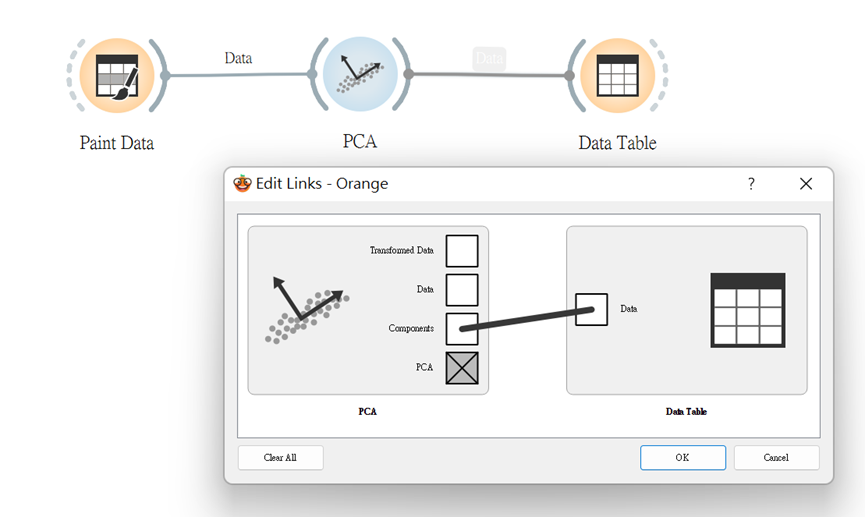
若我們的數據於多維空間中是一條線,那麼只需要幾個主成分就足以解釋它了,而這裡是兩個。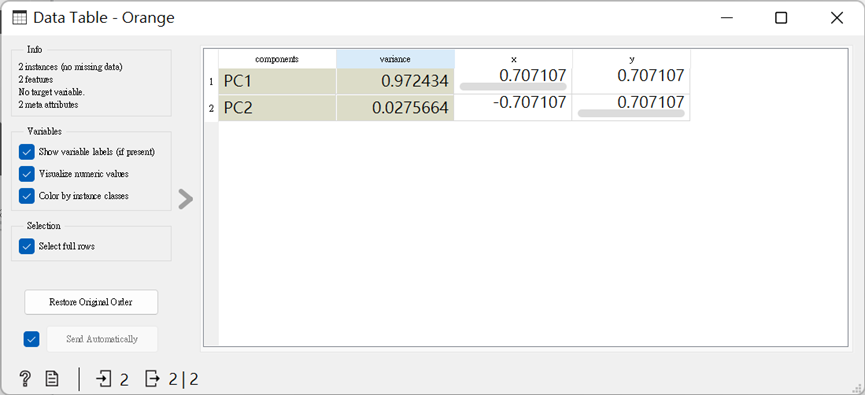
補充說明
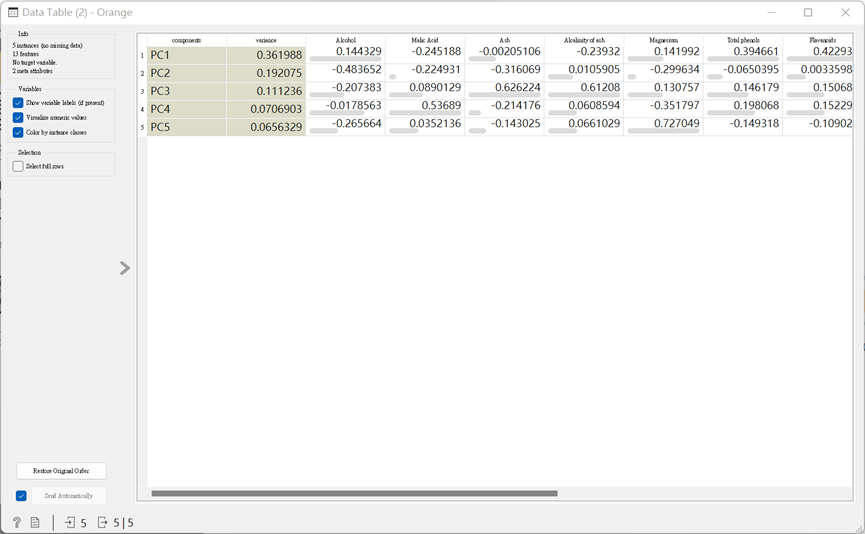
每個 PC 都是其中變量的線性組合。PC1 是提取最大方差的主成分(盡可能地多解釋了差異),PC2 是從PC1剩下的內容中提取最大方差的主成分(盡可能將多出來的剩餘方差),PC3 、PC4…等依此類推。
接下來,我們將會教導大家「如何用PCA將數據轉換為一組不是線性相關的屬性的數據」。
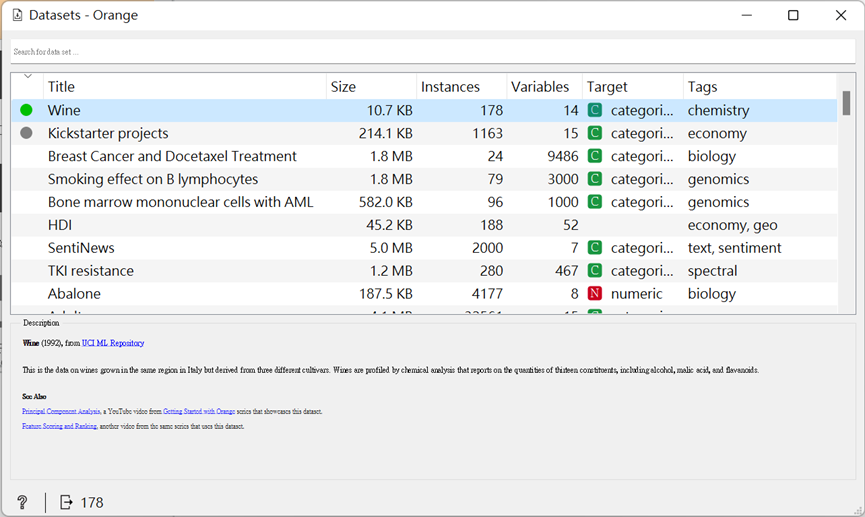
這次我們要用Orange內有的數據集來操作, 先將「Datasets」打開。
而這次選的是Wine這個擁有13個特徵(多維)的數據集來示範,而它為義大利同一地區生產的葡萄酒進行化學分析的結果。
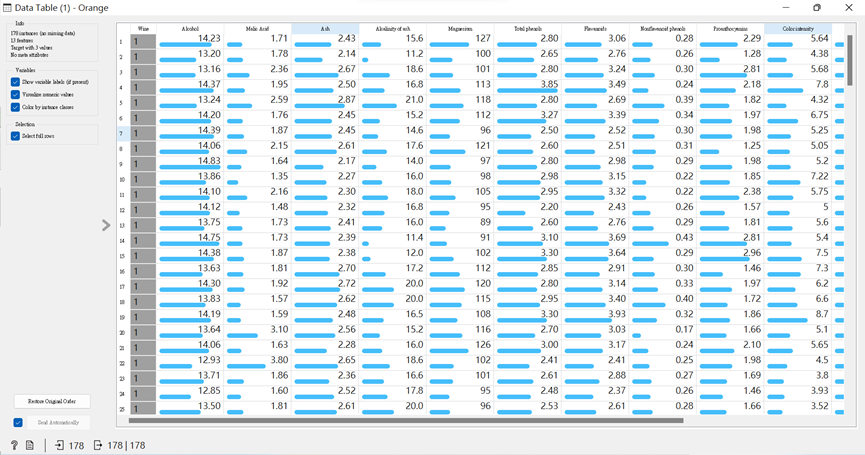
可連接「Data Table」查看左上角的數據資訊與內容。
現在大家可能在想,那後續要用多少個主成分呢?
其實最好就是先選前幾個主成分,像是可覆蓋住80%數據的主成分即可,在此Orange有顯示方差的比例,而我們可以由下方GIF看到,我們選到第五個主成分時,就已達到可解釋80%數據的量了。

那麼我們則可接「Data Table」與「Scatter Plot」來查看數據呈現了!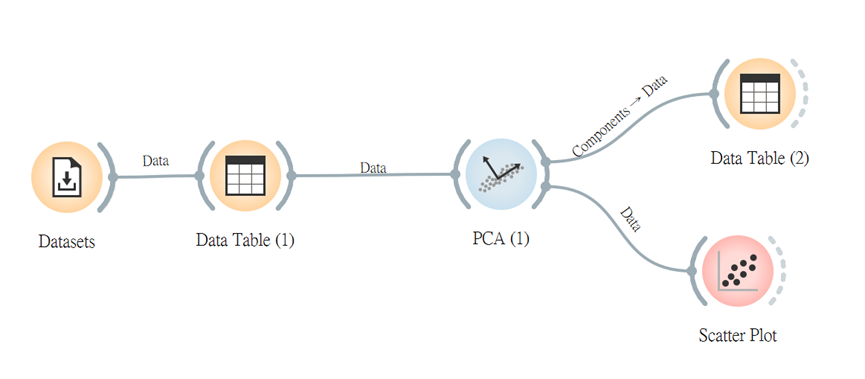
我以第一與二的主成分來繪圖查看,會發現這三組方差的分離效果良好。
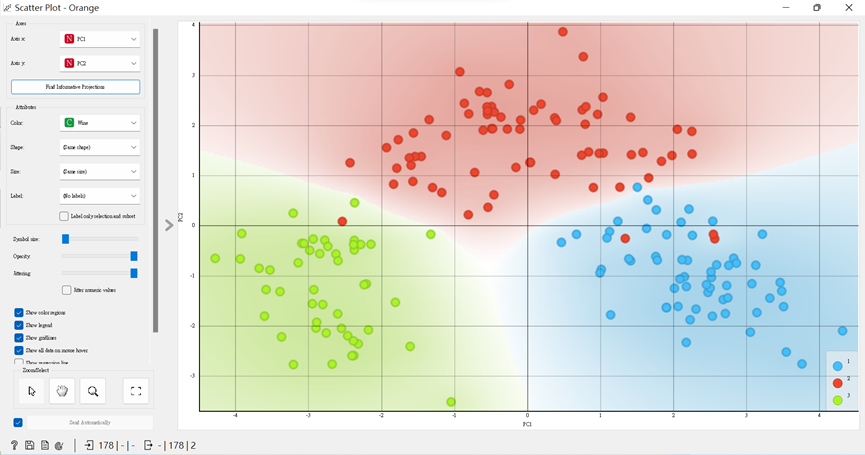
再經由Data Table看看每個屬性於主成分中的比例。完成以上動作,也算是把數據降維與視覺化囉,有興趣的人,可以再多探索其背後意涵喔!
好啦~今日就先到此囉,這篇我個人覺得難度偏難,大家可以慢慢摸索集練習,我們明天繼續加油!
參考資料:
Orange

