來到了鐵人賽的2/3天數了!再撐十天就可以完賽啦~好興奮壓>□< 我們要堅持下去壓,我相信若有看完的你們,一定會感到很充實der!
準備好,我們就繼續開始拉~~
不知道大家還記不記得第18篇講述PCA時,我們有用到「Paint Data」這個組件繪圖,那今天一樣我們會先用它來初步感受K-means的分群畫面。
首先,我自己畫出了,以人眼看為三個很明顯的群集。
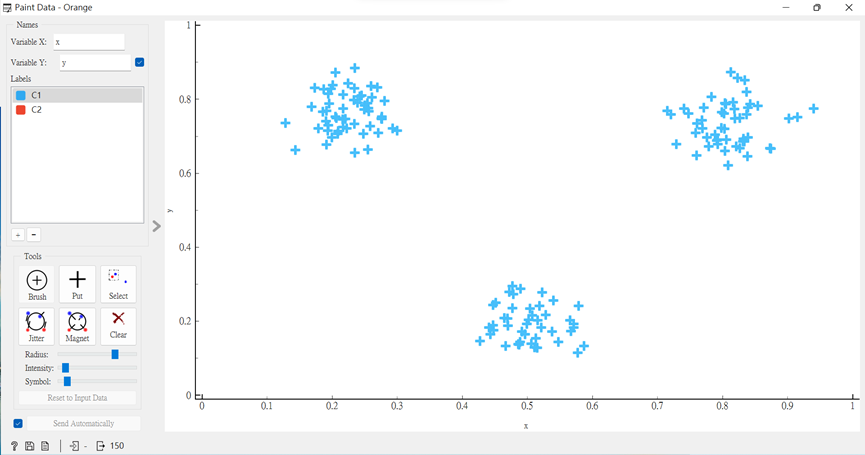
再來,我將它連接至「K-means」,以及再用「Scatter Plot」視覺化呈現對照看。
若是我手動更改群集數,那們是在呈現上K-means將會如何分群。
那在我們調整過程中,會發現在我們調整為三個群集時,它可以如我們所期待很好地將它們分類好。

在前面,我們皆是以自己分配的方式來去看群集最佳的數目,那在Orange中,我們可以運用群集的評分機制,來去更改群集數,進而找到其最良好地群集數。
那我們評分機制,則是用Silhouette analysis(輪廓係數法),會顯示每個數據點擬合群集的評分,依照評分得到最佳分群。
補充說明 Silhouette analysis
其概念為 (找出同群資料點內最近)/(不同群越分散) 的值,而它滿足群集的定義,我們可以用以下公式來了解一下。
a: 同群間的距離
b: 不同點間的點平均距離
S:越大越好,代表著分的也越清楚
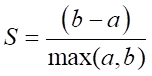
於K-Means組件中,點擊下方「From」,就會看到它自動幫你判定最佳群集數,右方數字也就是S值。
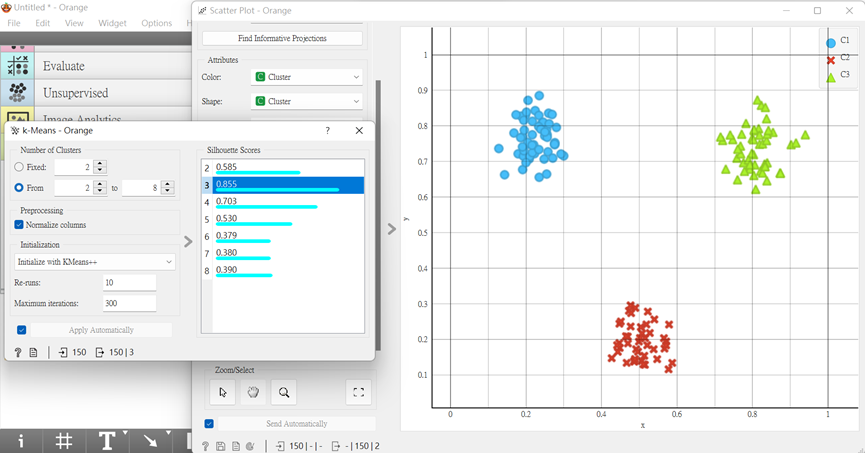
再來,我們可以打開「Paint Data」測試它判斷其準度。(這個步驟我覺得很有趣,邊玩邊學的概念~

Scatter Plot變得很繽紛捏╰(ˊˇˋ)╯
但我上面畫的皆是故意用一群群地,讓它很好辨識,倘若用其它圖案呢?
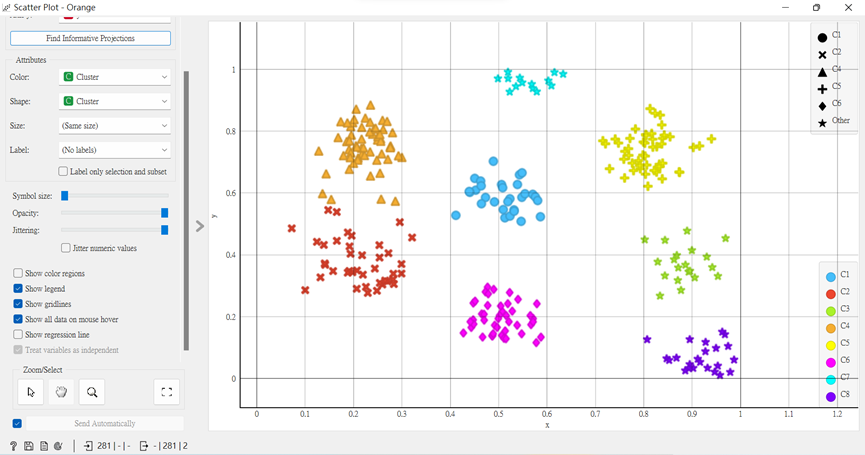
我畫出一個笑臉來,這裡來說,以人眼判定會是三堆,但K-means卻認定為六個,因為它的演算法,是依據距離較近的族群為一個群集,固然在判斷上K-means比較適用於球形(成堆)的數據點,若為其它形狀,則很容易判斷錯誤

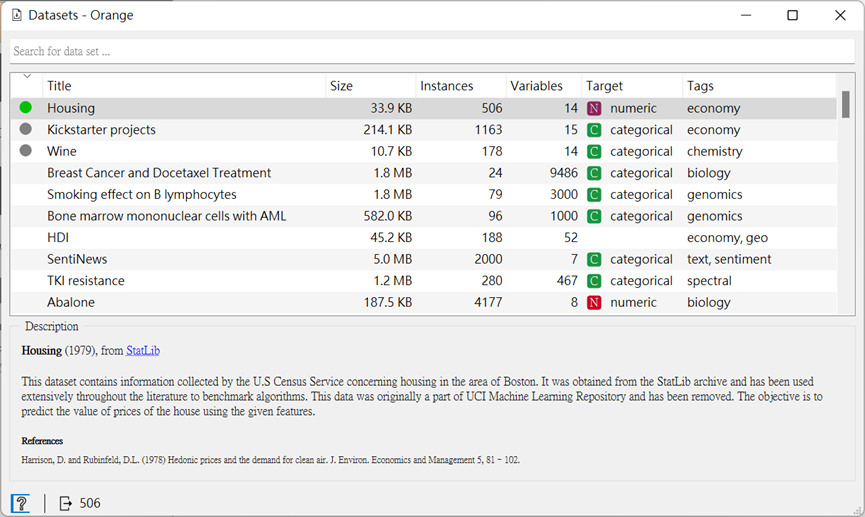
接下來,我們將運用真實數據進行分群看看。而這次用的數據一樣是從「Datasets」中的「Housing」(沿用第十九篇有用到的數據,那邊也有這個數聚集更詳細屬性的中文資訊)。
選好後,我們先設定兩群集,那因為其數據為迴歸型,所以我們用「Box Plot」來看它的效果!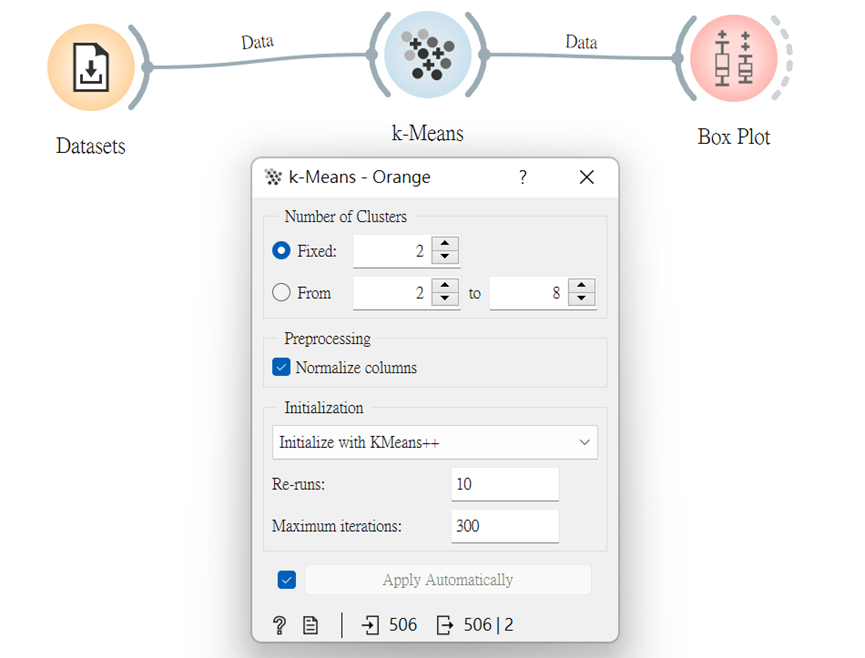
從以下GIF可以看出,當中個屬性間的數據集,都蠻分離的,重疊的比沒重疊到的數據少,看來分群效果應該會比較分明些。

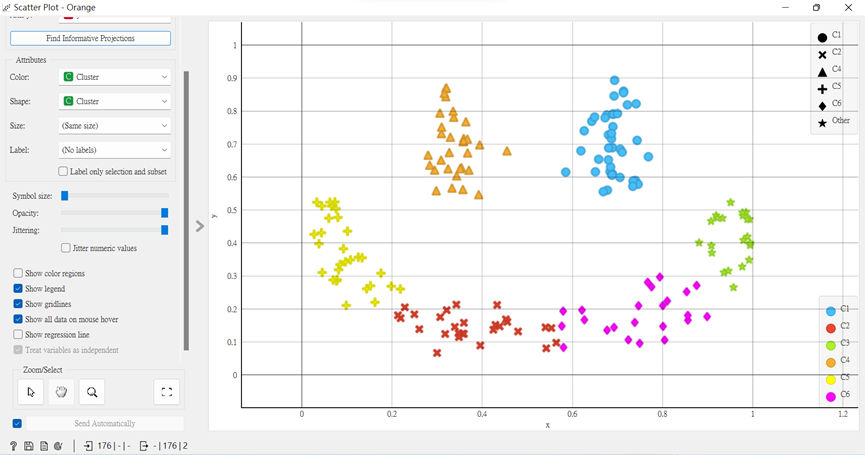
我們用之前說過的MDS看看吧!
從以下圖示來看,有些資料雖然K-means沒分好,但以大部分的數據可以明顯看出為兩大群。

好哩~終於完成今天大篇幅的解說,希望大家也可以嘗試看看不同的文件玩玩看,跟我一樣邊學邊玩啦!
參考資料:
Orange
Kmeans分群演算法 與 Silhouette 輪廓分析


 iThome鐵人賽
iThome鐵人賽