在上一篇我們有用到K-means把數據分群以及視覺化其分群效果,但若是沒先了解過K-means的你,經由上篇應該還沒有很懂它的運作方式吧,今天我將帶你一同了解其內涵運作模式。
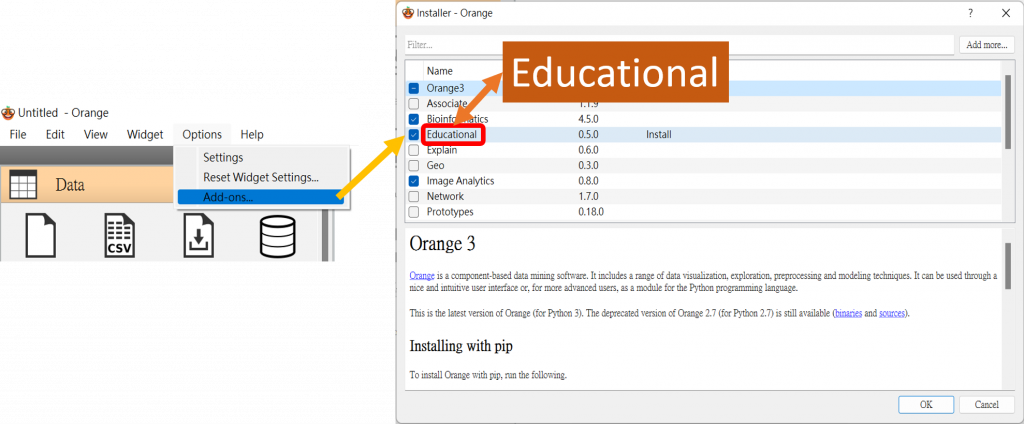
在第十六篇時,我們有提到插件的功能,而今天我們要用到裡面的「Educational」,它為一個為機器學習量身打造的插件,裡面有著許多有趣的組件,我們先把它安裝起來吧!
一樣從工作列表點選「Options」,再來點選其中最下面的「Add-on(插件)」,打開之後,找到「Educational」,安裝後,我們將重啟Orange,就會看到它囉~
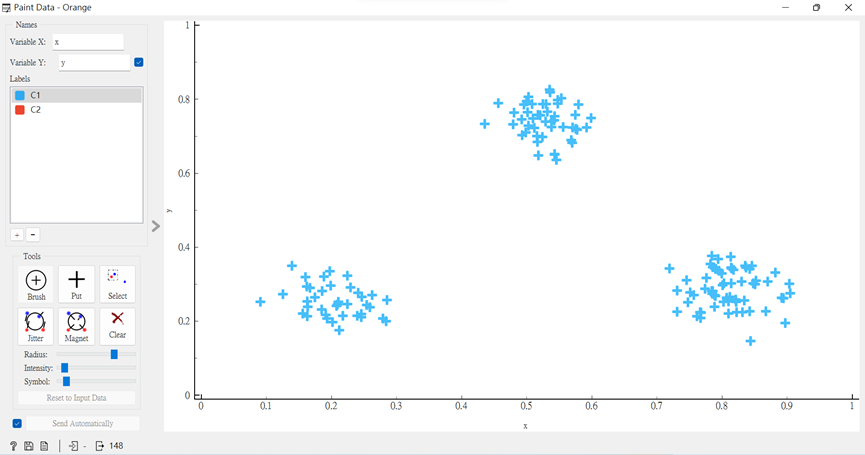
打開「Paint Data」繪製三個數據群。
接上「Interactive k-Means」看看運作效果。
圓圈處是個數據集的中心(質心)。
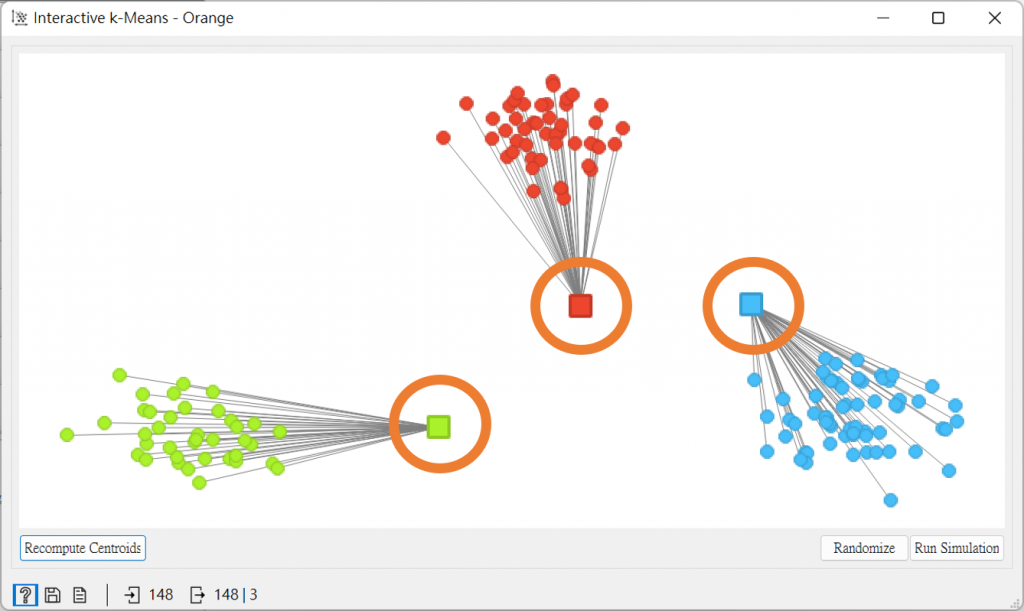
我們可以按右下的「Random(隨機)」,圖案中的質心就會隨機生成,而每個數據點皆與質心有所關聯,而K-means通過這種方式來找尋集群。

但上面最終得出的結果並不是我們要的,這是我們可以按左下角的「Recompute Centroids(重新計算質心)」,就會跳出較好的結果。

大家若在按後發現還是有些點沒有在正確的群集,則可按下左下的「Reassign Membership(重新設計族群)」,還是沒有,就繼續按,直到質心沒有變動,那麼就是K-means最終的分配。
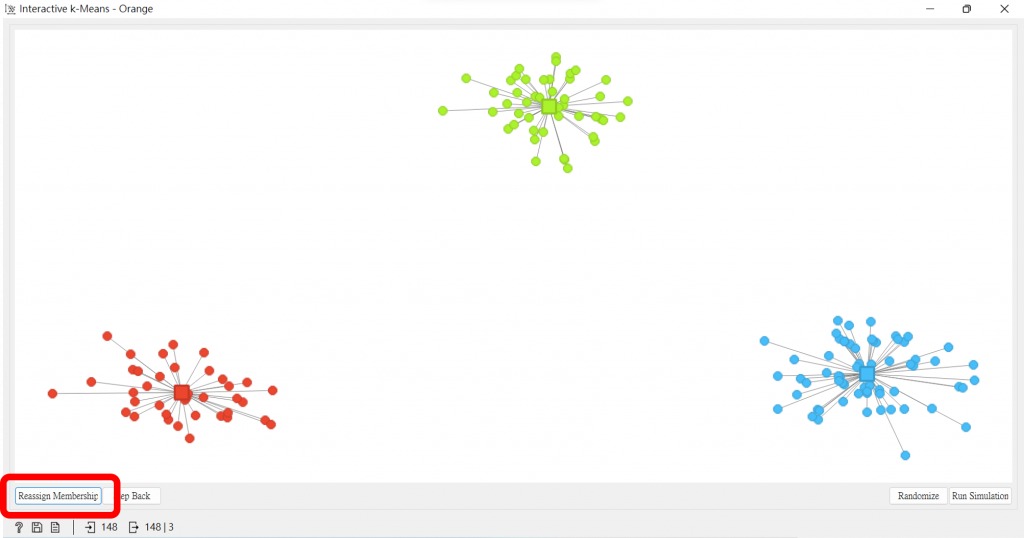
那我們現在手動來改變一下質心,看看最終結果是否有如我們預期。
由以下影片檔,可以看出若初始質心設定不對,最終成果也無法如期分配,所以我們可以得知起始質心相當地重要。
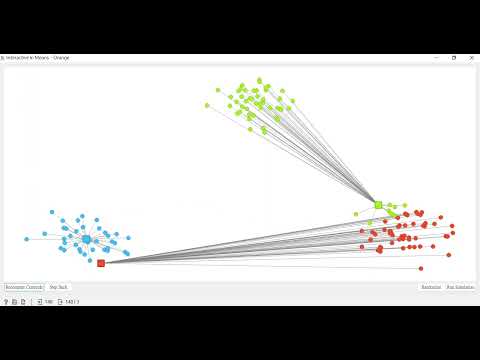
那麼今日份就到這啦~我們明天見~
參考資料:
Orange

