
在先前的章節中,我們已經深入探討了大型語言模型(LLM)在可觀測性領域中的定位與重要性。我們認識到:LLM 可觀測性的核心,在於如何評估其輸出的不確定性。
而這個「不確定性」的關鍵,往往來自於我們給予模型的輸入,也就是我們與 LLM 互動的起點:「Prompt」。在 LLM 的世界中,Prompt 是一等公民,是我們投入最多心力的地方。它不只是輸入文字,更是觸發模型行為的設計工具。
因此,我們的旅程將從軟體工程師最熟悉的應用層開始,反向理解 LLM 的運作邏輯。我們會從自然語言與對話這個人類最直觀的界面出發,逐步熟悉 LLM 的特性與機制,最終能夠打造出真正實用、具備可觀測性能力的應用場景。

身為工程師,我們習慣於精確和確定性。我們用 git commit -m "fix(auth): resolve token expiration bug" 來提交程式碼,用 kubectl apply -f deployment.yaml 來部署應用。每一個指令都有明確的語法和可預測的結果。
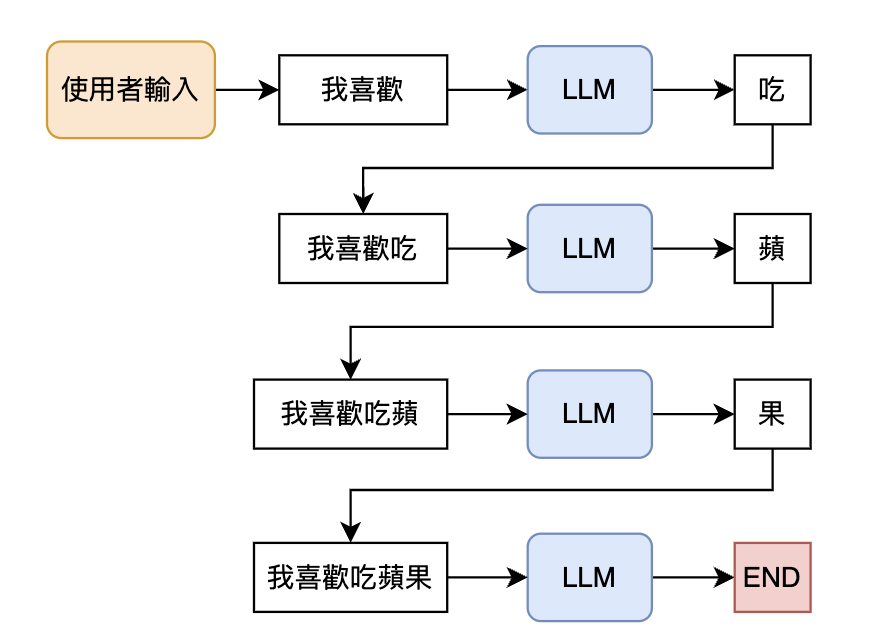
但現在,我們面對的是大型語言模型(LLM)這個強大的「黑盒子」。我們不再撰寫嚴格的判段式,而是如同人類日常對話中的問答,如:「你最喜歡的水果是什麼?」。
https://ithelp.ithome.com.tw/articles/10351250
這就是核心的轉變:我們從確定性的程式碼轉向了機率性的自然語言。這既是 LLM 驚人能力的來源,也是我們在工程實踐中巨大挑戰的開端。
在這個新世界中,我們可以將 LLM 視為一個強大的「通用任務處理引擎」,而 Prompt 就是驅動這個引擎的「原始碼」或「API 請求」。Prompt 的品質,直接決定了 LLM 輸出的品質、穩定性和可靠性。
許多人認為寫 Prompt 就像在聊天,隨意提問。但要獲得穩定、可預測的結果,我們必須將這個過程「工程化」。而一個結構良好的 Prompt,就像一個參數完整的函式呼叫,應該包含以下幾個部分:
讓我們看看前後的差別:
👎 不佳的範例 (像聊天):
"我需要一個 API 延遲的 Prometheus 警報"
👍 好的範例 (像 API 請求):
# 角色 你是一位資深的 SRE 專家。 # 任務指令 產生一個 Prometheus 的警報規則 YAML 檔案。 # 上下文 - 警報名稱: HighApiLatency - 監控指標: http_requests_latency_seconds_p99 - 觸發條件: 當指標在過去 5 分鐘內持續大於 0.3 秒時觸發。 - 嚴重等級: critical # 輸出格式 請直接提供 YAML 格式的程式碼,不需要任何額外解釋。
顯然,後者更能產出我們期望的、可直接用於自動化流程的結果。撰寫清晰、具體的 Prompt,是提升 LLM 應用品質的第一步。
理解了 Prompt 的結構就像是知道了 API 的規格書,但要寫出能穩定返回高品質結果的請求,我們還需要掌握一些如同「最佳實踐」的通用原則。
沒有人能一次就寫出完美的程式碼,Prompt 也是如此。這是一個需要不斷實驗和迭代的過程。
一個好的 Prompt 應該像好的程式碼一樣:清晰、直接、無歧義。
指令要明確:使用命令式的動詞,如「寫入」、「分類」、「摘要」、「解析」、「生成」。為了讓模型清楚地劃分指令和待處理的資料,可以善用分隔符,例如 ###,這就像在程式碼中劃定清晰的區塊。
DevOps 範例:解析日誌
### 指令 ### 從以下的應用程式日誌 (application log) 中,提取時間戳 (timestamp) 和錯誤訊息 (error_message)。 請以 JSON 格式回傳結果。 ### 日誌原文 ### [2025-09-06 10:40:00] ERROR: Failed to connect to database 'prod_db' on host '10.0.1.25'.預期輸出:
{ "timestamp": "2025-09-06 10:40:00", "error_message": "Failed to connect to database 'prod_db' on host '10.0.1.25'." }
避免模糊描述:與其說「寫一個刪除舊檔案的腳本」,不如說「寫一個 Bash 腳本,使用 find 指令刪除 /var/log 目錄下超過 30 天的 .log 檔案」。你提供的細節越具體、越可量化,模型需要猜測的空間就越小,結果自然越可控。
這或許是反直覺但卻極其重要的一點:與其告訴模型限制,不如直接引導它走向你期望的路徑。專注於描述你想要的正面行為,能讓模型更好地理解目標,並產出更安全的結果。
試想一個輔助生成腳本的 AI,一個不佳的提示可能會專注於「禁止事項」:
❌ 不佳的提示 (專注於「不要做」):
你是一個輔助腳本生成的 AI。不要使用 'rm -rf'。不要在沒有確認的情況下刪除檔案。當用戶提出「我需要一個腳本來快速刪除舊日誌」時,這種提示不僅可能無法阻止模型生成危險的指令,甚至反而將 rm -rf 這個壞主意「植入」了它的思考路徑中。
一個更好的提示會為模型規劃好一條安全的、符合最佳實踐的執行路徑:
✅ 更佳的提示 (專注於「要做什麼」):
你是一個輔助腳本生成的 AI,專門產出安全且符合最佳實踐的 Bash 腳本。 1. 所有檔案刪除操作,都必須使用 'find' 指令搭配 '-mtime' 和 '-daystart' 參數來定位檔案。 2. 在執行實際刪除前,腳本必須先使用 'echo' 搭配迴圈列出將被刪除的檔案清單,並加上顯眼的警告訊息。 3. 如果用戶的請求可能造成風險,應主動提出警示並提供更安全的替代方案。在這個版本中,我們給了模型一個清晰的安全作業程序 (SOP)。當用戶提出相同的請求時,它會產出一個先列出檔案、再等待確認的腳本,這才是一個工程師真正想要的、可信賴的結果。
到目前為止,我們討論的都是單一 Prompt 的優化。但在真實世界的應用中,一個複雜的任務往往由多個 Prompt 組成的鏈 (Chain) 來完成。這正是挑戰的開始。
你可能會發現,鏈中的每一個 Prompt 單獨測試時表現都很好,但將它們串聯起來後,整個應用的輸出品質卻嚴重下降。這背後有兩個主要的工程問題:
這告訴我們,單獨評估每個 Prompt 是遠遠不夠的。我們必須將整個 Prompt 鏈視為一個微服務或分散式系統來對待。系統中的任何一個節點出現問題,都可能導致整個請求的失敗。
正如我們已經強調許多次,LLM 本質上在每次的輸出中都會引入很小的不確定性或錯誤率。雖然 1% 的錯誤率似乎可以忽略不計,但當 LLM 應用執行一系列操作時,這種不准確性會急劇加劇,這種現象稱為「錯誤放大」。
在 LLM 驅動的應用中,Prompt 不再只是簡單的「提問」,它已經成為需要被嚴謹管理的核心業務邏輯。
這意味著我們必須將 DevOps 的最佳實踐應用於 Prompt 的生命週期管理:
而要解決 Prompt 鏈中的品質衰退問題,最好的方法就是建立端到端的可觀測性與評估機制。我們需要追蹤每一個環節的輸入、輸出、延遲和品質,才能在問題發生時快速定位,就像我們用 OpenTelemetry 追蹤分散式系統中的請求一樣。
今天,我們重新認識了 Prompt:它不僅是與 AI 的對話,更是構成新一代應用的、需要用工程紀律來嚴謹對待的 API 請求。我們也看到了,當這些請求被串聯成複雜的自動化系統時,將帶來全新的穩定性挑戰。
將 Prompt 視為程式碼來管理,只是第一步。真正的挑戰在於如何確保由這些 Prompt 構成的應用,在面對 LLM 的不確定性時,依然保持健壯、可靠和可維護。
References:


