
在上一篇文章中,我們達成了一個重要的共識:Prompt 不僅是與 AI 的對話,它更是需要用工程紀律來嚴謹對待的 API 請求。我們也意識到,由多個 Prompt 組成的複雜工作流極其脆弱,一旦其中一個環節出錯,整個系統便可能失效,且除錯過程如同大海撈針。
這引出了一個尖銳的問題:如果 Prompt 就像程式碼,為什麼我們還在用筆記本或 Confluence 頁面,以複製貼上的方式管理它?如果它的不穩定性會直接衝擊應用的可靠性,為什麼我們沒有為它建立自動化測試?
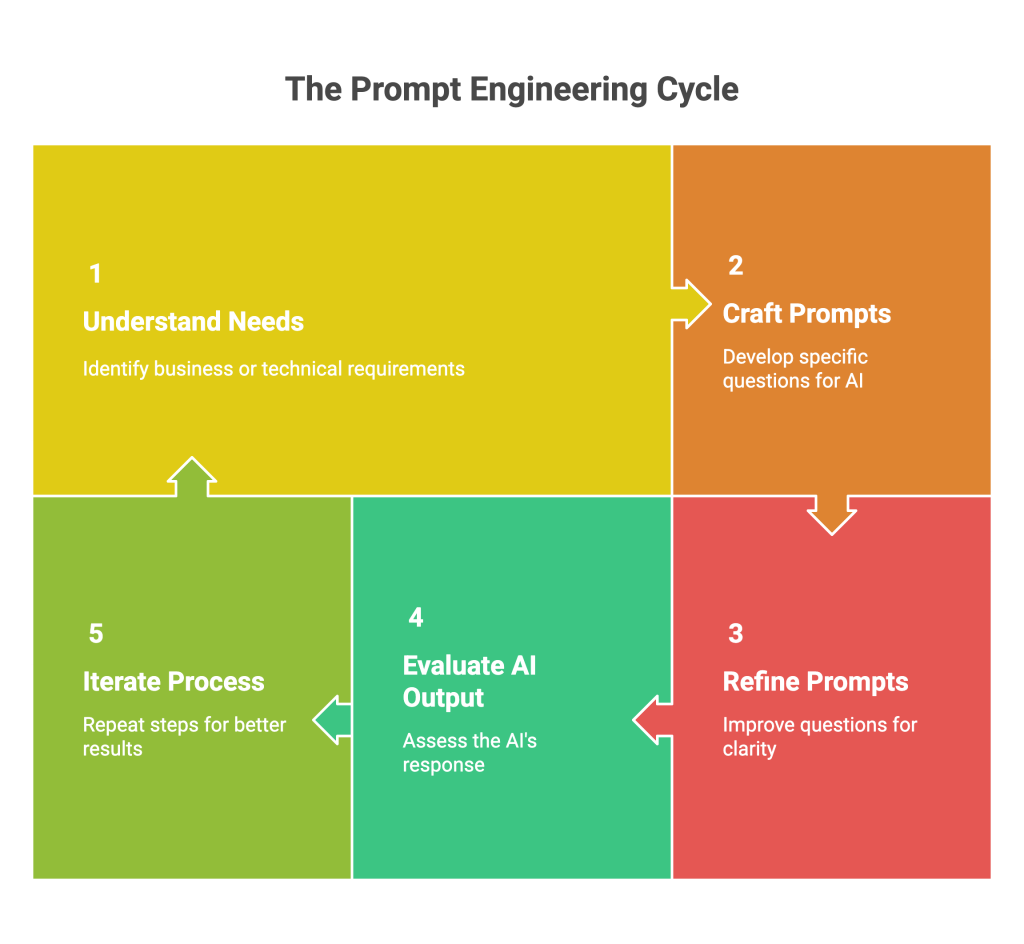
今天,我們將借鑑 DevOps 的核心理念與實踐,為 Prompt 建立一個從開發、測試、版本控制到部署的完整生命週期 Prompt Development Lifecycle (PDLC)。我們的目標,是將 Prompt 從「一次性的消耗品」,轉變為真正可信賴、可維護的「工程資產」。
https://www.sapbwconsulting.com/blog/inbound-marketing/prompt-engineering
一個穩健的生命週期始於一個高品質的產出物。在將 Prompt 納入自動化流程之前,我們需要掌握一些進階技巧,從源頭上提升其輸出的穩定性和可觀測性。
在傳統機器學習裡,模型需要透過額外的訓練資料來調整參數,才能學會新的任務;但在 LLM 世界裡,in-context learning(ICL) 讓模型只靠 Prompt 裡的上下文資訊,就能臨場理解任務規則並產生合理輸出。這代表我們不需要重新微調模型,而是透過在 Prompt 中嵌入「範例、規則、說明」來塑造模型的行為。
ICL 有不同的操作形式:
這些模式其實是同一個原理的不同層次,差別在於我們給模型多少上下文去「模仿」。
在各種 ICL 方法中,Few-shot prompting 最常用也最直觀。我們可以把它理解為:在 Prompt 裡放進幾個「輸入 + 預期輸出」的案例,就像在程式裡寫了單元測試。這讓模型在處理新輸入之前,就已經學會該遵循的格式與邏輯,大幅降低隨機性。
DevOps 範例:統一不同來源的 CI/CD 日誌
想像一下,你需要一個 Prompt 來解析來自不同 CI/CD 工具的日誌,並將其轉換為標準的 JSON 格式。
### 指令 ### 你是一個 CI/CD 日誌解析專家。請根據我提供的範例,將新的日誌內容解析為包含 "source", "job_id", "status" 和 "message" 的 JSON 物件。 ### 範例 1 ### 日誌輸入: "[Jenkins] Job 'build-project-A' (ID: 123) finished with status: SUCCESS" JSON 輸出: {"source": "Jenkins", "job_id": "123", "status": "SUCCESS", "message": "Job 'build-project-A' finished successfully"} ### 範例 2 ### 日誌輸入: "GitLab CI job 456 failed. Error message: 'dependency build failed'." JSON 輸出: {"source": "GitLab CI", "job_id": "456", "status": "FAILURE", "message": "dependency build failed"} ### 待處理日誌 ### 日誌輸入: "GitHub Actions workflow 'deploy-prod' completed with conclusion: success. Job ID: 789." JSON 輸出:透過提供這兩個範例,LLM 能輕易學會如何處理第三種來自 GitHub Actions 的新格式,並穩定地輸出我們期望的 JSON 結構。
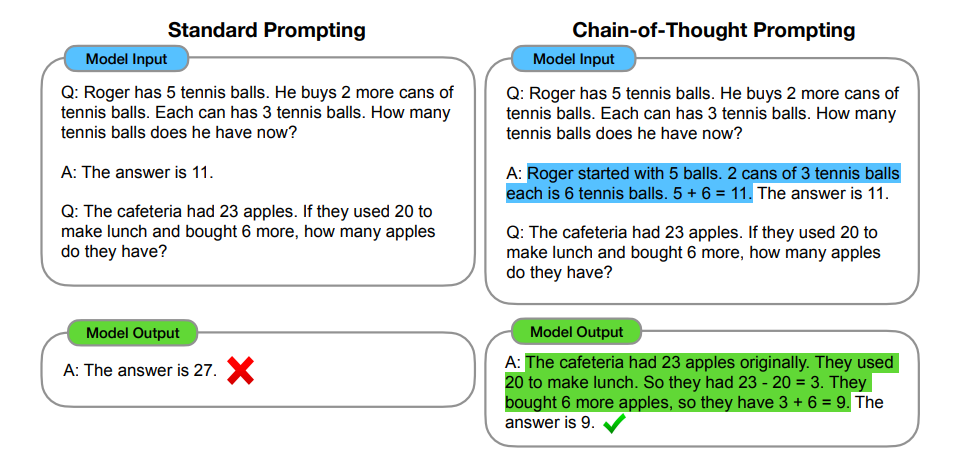
https://arxiv.org/pdf/2201.11903
在 ICL(in-context learning)的脈絡下,CoT 是要求模型先產生中間推理步驟,再給最終答案的提示手法;對需要多步推理的任務(算術、常識、符號推理等)特別有效,因為這些中間步驟能穩定模型的決策並提升正確率。經典研究顯示,提供少量帶推理步驟的示例即可顯著提升表現;之後的「Self-Consistency」以多路推理取眾數,進一步強化效果。
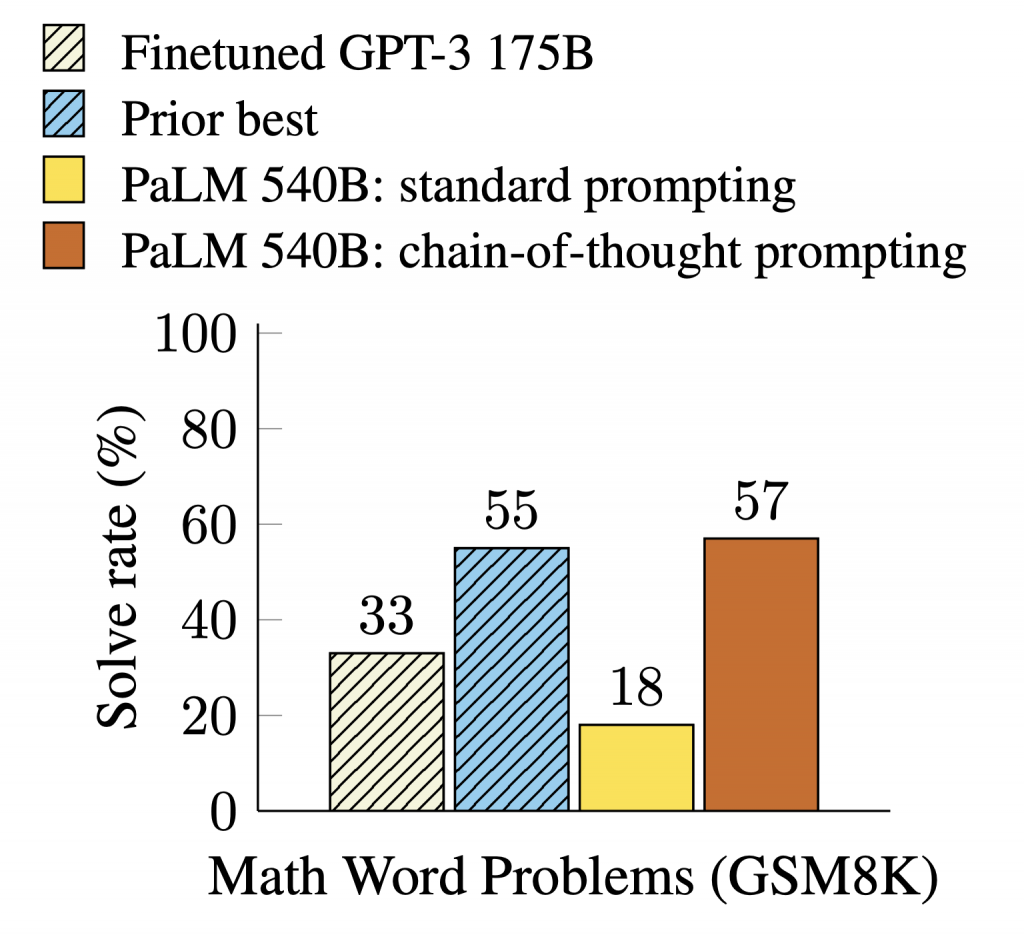
https://arxiv.org/pdf/2201.11903
ICL 是框架,CoT 是技巧。ICL 負責把規則與示例放進脈絡,CoT 負責把推理路徑顯性化,兩者結合能同時提升準確率與可觀測性。近年的工作也探索「精簡版 CoT」以兼顧成本與效能。
何時使用 CoT:
使用建議:
reasoning(簡短依據)、uncertainty(不確定性旗標)與 violations(規則命中/違規項),作為可稽核鉤子。<REDACTED>)。這不僅能提升複雜邏輯推導的準確率,更重要的是,這些輸入讓模型的決策過程變得透明且可觀測。當結果出錯時,我們可以回溯它的思考鏈,精準定位是哪一個環節的推導出了問題。
DevOps 範例:Kubernetes Pod 故障排除
你是一位資深的 Kubernetes 站點可靠性工程師 (SRE)。一個名為 'auth-service-pod' 的 Pod 處於 'CrashLoopBackOff' 狀態。 請使用思維鏈的方式,一步步引導我進行故障排除。 首先,列出你的排錯步驟。 然後,為每個步驟提供具體的 kubectl 命令和你的分析。LLM 的輸出將不再只是一個冷冰冰的指令,而是一個有邏輯、有依據的排錯指南,例如:
第一步:獲取 Pod 的詳細狀態和近期事件。
kubectl describe pod auth-service-pod
分析:這能讓我們看到容器重啟的原因,以及是否有鏡像拉取失敗、儲存卷掛載錯誤等問題。
第二步:查看容器的即時和歷史日誌。
kubectl logs auth-service-pod
kubectl logs auth-service-pod --previous
分析:應用程式本身的錯誤,如資料庫連線失敗或配置錯誤,通常會在這裡顯現。
第三步…
我們必須將這句箴言刻在心裡:Prompt is Code. Code belongs in Git.
將 Prompt 納入版本控制,是實現其工程化與團隊協作的基石。但僅僅把 Prompt 存成檔案還不夠,還需要一套完整的管理機制。
在專案中建立一個專門的 Repo(例如 project-prompts),將所有 Prompt 作為獨立的 .txt 或 .md 檔案進行儲存。每個檔案應有明確的命名規則(例如 parse_log.v1.md、summarize_ticket.v2.md)。
任何對 Prompt 的修改都必須透過 Pull Request (PR) 流程。在 PR 描述中,要求:
這提供了完整的審查與可追溯性。
將「靜態指令」與「動態變數」分離,讓 Prompt 更加可重用。例如利用 Jinja2:
### 指令 ###
你是一個日誌解析專家。請將以下的日誌內容解析為 JSON 格式。
### 日誌原文 ###
{{ log_data }}
在應用程式中,動態傳入 log_data,保持結構穩定。
除了透過 Git 來追蹤 Prompt 的版本之外,近年也出現了許多專門的 Prompt Management 工具,能進一步支援團隊在更大規模的應用中進行治理與協作。例如,像 LangChain Hub 或 PromptHub 這樣的平台,可以讓團隊集中管理 Prompt,不僅能進行版本控制,還支援社群共享與快速迭代,特別適合需要持續復用和優化的場景。另一方面,雖然 Weights & Biases (W&B) 或 MLflow 本來是模型實驗平台,但也有越來越多團隊將它們用來追蹤 Prompt 的版本與測試結果,建立出一種「Prompt 實驗記錄」的模式。
這些工具和實務的出現,顯示 Prompt 已經逐漸脫離「一人一檔」的初階狀態,往工程化、協作化與平台化邁進。對團隊來說,關鍵不只是「存放在哪裡」,而是如何確保 Prompt 的版本清晰、演進有跡可循,並且能即時觀測其在真實場景中的效能表現。
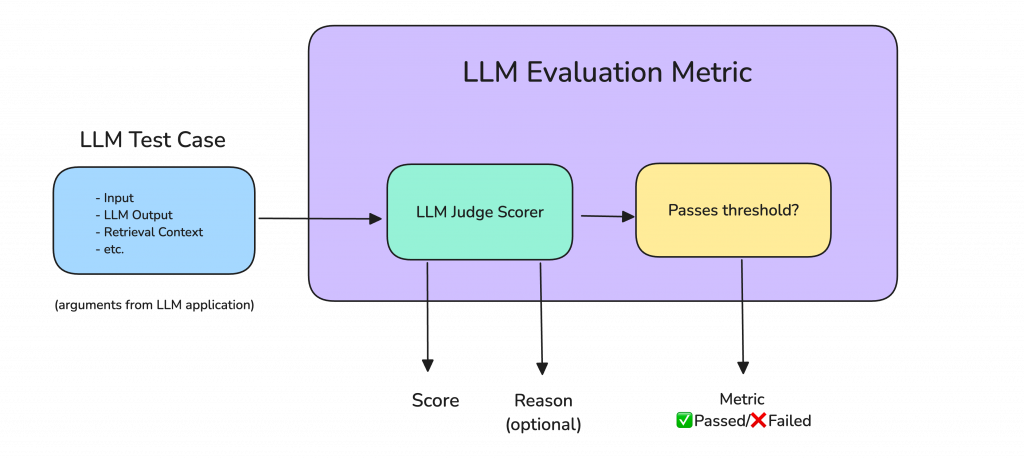
https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation
這是將 Prompt 工程化的核心,也是 DevOps 精神的直接體現。
目的:驗證單一 Prompt 在給定一組固定的輸入下,是否能產出格式正確、內容符合預期的輸出。
方法:我們可以編寫一個評估腳本 (例如使用 Python),它會讀取一個 Prompt 檔案,向 LLM API 發送請求,然後對返回的結果進行一系列的斷言 (Assert)。
test_prompt.py 腳本片段範例:
def test_log_parsing_prompt(): prompt = load_prompt('prompts/parse_log.jinja2') log_input = "[Jenkins] Job 'build-project-A' (ID: 123) finished with status: SUCCESS" # 呼叫 LLM API 獲取結果 output = call_llm_api(prompt, {'log_data': log_input}) # 斷言測試 assert is_valid_json(output), "輸出不是有效的 JSON" data = json.loads(output) assert data.get('source') == 'Jenkins', "來源解析錯誤" assert data.get('status') == 'SUCCESS', "狀態解析錯誤"
補充:LLM 評估專用工具 / SDK
除了手動撰寫測試腳本,現在也有許多開源或商業化的 SDK 可以幫助我們進行更系統性的測試與評估,例如:
這些工具可以與 CI/CD 流程整合,讓 Prompt 的品質驗證從「手動測試」進化為「自動化品質管線」。
一個巨大的痛點是:當 OpenAI 或 Google 等廠商更新他們的底層模型時,你原本運作良好的 Prompt 可能會突然失效。這就是所謂的 「模型漂移(Model Drift)」。
為了對抗這種漂移風險,我們應該建立一組「黃金標準(Golden Set)」輸入輸出對,組成完整的 回歸測試集。這些測試樣本應涵蓋常見場景、邊界條件與錯誤輸入等關鍵案例。
每當 Prompt 有重大變動或模型 API 發布新版本,就完整跑一次測試集,並自動比對新舊輸出是否一致(語義/格式皆可比)。若有重大偏移,則標記為風險或異常,阻止進入正式環境。這不僅能避免使用者直接面對問題輸出,也讓 Prompt 團隊能更早進行修復與回退。
當我們將以上所有環節串聯起來,一個針對 Prompt 的 CI/CD 流程便清晰地浮現了:
至此,我們已經可能腦中勾勒出一套為 Prompt 建立的自動化的品質保證與 CICD 流程。
至此,我們已經為 Prompt 建立了一套自動化、可擴展、可治理的工程化流程。從設計、測試、版本控制,到部署與交付,每一步都對齊了 DevOps 精神,也為 LLM 專案導入了清晰可管理的開發流程。
不過,這一篇的重點並不在於實作細節,而是希望先幫大家建立一個概念性的框架「Prompt 應該被當作程式碼一樣來開發、管理與監控」。
我們從設計模式、測試機制、CI/CD 到部署流程,做了一次初步的總覽,作為理解 PromptOps 思維的起點。
References:

