昨天介紹了簡單線性迴歸模型的基本架構,當資料只有一個解釋變數或特徵時(一個反應變數Y,多個解釋變數X的情境),這個方法相當方便且容易解釋,但是當資料存在較多解釋變數的情況或許就沒那麼適合繼續使用簡單線性迴歸模型。雖然還是可以繼續利用該模型分別針對每個解釋變數建模,不過這樣的做法存在幾個問題,例如只有一個反應變數時,要如何整合這幾個簡單線性迴歸模型並進行預測;分別建構的模型都忽略了其他解釋變數的影響。因此一個比較合適的方法是將簡單線性迴歸模型延伸到多元線性迴歸模型(Multiple Linear Regression),使迴歸模型可以同時放入多個解釋變數來進行預測以及估計,今天的內容練習以矩陣的方式呈現,並且加上幾何的角度來看看線性迴歸模型。
多元線性迴歸模型為利用多個解釋變數X預測反應變數Y,與簡單線性迴歸相似,但認為加入其他解釋變數可能可以改善模型的表現,因此在模型中納入更多解釋變數來說明或預測反應變數。其中Y為連續型的變數,每個X可以是連續或類別的變數,模型中Y沒有辦法以這些X解釋的部分也會落在誤差項(error term),以下是模型架構(假設有p個解釋變數x,
為p維的向量):
資料: ,
模型: 或
參數: ,
模型假設:(與簡單線性迴歸模型一致)
在多元迴歸模型求解參數的方法與簡單線性迴歸類似,今天的內容以矩陣來表示:
從昨天或今天提到的迴歸模型中可以發現,這個模型想將反應變數Y寫成解釋變數X的某種線性組合,換句話說就是想找到最能夠描述Y的那一種X的線性組合,或是說以X的角度來描述Y。因此可以想成空間投影的概念,將反應變數Y投影到X構成的空間中,如下圖:
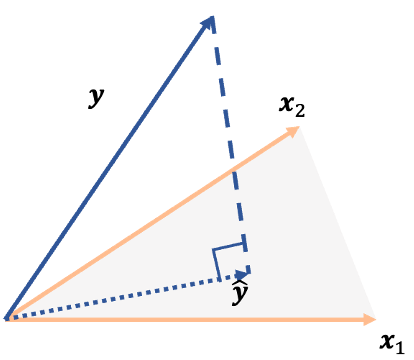
上圖的估計值可以寫成
由上述定義的反應變數估計為
可以將上式想成將反應變數y投影到x空間的方法,因此也被稱為投影矩陣(projection matrix)或hat matrix


 iThome鐵人賽
iThome鐵人賽