昨天的內容提到當資料可以完美的利用一條直線或超平面(hyperplane)分類時,**最大邊距分類器(Maximal Margin Classifier)**是最直覺且容易理解的方法可以將兩類的資料分離,但實際上收集到的資料常常都是兩類資料交錯在一起的情況,這種情況下最大邊距分類器就無法求解出最大的邊距M(margin),如下圖的資料所示。有了昨天的內容當作背景知識,可以更容易理解支持向量分類器(Support Vector Classifier)與支持向量機(Support Vector Machine),作為最大邊距分類器推廣延伸的概念。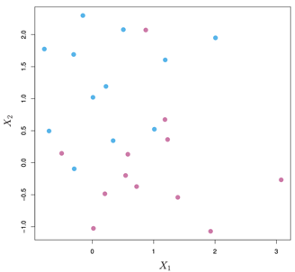
當兩個類別的資料交織在一起或相距沒有很遠時,利用最大邊距分類器(Maximal Margin Classifier)無法得到一個可以用來分類的超平面,又或者是得到的超平面是有問題的,因為他的邊距(margin)很小。然而在最大邊距分類器中的變句也被我們視為分類正確的信心有多大,邊距太小會使得分類器對於單一資料點的變化更加敏感(sensitive),也表示可能有overfitting的問題出現。
在這種情況下Support Vector Classifier的概念是容許一些訓練資料集中的分類錯誤,因此又稱為 soft margin classifier,這樣的方式可以換取對於單一資料點更準確的預測能力,以及對於其他大部分的訓練集資料有更高的分類準確率。
數學上也就是允許一些誤差存在,使少數的資料被錯誤地分到邊界(margin)或超平面的另一側: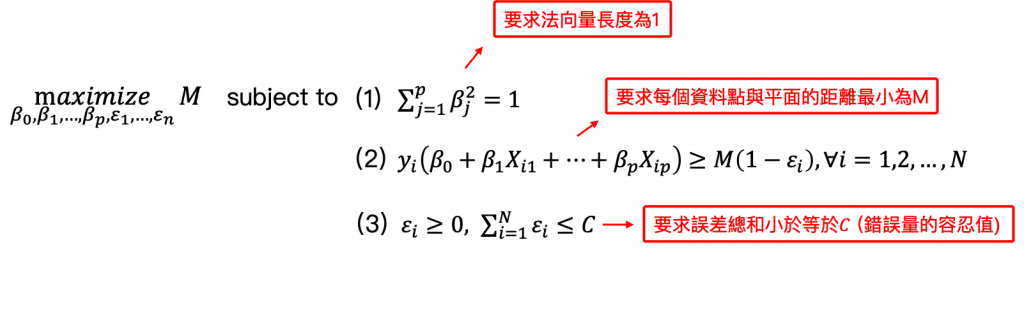
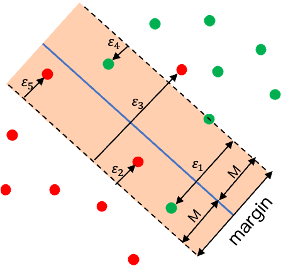
其中限制錯誤總量的參數C為一個tuning parameter,需要利用cross-validation來尋找某筆資料最適合的C,這個參數也就是被分類錯誤(位於hyperplane錯誤的一側)的資料點最多只能有C個,因為被分類錯誤時資料的 。C越大表示找到的邊界越寬容許更多可能分類錯誤或出現更多第2點提到的資料點。
在Support Vector Classifier只有那些位在邊界(margin)上或超越邊界的資料點才會影響最後找到的hyperplane,這些資料點也被稱為支持向量(support vector),其他被分類正確且在邊界對的一側的那些資料並不影響hyperplane。C越大時也表示支持向量可能越多。因此Support Vector Classifier與最大邊距分類器一樣只用了訓練資料集的一小部分來決定分類的hyperplane。
參考資料與圖片來源:
An Introduction to Statistical Learning


 iThome鐵人賽
iThome鐵人賽