在上一篇中,我們是將許多張未分類過的圖像數據,讓電腦幫我們分類與查看它們之間的相似度(屬於無監督式學習);那麼今天,就是要將另外一群已分類好之圖像數據,進行模型訓練與評估,並且查看其混淆矩陣(屬於監督式學習)。
補充說明 Classification vs Clustering
| Classification(分類) | Clustering(聚類) |
|---|---|
| 監督學習 | 非監督學習 |
| 根據對應的類別標籤,對後來再輸入的數據進行分類的過程 | 在無類別標籤的幫助下,根據它們的相似性對數據進行分組 |
| 因有標籤,故需要訓練集與測試集來驗證創建的模型 | 無需訓練集和測試集 |
| 邏輯回歸、SVM等 | k-means、Gaussian (EM)等 |
我們可以先自行從網路上找尋想的要圖片,並將它們個別分類好,整理成一個檔案資料夾,如以下的Gif操作。

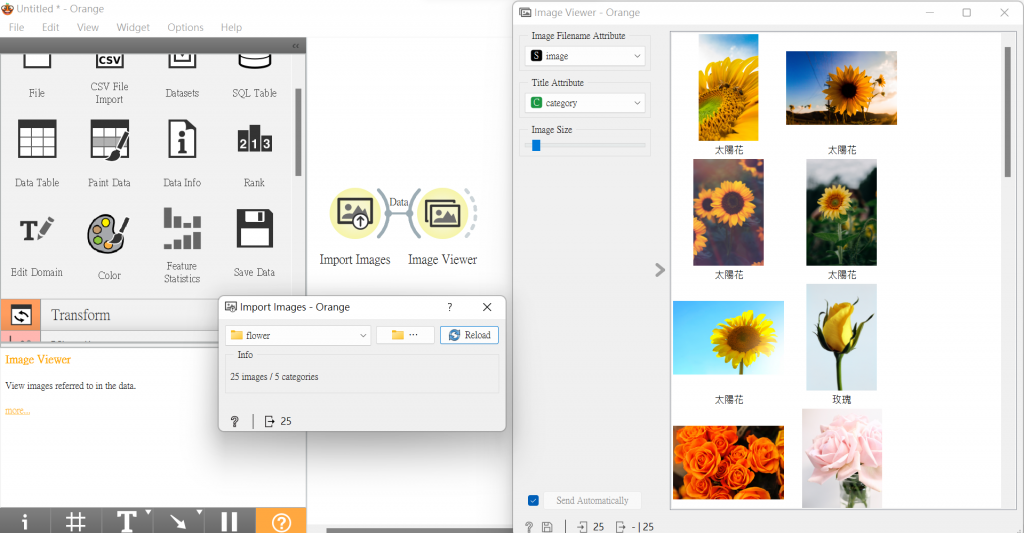
接下來就可以「Import Images」匯入檔案,並將其接上「Image Viewer」,瀏覽圖片是否都匯入成功~
再來,我們在連上「Image Embedding」,把這些圖像轉換成向量,這部分在上個章節也有提到過呦~
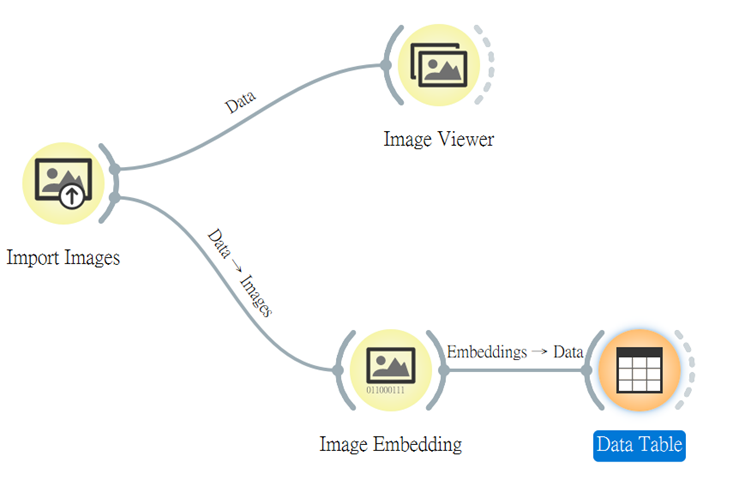
接上「Data Table」,會看到它已增加了另外2048個屬性,供等等後續的操作使用。

完成了數據處理後,接著就是訓練模型及察看其預測的各項比率。而這次我查看的是邏輯迴歸模型來進行評估。
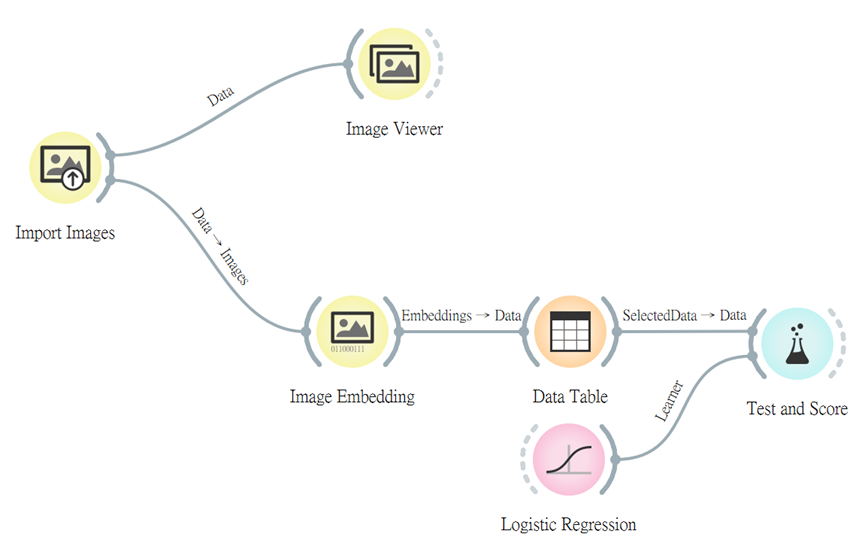
從以下比率來看,此模型準確度算良好地,準確度達到0.8,而AUC之比率至0.984,相當地高呀。(各項評估類別於第十四篇章有詳細的說明)
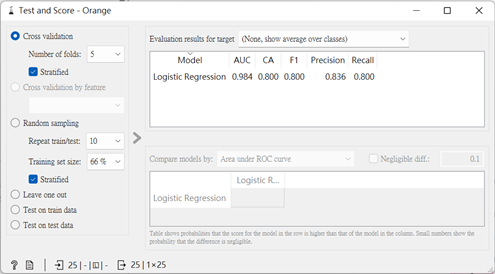
但剩下不到100%的準確率是誤判於何處呢?我們來看看吧~
將「Test and Score」與「Confusion Matrix(混淆矩陣)」接上,查看總共有幾個類別是被誤判的,而在將其連上「Image Viewer」,對照著混淆矩陣,來瀏覽為哪些圖片。
看起來,有些圖片真的與其它類別有相似之處,所以造成誤判,若先前給出更多的數據,讓機器學習時,有更多內容可依循判別,那麼準確率也可能會變高喔!

圖片的實作就先告一段落啦,明日將有新主題,敬請期待啦!
參考資料:
Orange
ML | Classification vs Clustering

